
Python遺傳和進化演算法框架(一)Geatpy快速入門
Geatpy是一個高效能的Python遺傳演算法庫以及開放式進化演算法框架,由華南理工大學、華南農業大學、德州奧斯汀公立大學的學生聯合團隊開發。
它提供了許多已實現的遺傳和進化演算法相關運算元的庫函式,如初始化種群、選擇、交叉、變異、重插入、多種群遷移、多目標優化非支配排序等,並且提供開放式的進化演算法框架來實現多樣化的進化演算法。其執行效率高於Matlab遺傳演算法工具箱和Matlab第三方遺傳演算法工具箱Gaot、gatbx、GEATbx,學習成本低。
Geatpy支援二進位制/格雷碼編碼種群、實數值種群、整數值種群、排列編碼種群。支援輪盤賭選擇、隨機抽樣選擇、錦標賽選擇。提供單點交叉、兩點交叉、洗牌交叉、部分匹配交叉(PMX)、線性重組、離散重組、中間重組等重組運算元。提供簡單離散變異、實數值變異、整數值變異、互換變異等變異運算元。支援隨機重插入、精英重插入。支援awGA、rwGA、i-awGA、nsga2、快速非支配排序等多目標優化的庫函式、提供進化演算法框架下的常用進化演算法模板等。
關於遺傳演算法、進化演算法的學習資料,在官網中https://www.geatpy.com (repairing)有詳細講解以及相關的學術論文連結。同時網上也有很多資料。
閒話少說……下面分享一下近幾個星期以來的學習心得:
先說一下安裝方法:
首先是要windows系統,Python要是3.5,3.6或3.7版本 ,並且安裝了pip。只需在控制檯執行
pip install geatpy即可安裝成功。或者到github上下載:https://github.com/geatpy-dev/geatpy 推薦是直接用pip的方式安裝。因為這樣有利於後續的更新。我為了方便執行demo程式碼以及檢視原始碼,因此另外在github上也下載了(但仍用pip方式安裝)。
有些初學Python的讀者反映還是不知道怎麼安裝,或者安裝之後不知道怎麼寫程式碼。這裡推薦安裝Anaconda,它集成了Python的許多常用的執行庫,比如Numpy、Scipy等。其內建的Spyder風格跟Matlab類似,給人熟悉的感覺,更容易上手。
再說一下更新方法:
(注意:專案改組後,Geatpy已於2018.09.20更新至1.0.6版本,新版本解決了一些版權問題。請及時更新。)
Geatpy在持續更新。可以通過以下命令使電腦上的版本與官方最新版保持一致:
pip install --upgrade geatpyGeatpy提供2種方式實現遺傳演算法。先來講一下第一種最基本的實現方式:編寫程式設計指令碼。
1. 編寫指令碼實現遺傳演算法:
用過謝菲爾德大學的Matlab遺傳演算法庫Gatbx以及其升級版——GEATbx的朋友應該非常熟悉下面的Matlab指令碼:
%% matlab_gatbx_test.m
%遺傳演算法求f(x)=x*sin(10*pi*x)+2.0,在[-1,2]上的最大值
figure(1);
fplot(@(variable)variable.*sin(10*pi*variable)+2.0,[-1,2]); %畫出函式曲線
tic %開始計時
%定義遺傳演算法引數
NIND=40; %個體數目(Number of individuals)
MAXGEN=25; %最大遺傳代數(Maximum number of generations)
PRECI=20; %變數的二進位制位數(Precision of variables)
GGAP=0.9; %代溝(Generation gap)說明子代與父代的重複率為0.1
trace=zeros(MAXGEN,2); %尋優結果的初始值
FieldD=[20;-1;2;1;0;1;1]; %區域描述器(Build field descriptor),第2、3行為自變數的下界和上界
Chrom=crtbp(NIND, PRECI); %定義初始種群
gen=0; %代計數器
variable=bs2rv(Chrom, FieldD); %計算初始種群的十進位制轉換
ObjV=shang(variable); %計算目標函式值
while gen<MAXGEN %進化MAXGEN代
FitnV=ranking(-ObjV); %分配適應度值(Assign fitness values)ranking函式的功能就是目標值越小的分配值越大,
%本例求解最大值,應該要是他的適應度值更大,故必須使得ranking內的數越小,這樣分配的適應度值才能大
SelCh=select('sus', Chrom, FitnV, GGAP); %選擇,使用sus方式,也可以改用rws方式
SelCh=recombin('xovsp', SelCh, 0.7); %重組,選用xovsp方式
SelCh=mut(SelCh); %變異
variable=bs2rv(SelCh, FieldD); %子代個體的十進位制轉換,把染色體變為十進位制
