
DRF之解析器元件及序列化元件
引入
Django RestFramework幫助我們實現了處理application/json協議請求的資料,另外,我們也提到,如果不使用DRF,直接從request.body裡面拿到原始的客戶端請求的位元組資料,經過decode,然後json反序列化之後,也可以得到一個Python字典型別的資料。
但是,這種方式並不被推薦,因為已經有了非常優秀的第三方工具,那就是Django RestFramework的解析器元件,這是我們今天要學習的第一個非常重要的知識點,咱們今天要學習的另一個也是至關重要的知識點叫做序列化元件。
序列化在上一節課中也已經提到了,幫助我們快速的進行符合規範的介面開發,也就是增刪改查介面,包含錯誤資訊定義,成功之後的返回資訊定義等等。
接下來,咱們就開始學習DRF的這兩個重要元件。
今日概要
- 解析器元件的使用及原始碼剖析
- 序列化元件的使用及RESTful介面設計
知識點複習回顧
- 昨日回顧
- 三元運算
- 列表推導式
- getattr
- Django settings檔案查詢順序
- 動態import
- Django原生serializer
知識點複習回顧一:三元運算
三元運算能夠簡化我們的程式碼,請看如下程式碼:
1 |
# 定義兩個變數 |
知識點複習回顧二:列表推導式
列表推導式的返回結果仍然是一個列表,假設有列表li = [1, 2, 3, 4], 請同學們思考,如果將li列表裡面的每一個元素乘以2得到一個新的列表,請看下面的程式碼:
1 |
li = [1, 2, 3, 4] |
可見,列表推導式能夠大大簡化程式碼,再看下面的程式碼:
1 |
class JsonParser(object): |
可以看到,parser_list是parser_classes中每個類的例項化物件列表。以上就是關於列表推導式的回顧。
知識點複習回顧三:getattr
在學習面向物件時,我們知道可以通過物件加點號獲取該物件的屬性,也可以通過物件的dict訪問屬性,請看下面的程式碼:
1 |
class Father(object): |
物件的屬性查詢首先會在該物件的一個名為dict的字典中查詢這個屬性,如果找不到,則會到其父類中查詢這個屬性,如果在父類中都也找不到對應的屬性,這會丟擲異常AttributeError,我們可以通過在類中定義一個getattr來重定向未查詢到屬性後的行為,請看下面的程式碼:
1 |
class Father(object): |
可以看到,我們能夠重新定義異常,也可以做其他任何事情,這就是getattr,一句話總結,通過物件查詢屬性,如果找不到屬性,且該物件有getattr方法,那麼getattr方法會被執行,至於執行什麼邏輯,我們可以自定義。
知識點複習回顧四:Django settings檔案查詢順序
同學們在使用Django的時候,應該是經常會用到它的settings檔案,通過在settings檔案裡面定義變數,我們可以在程式的任何地方使用這個變數,方便好用,比如,假設我在settings裡面定義了一個變數NAME=”Pizza”, 雖然可以在專案的任何地方使用:
1 |
>>> from drf_server import settings |
