
Spark專案實戰-資料傾斜解決方案之將reduce join轉換為map join
阿新 • • 發佈:2018-12-12
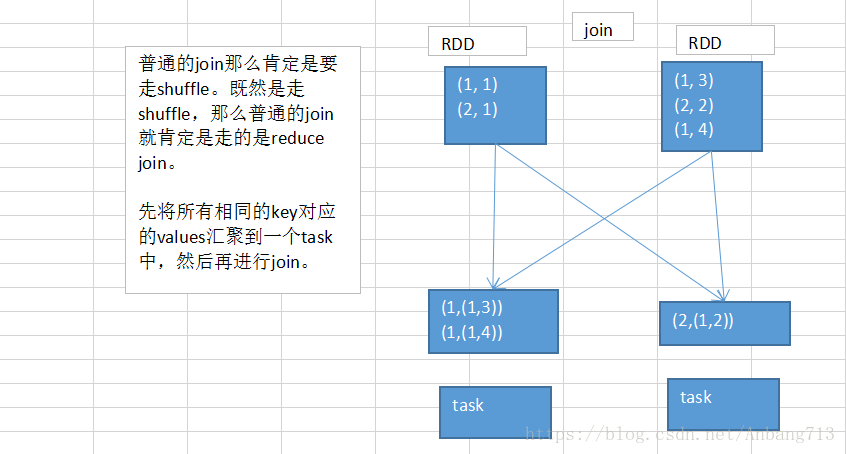
一、reduce端join操作原理
二、map端join操作原理

三、適用場景
如果兩個RDD要進行join,其中一個RDD是比較小的。一個RDD是100萬資料,一個RDD是1萬資料。(一個RDD是1億資料,一個RDD是100萬資料) 其中一個RDD必須是比較小的,broadcast出去那個小RDD的資料以後,就會在每個executor的block manager中都駐留一份。要確保你的記憶體足夠存放那個小RDD中的資料 這種方式下,根本不會發生shuffle操作,肯定也不會發生資料傾斜。從根本上杜絕了join操作可能導致的資料傾斜的問題,對於join中有資料傾斜的情況,大家儘量第一時間先考慮這種方式。
不適合的情況:兩個RDD都比較大,那麼這個時候,你去將其中一個RDD做成broadcast就很笨拙了。很可能導致記憶體不足,最終導致記憶體溢位,程式掛掉。 而且其中某些key(或者是某個key)還發生了資料傾斜。
四、其它說明
對於join這種操作不光是考慮資料傾斜的問題,即使是沒有資料傾斜問題,也完全可以優先考慮將reduce join轉map join的技術,不要用普通的join去通過shuffle進行資料的join。完全可以通過簡單的map,使用map join的方式,犧牲一點記憶體資源。在可行的情況下,不走shuffle直接走map效能肯定是能得到提升的。