
oracle------分析函式和開窗函式over( )
一 什麼是分析函式
1 概念
分析函式是Oracle專門用於解決複雜報表統計需求的功能強大的函式,它可以在資料中進行分組然後計算基於組的某種統計值,並且每一組的每一行都可以返回一個統計值。
2 和聚合函式的區別
普通的聚合函式用group by分組,每個分組返回一個統計值,而分析函式採用partition by分組,並且每組每行都可以返回一個統計值。
3 開窗函式
開窗函式指定了函式所能影響的視窗範圍,也就是說在這個視窗範圍中都可以受到函式的影響,有些分析函式就是開窗函式。
4 分析函式語法
function_name (<argument>,<argument>...) -----1 over -----2 (<Partition-Clause> -----3 <Order-by-Clause> -----4 <Windowing-Clause>) -----5
語法解釋:
1. function_name:對視窗中的資料進行操作,Oracle常用的分析函式有(這裡就列舉了一些常用的,其實有很多)
① 聚合函式
sum:一個組中資料累積和
min:一個組中資料最小值
max:一個組中資料最大值
avg:一個組中資料平均值
count:一個組中資料累積計數
② 排名函式
row_number( ):返回一個唯一的值,當碰到相同資料時,排名按照記錄集中記錄的順序依次遞增。
rank( ):返回一個唯一的值,當碰到相同的資料時,此時所有相同資料的排名是一樣的,同時會在最後一條相同記錄和下一條不同記錄的排名之間空出排名。
dense_rank( ):返回一個唯一的值,當碰到相同資料時,此時所有相同資料的排名都是一樣的,同時會在最後一條相同記錄和下一條不同記錄的排名之間緊鄰遞增。
2. over:關鍵字,用於標識分析函式
3. Partition-Clause:分割槽子句,根據分割槽表示式的條件邏輯將單個結果集分成N組
格式: partition by......
4. Order-by-Clause:排序子句,用於對分割槽中的資料進行排序
格式:order by......
5. Windowing-Clause:視窗子句,用於定義function在其上操作的行的集合,即function所影響的範圍
格式:
order by 欄位名 range|rows between 邊界規則1 AND 邊界規則2邊界規則的取值如下表所示:
注意:RANGE表示按照值的範圍進行範圍的定義,而ROWS表示按照行的範圍進行範圍的定義
可取值 說明 CURRENT ROW 當前行 N PRECEDING 前N行 UNBOUNDED PRECEDING 一直到第一條記錄 N FOLLOWING 後N行 UNBOUNDED FOLLOWING 一直到最後一條記錄
二 分析函式和開窗函式例項
1 建立表格並插入資料
--建立表格
create table student
( name varchar2(20),
city varchar2(20),
age int,
salary int )--插入資料
INSERT INTO student(name,city,age,salary)
VALUES('Kebi','JiangSu',20,3000);
INSERT INTO student(name,city,age,salary)
VALUES('James','ChengDu',21,4000);
INSERT INTO student(name,city,age,salary)
VALUES('Denglun','BeiJing',22,3500);
INSERT INTO student(name,city,age,salary)
VALUES('Yangmi','London',21,2500);
INSERT INTO student(name,city,age,salary)
VALUES('Nana','NewYork',22,1000);
INSERT INTO student(name,city,age,salary)
VALUES('Sunli','BeiJing',20,3000);
INSERT INTO student(name,city,age,salary)
VALUES('Dengchao','London',22,1500);
INSERT INTO student(name,city,age,salary)
VALUES('Huge','JiangSu',20,2800);
INSERT INTO student(name,city,age,salary)
VALUES('Pengyuyan','BeiJing',24,4500);
INSERT INTO student(name,city,age,salary)
VALUES('Baoluo','London',25,8500);
INSERT INTO student(name,city,age,salary)
VALUES('Huting','ChengDu',25,3000);
INSERT INTO student(name,city,age,salary)
VALUES('Hurenxiang','JiangSu',23,2500);
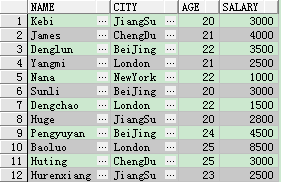
表格建立完後,查看錶格中的內容
select * from student
2 聚合函式和開窗函式
① 單一的聚合函式count
案例:如果要求出student表中一共多少人
select count(name) from student得到的結果
從上表中看出,得到的結果是一個值,即為student表中一共12個人

② 聚合函式count和開窗函式over( )的聯合使用
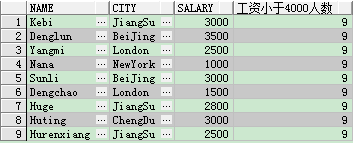
案例:如果查詢每個工資小於4000元的員工資訊(姓名,城市以及工資),並在每行中都顯示所有工資小於4000元的員工個數
