
建立單鏈表的頭插法與尾插法詳解
建立單鏈表
關於資料結構的入門,就是從順序表和單鏈表開始。 我們不講順序表,直接從單鏈表開始我們的資料結構和演算法的學習之路。
單鏈表就是一種特殊的結構體組合而成的資料結構,關於單鏈表的建立方法有很多種,但都大同小異。

正如這幅圖中所表示的那樣,單鏈表就是由可能不連續的資料所組合而成的資料結構。 其中每個資料分為兩部分,一部分是資料儲存的位置,稱為資料域,另外指標所儲存的地方,稱為指標域。
typedef struct Node { int data; // 儲存連結串列資料 struct Node *next; // 儲存結點的地址 }LNode,*Linklist;
在進入建立連結串列之前,我們先寫好主函式的用來輸出的輸出函式。
void Illustrate(Linklist head) { Linklist tem = head; // 將頭指標的地址賦給臨時的指標 while (tem->next != NULL) { // 指向最後一個結點的指標域時會停止 tem = tem->next; // 結點不斷向後移動 printf("%d\n", tem->data); } } int main() { Linklist head = NULL; // 連結串列的頭指標 head = Creat_list(head); // 建立連結串列 Illustrate(head); // 輸出每個結點的資料域 system("pause"); return 0; }
頭插法建立單鏈表
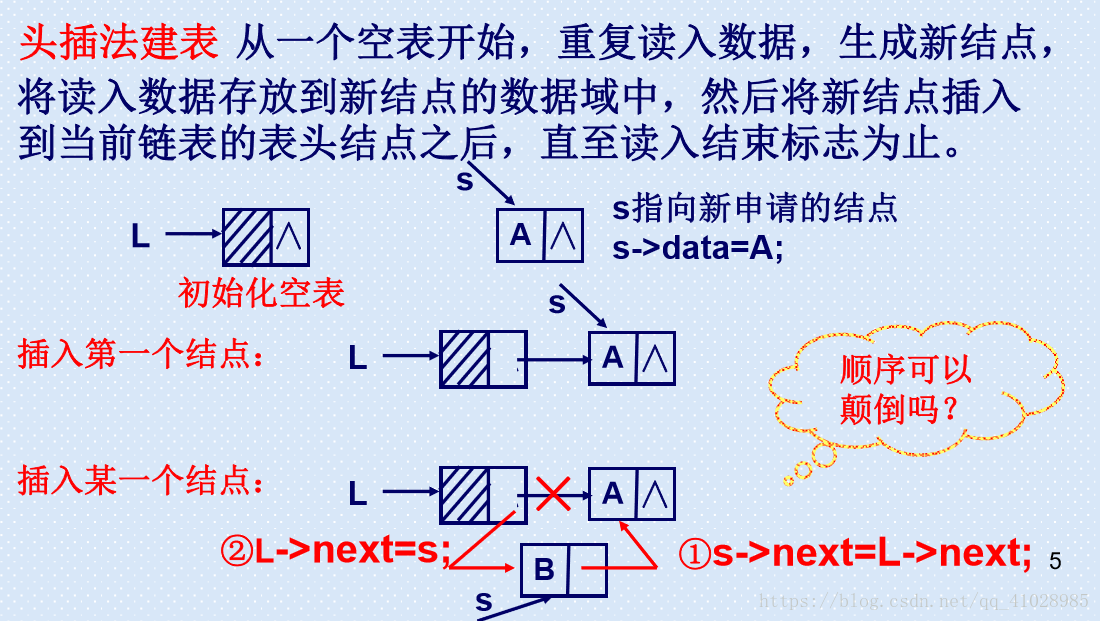
頭插法程式碼:
Linklist Creat_list(Linklist head) { head = (Linklist)malloc(sizeof(Lnode)); // 為頭指標開闢記憶體空間 Lnode *node = NULL; // 定義新結點 int count = 0; // 建立結點的個數 head->next = NULL; node = head->next; // 將最後一個結點的指標域永遠保持為NULL printf("Input the node number: "); scanf("%d", &count); for (int i = 0; i < count; i++) { node = (Linklist)malloc(sizeof(Lnode)); // 為新結點開闢記憶體空間 node->data = i; // 為新結點的資料域賦值 node->next = head->next; // 將頭指標所指向的下一個結點的地址,賦給新建立結點的next head->next = node; // 將新建立的結點的地址賦給頭指標的下一個結點 } return head; }
