
從零開始搭建django前後端分離專案 系列六(實戰之聚類分析)
阿新 • • 發佈:2018-12-11
專案需求
本專案從impala獲取到的資料為使用者地理位置資料,每小時的資料量大概在8000萬條,資料格式如下:

公司要求對這些使用者按照聚集程度進行劃分,將300米範圍內使用者數大於200的使用者劃分為一個簇,並計算這個簇的中心點和簇的邊界點。
實現原理
下面我們來一步一步實現上述需求:
1、將使用者按照聚集程度進行劃分
我們可以選擇基於密度的聚類演算法DBscan演算法,DBSCAN演算法的重點是選取的聚合半徑引數eps和聚合所需指定的數目min_samples,正好對應這裡的300米和200個使用者。但是需要注意的是,dbscan演算法的預設距離度量為歐幾里得距離,而我們需要的是球面距離,所以需要定製我們自己的距離演算法運用到dbscan演算法中。解決方法是:將dbscan設定為 metric='precomputed' ,這時fit傳入的X引數必須為相似度矩陣,然後fit
2、識別簇的邊界點
這裡我使用凸包演算法來計算簇的邊界點,那麼問題就變成:如何求一個平面內所有點的最小凸邊形。在scipy.spatial 和opencv 分別有計算凸包的函式,不清楚的可以自行百度。
3、計算簇的中心點
由於dbscan演算法中並沒有提到獲取簇中心點的方法,那麼我們就需要自己設計來計算簇的中心點。現在簇的所有點已知,我們可以利用k-means演算法來計算簇的中心點,只需要設定K=1(即質心為1)。
實現程式碼
# -*- coding:utf-8 -*-from math import radians, cos, sin, asin, sqrt,degrees import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import DBSCAN, KMeans from scipy.spatial import ConvexHull from sklearn.cluster import MeanShift, estimate_bandwidth from scipy.spatial.distance import pdist, squareformfrom sklearn import metrics pd.set_option('display.width', 400) pd.set_option('display.expand_frame_repr', False) pd.set_option('display.max_columns', 70) def haversine(lonlat1, lonlat2): lat1, lon1 = lonlat1 lat2, lon2 = lonlat2 lon1, lat1, lon2, lat2 = map(radians, [lon1, lat1, lon2, lat2]) dlon = lon2 - lon1 dlat = lat2 - lat1 a = sin(dlat / 2) ** 2 + cos(lat1) * cos(lat2) * sin(dlon / 2) ** 2 c = 2 * asin(sqrt(a)) r = 6371 # Radius of earth in kilometers. Use 3956 for miles return c * r if __name__=='__main__': df=pd.read_csv('test.csv') print(df.head()) X=df[['mr_longitude','mr_latitude']].values radius = 200 epsilon = radius / 100000 min_samples = 40 # model = DBSCAN(eps=epsilon, min_samples=min_samples) # y_pred = model.fit_predict(X) # # 自定義度量距離 distance_matrix = squareform(pdist(X, (lambda u, v: haversine(u, v)))) db = DBSCAN(eps=300, min_samples=200, metric='precomputed') y_pred = db.fit_predict(distance_matrix) print(y_pred.tolist()) n_clusters_ = len(set(y_pred)) - (1 if -1 in y_pred else 0) # 獲取分簇的數目 print('分簇的數目:',n_clusters_) df['label'] = y_pred df_group = df[df['label'] != -1][['mr_longitude', 'mr_latitude', 'label']].groupby(['label']) plt.figure(facecolor='w') for label, group in df_group: points = group[['mr_longitude', 'mr_latitude']].values # 得到凸輪廓座標的索引值,逆時針畫 hull = ConvexHull(points).vertices.tolist() hull.append(hull[0]) plt.plot(points[hull, 0], points[hull, 1], 'r--^', lw=2) for i in range(len(hull) - 1): plt.text(points[hull[i], 0], points[hull[i], 1], str(i), fontsize=10) plt.scatter(X[:, 0], X[:, 1], c=y_pred,s=4) plt.grid(True) plt.show()
視覺化
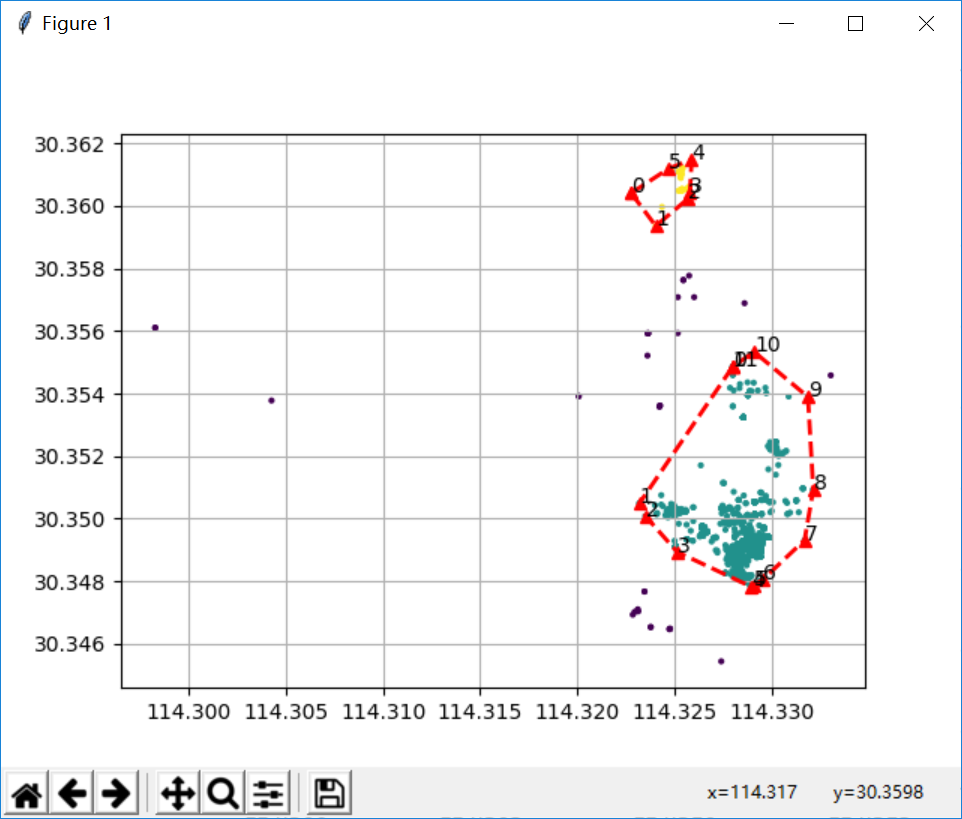
實際專案中的效果圖
