條件隨機場與句法分析
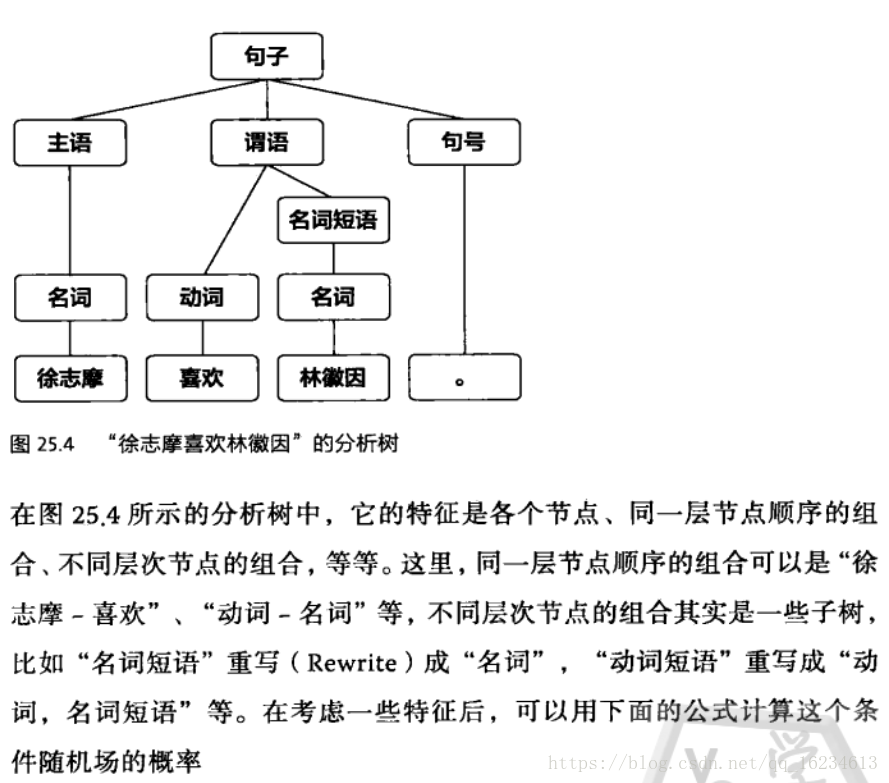
句法分析就是為每個句子建立語法樹。最初的句法分析,受形式語言的影響,使用的是規則方法,不斷使用規則樹從底向上的將樹的末端節點向上合併,直到合併出根節點。當然也可以使用自頂向下的方法。但這種方法不能一次選對,一旦選錯一步,就需要回溯很多步,因此計算複雜度特別高。後來出現在選擇文法規則時,堅持一個原則:讓被分析的句子的語法樹概率達到最大。這方法雖然簡單,卻降低了複雜度,提高了準確度。而且在句法分析和數學之間搭建起了橋樑。
拉納帕提從一個全新的角度看待句法分析,他將句法分析看待成一個闊括號過程。