頭插法建立連結串列的根本在於深刻理解最後兩條語句
node->next = head->next; // 將頭指標所指向的下一個結點的地址,賦給新建立結點的next
head->next = node; // 將新建立的結點的地址賦給頭指標的下一個結點
建立第一個結點
執行第一次迴圈時,第一次從堆中開闢一塊記憶體空間給node,此時需要做的是將第一個結點與 head 連線起來。而我們前面已經說過,單鏈表的最後一個結點指向的是 NULL。
因此插入第一個結點時,我們需要將頭指標指向的 next 賦給新建立的結點的 next , 這樣第一個插入的結點的 next 指向的就是 NULL。 接著,我們將資料域,也就是 node 的地址賦給 head->next, 這時 head->next 指向的就是新建立的 node的地址。而 node 指向的就是 NULL。
接著我們建立第二個結點
因為使用的頭插法,因此新開闢的記憶體空間需要插入 頭指標所指向的下一個地址,也就是新開闢的 node 需要插入 上一個 node 和 head 之間。 第一個結點建立之後,head->next 的地址是 第一個 node 的地址。 而我們申請到新的一塊儲存區域後,需要將 node->next 指向 上一個結點的首地址, 而新node 的地址則賦給 head->next。 因此也就是 node->next = head->next 。 這樣便將第一個結點的地址賦給了新建立地址的 next 所指向的地址。後兩個結點就連線起來。
接下來再將頭結點的 next 所指向的地址賦為 新建立 node 的地址。 head->next = node ,這樣就將頭結點與新建立的結點連線了起來。 此時最後一個結點,也就是第一次建立的結點的資料域為0,指標域為 NULL。
建立更多的結點也就不難理解。
執行一次:
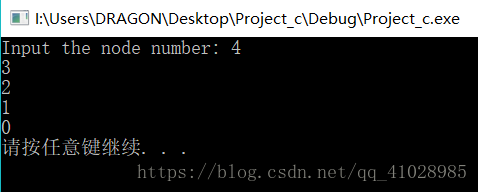
會發現,頭插法建立連結串列時候,就相當於後來居上。 後面的結點不斷往前插,而最後建立的結點在第一個結點處, 第一個建立的結點變成了尾結點。
尾插法建立單鏈表
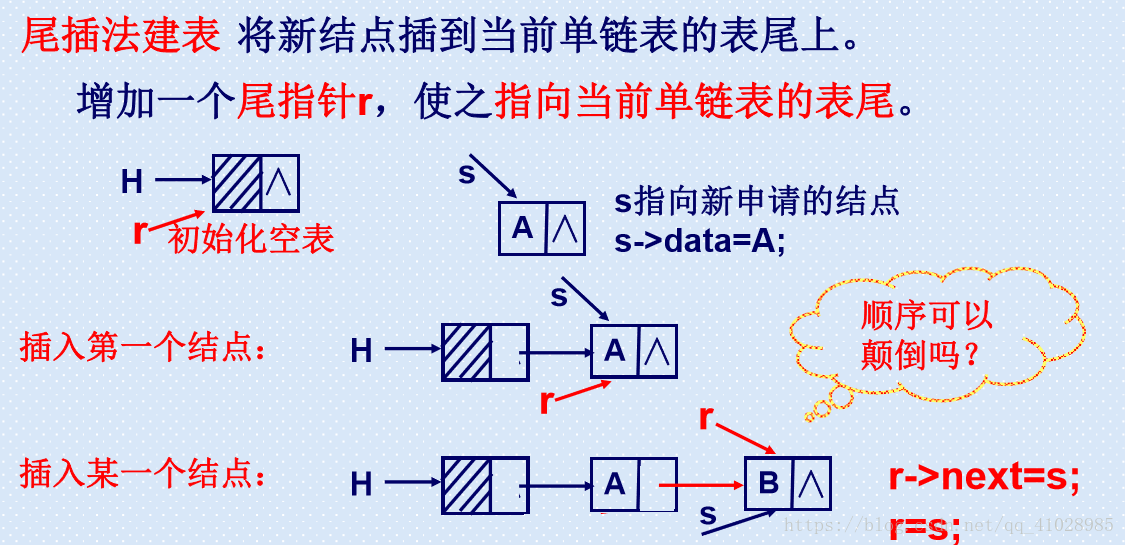
尾插法程式碼:
Linklist Creat_list(Linklist head) {
head = (Linklist)malloc(sizeof(Lnode)); // 為頭指標開闢記憶體空間
Linklist node = NULL; // 定義結點
Linklist end = NULL; // 定義尾結點
head->next = NULL; // 初始化頭結點指向的下一個地址為 NULL