ObjVSel=shang(variable); %計運算元代的目標函式值
[Chrom ObjV]=reins(Chrom, SelCh, 1, 1, ObjV, ObjVSel); %重插入子代的新種群
variable=bs2rv(Chrom, FieldD); %子代個體的十進位制轉換,轉為十進位制
gen=gen+1; %代計數器增加
%輸出最優解及其序號,並在目標函式影象中標出,Y為最優解,I為種群的序號
[Y, I]=max(ObjV);hold on;
plot(variable(I), Y, 'ro');
trace(gen,1)=max(ObjV); %遺傳演算法效能跟蹤,把當代的最優值放入trace矩陣的第一行第目前代數列
trace(gen,2)=sum(ObjV)/length(ObjV); %把當代種群目標函式的均值,放入trace矩陣的第二行第目前代數列
end
variable=bs2rv(Chrom, FieldD); %最優個體的十進位制轉換,轉回十進位制,以便輸出
result = max(trace(:,1)) %輸出搜尋到的目標函式最大值
toc %結束計時
hold on;
grid on;
plot(variable,ObjV,'b*');
figure(2);
plot(trace(:,1)); %把trace矩陣的第一列畫出來(記錄的是每一代的最優值)
hold on;
plot(trace(:,2),'-.');grid %把trace矩陣的第2列畫出來(記錄的是每一代種群目標函式均值)
legend('解的變化','種群均值的變化')
function z=shang(x) % 目標函式的核心部分(即缺省了優化目標的純函式)
z=x.*sin(10*pi*x)+2.0;
end這是在Matlab的gatbx工具箱下實現簡單遺傳演算法搜尋f(x)=x*sin(10*pi*x)+2.0,在[-1,2]上的最大值的指令碼程式,執行結果如下:
result =
3.8500
時間已過 0.081932 秒。
再看一下在Geatpy上如何編寫指令碼:
"""demo.py"""
import numpy as np
import geatpy as ga # 匯入geatpy庫
import matplotlib.pyplot as plt
import time
"""============================目標函式============================"""
def aim(x): # 傳入種群染色體矩陣解碼後的基因表現型矩陣
return x * np.sin(10 * np.pi * x) + 2.0
x = np.linspace(-1, 2, 200)
plt.plot(x, aim(x)) # 繪製目標函式影象
start_time = time.time() # 開始計時
"""============================變數設定============================"""
x1 = [-1, 2] # 自變數範圍
b1 = [1, 1] # 自變數邊界
codes = [1] # 變數的編碼方式,2個變數均使用格雷編碼
precisions =[5] # 變數的精度
scales = [0] # 採用算術刻度
ranges=np.vstack([x1]).T # 生成自變數的範圍矩陣
borders=np.vstack([b1]).T # 生成自變數的邊界矩陣
"""========================遺傳演算法引數設定========================="""
NIND = 40; # 種群個體數目
MAXGEN = 25; # 最大遺傳代數
GGAP = 0.9; # 代溝:說明子代與父代的重複率為0.1
"""=========================開始遺傳演算法進化========================"""
FieldD = ga.crtfld(ranges,borders,precisions,codes,scales) # 呼叫函式建立區域描述器
Lind = np.sum(FieldD[0, :]) # 計算編碼後的染色體長度
Chrom = ga.crtbp(NIND, Lind) # 根據區域描述器生成二進位制種群
variable = ga.bs2rv(Chrom, FieldD) #對初始種群進行解碼
ObjV = aim(variable) # 計算初始種群個體的目標函式值
pop_trace = (np.zeros((MAXGEN, 2)) * np.nan) # 定義進化記錄器,初始值為nan
ind_trace = (np.zeros((MAXGEN, Lind)) * np.nan) # 定義種群最優個體記錄器,記錄每一代最優個體的染色體,初始值為nan