但是,這種方式並不是被推薦和建議的,因為除了專案本身的settings檔案之外,Django程式本身也有許多配置變數,都儲存在django/conf/global_setting.py模組裡面,包括快取、資料庫、祕鑰等,如果我們只是from drf_server import settings匯入了專案本身的配置資訊,當需要用到Django預設的配置資訊的時候,還需要再次匯入,from django.conf import settings,所以建議的使用方式是:
1 |
>>> from django.conf import settings |
使用上面的方式,我們除了可以使用自定義的配置資訊(NAME)外,還可以使用global_settings中的配置資訊,不需要重複匯入,Django查詢變數的順序是先從使用者的settings裡面查詢,然後在global_settings中查詢,如果使用者的settings中找到了,則不會繼續查詢global_settings中的配置資訊,假設我在使用者的settings裡面定義了NAME=”Pizza”, 在global_settings中定義了NAME=”Alex”,請看下面的列印結果:
1 |
>>> from django.conf import settings |
可見,這種方式更加靈活高效,建議大家使用。
知識點複習回顧五:Django原生serializer
上一節課講到,我們可以自定義符合REST規範的介面,請看下面的程式碼:
1 |
from django.db import models |
1 |
class CoursesView(View): |
通過上面的方式,我們定義出了符合規範的返回資料,加上符合規範的url,我們可以說,手動方式進行REST開發也是完全沒有問題的,但是,企業最注重的是開發效率,而不是程式設計師實現需求的方式,理論上來說,我們可以通過任何方式,但是我們應該儘可能的採用高效的、靈活的、強大的工具來幫助我們完成重複的事情,所以我們需要學習DRF,它提供了很多的功能,在講DRF的序列化之前,我們來了解另一個知識,那就是,Django框架原生的序列化功能,即Django原生serializer,它的使用方式如下:
1 |
from django.core.serializers import serialize |
使用方式非常簡單,匯入模組之後,將需要的格式和queryset傳給serialize進行序列化,然後返回序列化後的資料。
如果你的專案僅僅只是需要序列化一部分資料,不需要用到諸如認證、許可權等等其他功能,可以使用Django原生serializer,否則建議使用DRF。
今日詳細
好了,接下來,鋪墊都做好了,剖析原始碼所需要的準備工作都已經做好了,接下來,我們就進入今天的新內容的學習,也就是解析器元件和序列化元件的使用及其原始碼剖析。
解析器元件
解析器元件的使用
首先,來看看解析器元件的使用,稍後我們一起剖析其原始碼:
1 |
from django.http import JsonResponse |
使用方式非常簡單,分為如下兩步:
- from rest_framework.views import APIView
- 繼承APIView
- 直接使用request.data就可以獲取Json資料
如果你只需要解析Json資料,不允許任何其他型別的資料請求,可以這樣做:
- from rest_framework.parsers import JsonParser