為了判斷是哪種操作,拉納帕提建立了一個統計模型P(A|prefix);其中A表示採取哪種動作,prefix表示從句子開頭到目前為止所有的詞和語法分析。最終拉納帕提使用最大熵模型來實現這個模型。這種方法速度非常快,每次掃描,句子成分數量就按一定比例減少,因此掃描次數是句子長度的對數函式。
但以上模型對於常規的句子分析效果很好,對於廣大網民隨意書寫的句子準確率不高。所幸的是在自然語言處理中我們一般不需要非常深入那些的考慮句子成分,而只需要對句子做淺層分析,如找出句子中主要片語,分析它們之間的關係。因此隨後的科學家採用了一種新的模型:條件隨機場。
條件隨機場:
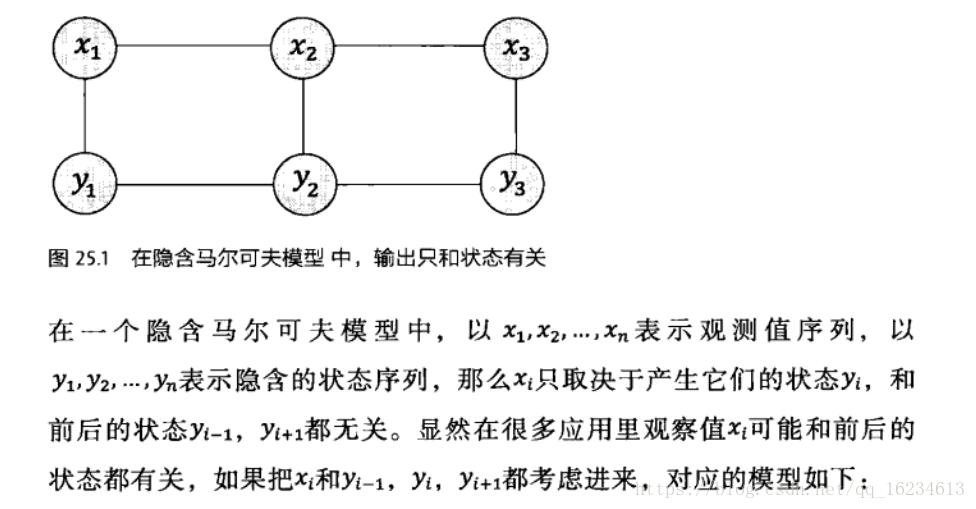
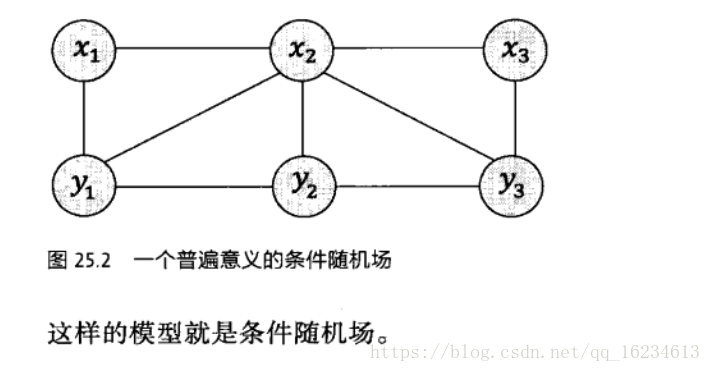
HMM模型基於馬爾科夫假設和獨立輸出假設,但在條件隨機場中,不再做獨立輸出假設,而是認為輸出與前後都有關係。所以可以看成是HMM的一種擴充套件。更廣義的講,條件隨機場是一種特殊的概率圖模型。其特殊性在於變數間遵循馬爾科夫假設,這一點和前面介紹到的貝葉斯網路相同,不同在於條件隨機場是無向圖,而貝葉斯網路是有向圖。

由於模型引數很多,沒有足夠資料來直接估計。因此只能使用一些邊緣分佈,如P(X1),P(Y2),P(X1,Y3)來找出符合這些條件的概率分佈函式。當然這種函式不可能只有一個。因此根據最大熵原則,我們希望找到一個符合所有邊緣分佈,且熵達到最大的模型。前面介紹過,這個模型就是指數函式,每一個邊緣分佈對應指數函式中的一個特徵fi。比如針對x1的邊緣分佈特徵就是:

以句法分析為例:
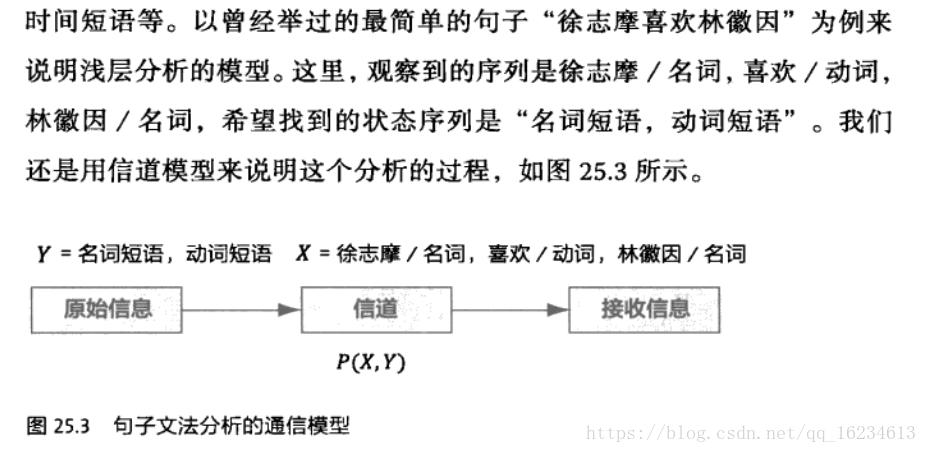
假設X代表所看到的東西,在淺層分析中是句子中的詞、詞性等;Y代表要推導的東西,它是語法成分,如名詞短語,動詞短語等。