第一種實現方式:通過子查詢實現
select name , city , salary , (select count(salary) from student where salary < 4000) 工資小於4000人數 from student where salary < 4000
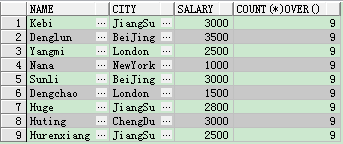
第二種實現方式:開窗函式over( )實現
select name , city , salary ,count(*) over () from student where salary < 4000
解釋一下:開窗函式count(*)over( )是對查詢結果的每一行都返回所有符合條件行的條數;
over關鍵字後的括號中的選項為空,則開窗函式會對結果集中的所有行進行聚合運算;
over關鍵字後的括號中的選項為不為空,則按照括號中的範圍進行聚合運算。
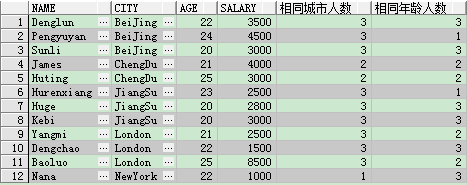
partition by:分割槽子句,根據分割槽表示式的條件邏輯將單個結果集分成N組
案例:查出表中相同城市和相同年齡的人數
select name, city, age, salary, count(*) over(partition by city) 相同城市人數, count(*) over(partition by age) 相同年齡人數 from student
order by子句:排序子句,用於對分割槽中的資料進行排序
① row:按照行定位的
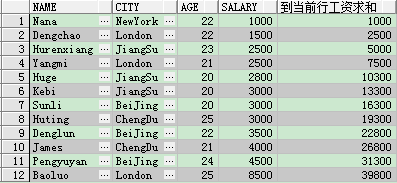
案例:查詢從第一行到當前行的工資總和
select name, city, age, salary, sum(salary) over(order by salary rows between unbounded preceding and current row) 到當前行工資求和 from student
解釋一下:over後面的括號中的unbounded preceding表示第一行,current row表示當前行。上面這段程式碼指的是首先將表中的資料按照salary進行排序,如果不指明是升序還是降序,預設的是升序。然後看到rows這個欄位,說明計算是按照行進行的。就是計算unbounded preceding(第一行)到current row(當前行)的和。比如第一行的salary為1000,第二行的salary為1500,那麼第一行到第二行的和為1000+1500=2500;同理第三行salary為2500,那麼從第一行到第三行的和為1000+1500+2500=5000,以此類推......
② range:按照範圍定位的
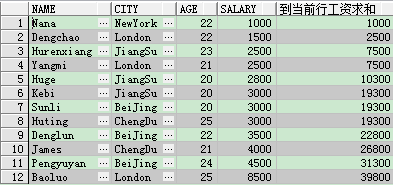
案例:查詢從第一行到當前行的工資總和
select fname, fcity, fage, fsalary, sum(fsalary) over(order by fsalary range between unbounded preceding and current row) 到當前行工資求和 from t_person
解釋一下:range和rows,rows是按照行進行計算的,而range是按照範圍進行計算的。這兩種方式的不同點是處理並列資料的情況,上面第三行和第四行出現了兩個2500,如果是rows就會在第三行顯示1000+1500+2500=5000,第四行顯示1000+1500+2500+2500=7500;如果是range就會在第三行顯示1000+1500+2500+2500=7500,第四行顯示1000+1500+2500+2500=7500,因為第三行和第四行中的salary是一樣的,同時又是按照range進行計算的,所以從第一行開始r無法判斷並列行中的當前行是哪一行,所以直接將並列的數相加。
三 排名函式和分析函式例項
排名函式
row_number( ):返回一個唯一的值,當碰到相同資料時,排名按照記錄集中記錄的順序依次遞增。
rank( ):返回一個唯一的值,當碰到相同的資料時,此時所有相同資料的排名是一樣的,同時會在最後一條相同記錄和下一條不同記錄的排名之間空出排名。
dense_rank( ):返回一個唯一的值,當碰到相同資料時,此時所有相同資料的排名都是一樣的,同時會在最後一條相同記錄和下一條不同記錄的排名之間緊鄰遞增。
select name , city ,age , salary,
row_number()over ( order by salary) as row_number, --按薪水依次排名
rank()over ( order by salary) as rank, --按薪水排名,相同薪水並列
dense_rank()over ( order by salary) as dense_rank --按薪水排名,相同薪水隔幾個排名
from student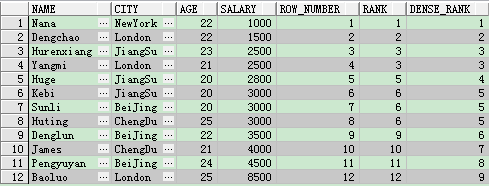
解釋一下:因為row_number,rank,dense_rank在排名時極易混淆,所以在這裡用這個例子給大家區分一下
row_number:不管是否有相同的薪水,都依次按照記錄進行遞增(1,2,3,4.....)
rank:按照薪水進行遞增,遇到相同的薪水時排名一致,只不過遇到不相同的資料時,中間隔出排名,這麼說可能有點抽象,比如上表中第三行和第四行的薪水都是2500,那麼rank進行操作時相同的薪水排名一致都是3,而到了第五行則是5,就隔了一個4。
dense_rank:同樣是按照薪水進行排序,遇到相同的薪水時排名一致,這邊需要和上面的rank進行區分一下,上面的rank遇到相同的資料和不同的資料之間需要隔斷,而這個不一樣,不需要隔斷,第四行和第五行的薪水都是2500,排名都是3,到了第五行不一樣的薪水排名就是4。