- 給檢視類定義一個parser_classes變數,值為列表型別[JsonParser]
- 如果parser_classes = [], 那就不處理任何資料型別的請求了
問題來了,這麼神奇的功能,DRF是如何做的?因為昨天講到Django原生無法處理application/json協議的請求,所以拿json解析來舉例,請同學們思考一個問題,如果是你,你會在什麼地方加入新的Json解析功能?
首先,需要明確一點,我們肯定需要在request物件上做文章,為什麼呢?因為只有有了使用者請求,我們的解析才有意義,沒有請求,就沒有解析,更沒有處理請求的邏輯,所以,我們需要弄明白,在整個流程中,request物件是什麼時候才出現的,是在繫結url和處理檢視之間的對映關係的時候嗎?我們來看看原始碼:
1 |
|
看到了嗎?在執行view函式的時候,那麼什麼時候執行view函式呢?當然是請求到來,根據url查詢對映表,找到檢視函式,然後執行view函式並傳入request物件,所以,如果是我,我可以在這個檢視函式裡面加入處理application/json的功能:
1 |
|
看到了吧,然後我們試試傳送json請求,看看返回結果如何?是不是非常神奇?事實上,你可以在這裡,也可以在這之後的任何地方進行功能的新增。
那麼,DRF是如何做的呢?我們在使用的時候只是繼承了APIView,然後直接使用request.data,所以,我斗膽猜測,功能肯定是在APIView中定義的,廢話,具體在哪個地方呢?接下來,我們一起來分析一下DRF解析器原始碼,看看DRF在什麼地方加入了這個功能,上節課,我們通過面向物件的方式,給類的某個方法新增了功能,呼叫重寫的方法,就實現了功能擴充套件,但是上面除了request.data,我們沒有呼叫任何新的方法,所以,問題就在這個request.data上,它絕不僅僅是一個普通的物件屬性。
好了,有了這個共同的認識,我們接下來驗證一下我們的看法。
解析器元件原始碼剖析
請看下圖:
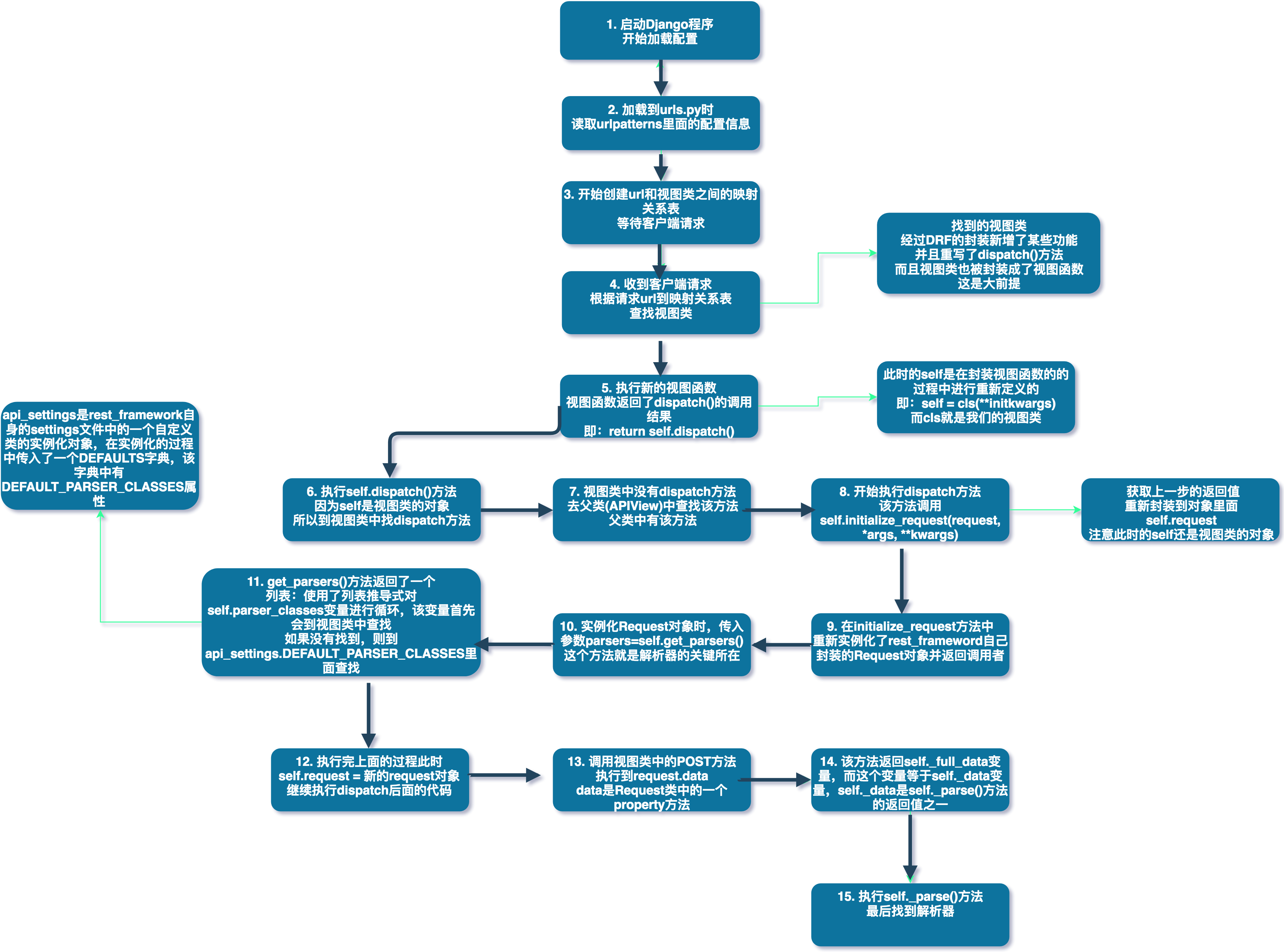
上圖詳細描述了整個過程,最重要的就是重新定義的request物件,和parser_classes變數,也就是我們在上面使用的類變數。好了,通過分析原始碼,驗證了我們的猜測。
序列化元件
序列化元件的使用
定義幾個 model:
1 |
from django.db import models |
通過序列化元件進行GET介面設計
首先,設計url,本次我們只設計GET和POST兩種介面:
1 |
from django.urls import re_path |
我們新建一個名為app_serializers.py的模組,將所有的序列化的使用集中在這個模組裡面,對程式進行解耦:
1 |
# -*- coding: utf-8 -*- |
接著,使用序列化元件,開始寫檢視類:
1 |
# -*- coding: utf-8 -*- |
如此簡單,我們就已經,通過序列化元件定義了一個符合標準的介面,定義好model和url後,使用序列化元件的步驟如下:
- 匯入序列化元件:from rest_framework import serializers