end = head; // 未建立其餘結點之前,只有一個頭結點
int count = 0 ; // 結點個數
printf("Input node number: ");
scanf("%d", &count);
for (int i = 0; i < count; i++) {
node = (Linklist)malloc(sizeof(Lnode)); // 為新結點開闢新記憶體
node->data = i; // 新結點的資料域賦值
end->next = node;
end = node;
}
end->next = NULL;
}
尾插法深刻理解:
end->next = node;
end = node;
尾插法建立第一個結點
剛開始為頭結點開闢記憶體空間,因為此時除過頭結點沒有新的結點的建立,接著將頭結點的指標域 head->next 的地址賦為 NULL。因此此時,整個連結串列只有一個頭結點有效,因此 head此時既是頭結點,又是尾結點。因此將頭結點的地址賦給尾結點 end 因此:end = head。 此時end 就是 head, head 就是 end。 end->next 也自然指向的是 NULL。
尾插法建立第二個結點
建立完第一個結點之後,我們入手建立第二個結點。 第一個結點,end 和 head 共用一塊記憶體空間。現在從堆中心開闢出一塊記憶體給 node,將 node 的資料域賦值後,此時 end 中儲存的地址是 head 的地址。此時,end->next 代表的是頭結點的指標域,因此 end->next = node 代表的就是將上一個,也就是新開闢的 node 的地址賦給 head 的下一個結點地址。
此時,end->next 的地址是新建立的 node 的地址,而此時 end 的地址還是 head 的地址。 因此 end = node ,這條作用就是將新建的結點 node 的地址賦給尾結點 end。 此時 end 的地址不再是頭結點,而是新建的結點 node。
一句話,相當於不斷開創新的結點,然後不斷將新的結點的地址當做尾結點。尾結點不斷後移,而新創的結點時按照建立的先後順序而連線的。先來新到。
尾插法建立單鏈表,結點建立完畢
最後,當結點建立完畢,最後不會有新的結點來替換 end ,因此最後需要加上一條 end->next = NULL。將尾指標的指向為 NULL。
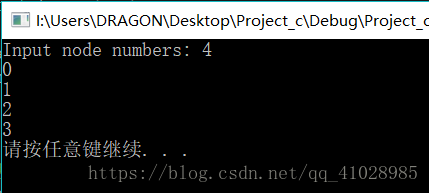
建立更多結點也自然容易理解了一些。
執行一次:
總結
由上面的例子以及比較,我們可以看見:
- 頭插法相對簡便,但插入的資料與插入的順序相反;
- 尾插法操作相對複雜,但插入的資料與插入順序相同。
兩種建立的方法各有千秋,根據實際情況選擇不同的方法。
關於連結串列的相關其他操作,請瀏覽相關文件。