- 定義序列化類,繼承serializers.Serializer(建議單獨建立一個專用的模組用來存放所有的序列化類):class BookSerializer(serializers.Serializer):pass
- 定義需要返回的欄位(欄位型別可以與model中的型別不一致,引數也可以調整),欄位名稱必須與model中的一致
- 在GET介面邏輯中,獲取QuerySet
- 開始序列化:將QuerySet作業第一個引數傳給序列化類,many預設為False,如果返回的資料是一個列表巢狀字典的多個物件集合,需要改為many=True
- 返回:將序列化物件的data屬性返回即可
上面的介面邏輯中,我們使用了Response物件,它是DRF重新封裝的響應物件。該物件在返回響應資料時會判斷客戶端型別(瀏覽器或POSTMAN),如果是瀏覽器,它會以web頁面的形式返回,如果是POSTMAN這類工具,就直接返回Json型別的資料。
此外,序列化類中的欄位名也可以與model中的不一致,但是需要使用source引數來告訴元件原始的欄位名,如下:
1 |
class BookSerializer(serializers.Serializer): |
下面是通過POSTMAN請求該介面後的返回資料,大家可以看到,除ManyToManyField欄位不是我們想要的外,其他的都沒有任何問題:
1 |
[ |
那麼,多對多欄位如何處理呢?如果將source引數定義為”authors.all”,那麼取出來的結果將是一個QuerySet,對於前端來說,這樣的資料並不是特別友好,我們可以使用如下方式:
1 |
class BookSerializer(serializers.Serializer): |
請注意,get_必須與欄位名稱一致,否則會報錯。
通過序列化元件進行POST介面設計
接下來,我們設計POST介面,根據介面規範,我們不需要新增url,只需要在檢視類中定義一個POST方法即可,序列化類不需要修改,如下:
1 |
# -*- coding: utf-8 -*- |
POST介面的實現方式,如下:
- url定義:需要為post新增url,因為根據規範,url定位資源,http請求方式定義使用者行為
- 定義post方法:在檢視類中定義post方法
- 開始序列化:通過我們上面定義的序列化類,建立一個序列化物件,傳入引數data=request.data(application/json)資料
- 校驗資料:通過例項物件的is_valid()方法,對請求資料的合法性進行校驗
- 儲存資料:呼叫save()方法,將資料插入資料庫
- 插入資料到多對多關係表:如果有多對多欄位,手動插入資料到多對多關係表
- 返回:將插入的物件返回
請注意,因為多對多關係欄位是我們自定義的,而且必須這樣定義,返回的資料才有意義,而使用者插入資料的時候,serializers.Serializer沒有實現create,我們必須手動插入資料,就像這樣:
1 |
# 第二步, 建立一個序列化類,欄位型別不一定要跟models的欄位一致 |
這樣就會非常複雜化程式,如果我希望序列化類自動插入資料呢?
這是問題一:如何讓序列化類自動插入資料?
另外問題二:如果欄位很多,那麼顯然,寫序列化類也會變成一種負擔,有沒有更加簡單的方式呢?
答案是肯定的,我們可以這樣做:
1 |
class BookSerializer(serializers.ModelSerializer): |