# 開始進化!!
for gen in range(MAXGEN):
FitnV = ga.ranking(-ObjV) # 根據目標函式大小分配適應度值(由於遵循目標最小化約定,因此最大化問題要對目標函式值乘上-1)
SelCh=ga.selecting('sus', Chrom, FitnV, GGAP) # 選擇
SelCh=ga.recombin('xovsp', SelCh, 0.7) # 重組(採用單點交叉方式,交叉概率為0.7)
SelCh=ga.mutbin(SelCh) # 二進位制種群變異
variable = ga.bs2rv(SelCh, FieldD) # 對育種種群進行解碼(二進位制轉十進位制)
ObjVSel = aim(variable) # 求育種個體的目標函式值
[Chrom,ObjV] = ga.reins(Chrom,SelCh,SUBPOP,2,1,ObjV,ObjVSel) # 重插入得到新一代種群
# 記錄
best_ind = np.argmax(ObjV) # 計算當代最優個體的序號
pop_trace[gen, 0] = ObjV[best_ind] # 記錄當代種群最優個體目標函式值
pop_trace[gen, 1] = np.sum(ObjV) / ObjV.shape[0] # 記錄當代種群的目標函式均值
ind_trace[gen, :] = Chrom[best_ind, :] # 記錄當代種群最優個體的變數值
# 進化完成
end_time = time.time() # 結束計時
"""============================輸出結果及繪圖================================"""
print('目標函式最大值:',np.max(pop_trace[:, 0])) # 輸出目標函式最大值
variable = ga.bs2rv(ind_trace, FieldD) # 解碼得到表現型
print('用時:', end_time - start_time)
plt.plot(variable, aim(variable),'bo')
執行結果如下:
目標函式最大值: 3.850273756279405 用時: 0.0509946346282959

對比發現,Geatpy的執行效率要高於Matlab,而且結果較好。
對比Matlab程式碼和Python程式碼,我們會發現Geatpy提供風格極為相似的庫函式,有Matlab相關程式設計經驗的基本上可以無縫轉移到Python上利用Geatpy進行遺傳演算法程式開發。
Geatpy提供了詳盡的API文件,比如要檢視上面程式碼中的"ranking"函式是幹什麼的,可以在python中執行
import geatpy as ga
help(ga.ranking)即可看到"ranking"函式的相關使用方法。另外也可以參見github上面的文件:
另外官網上也有更多詳盡的Geatpy教程,Geatpy官網http:www.geatpy.com將於九月初重新上線。
2. 利用框架實現遺傳演算法。
Geatpy提供開放的進化演算法框架。即“函式介面”+“進化演算法模板”。對於一些複雜的進化演算法,如多目標進化優化、改進的遺傳演算法等,利用上面所說的編寫指令碼是非常麻煩的,改用框架的方法可以極大提高程式設計效率。
這裡給出一個利用框架實現NSGA-II演算法求多目標優化函式ZDT-1的帕累託前沿面的例子:
首先編寫函式介面檔案:
""" aimfuc.py """
# ZDT1
def aimfuc(Chrom):
ObjV1 = Chrom[:, 0]
gx = 1 + (9 / 29) * np.sum(Chrom[:, 1:30], 1)
hx = 1 - np.sqrt(ObjV1 / gx)
ObjV2 = gx * hx
return np.array([ObjV1, ObjV2]).T然後編寫指令碼,使用Geatpy提供的nsga2演算法的進化演算法模板(nsga2_templet):
"""main.py"""
import numpy as np
import geatpy as ga # 匯入geatpy庫
# 獲取函式介面地址
AIM_M = __import__('aimfuc')
AIM_F = 'aimfuc'
"""============================變數設定============================"""
ranges = np.vstack([np.zeros((1,30)), np.ones((1,30))]) # 生成自變數的範圍矩陣
borders = np.vstack([np.ones((1,30)), np.ones((1,30))]) # 生成自變數的邊界矩陣
precisions = [4] * 30 # 自變數的編碼精度
"""========================遺傳演算法引數設定========================="""
NIND = 25 # 種群規模
MAXGEN = 1000 # 最大遺傳代數
GGAP = 1; # 代溝:子代與父代的重複率為(1-GGAP),由於後面使用NSGA2演算法,因此該引數無用
selectStyle = 'tour' # 遺傳演算法的選擇方式
recombinStyle = 'xovdprs' # 遺傳演算法的重組方式,設為兩點交叉
recopt = 0.9 # 交叉概率
pm = 0.1 # 變異概率
SUBPOP = 1 # 設定種群數為1f
maxormin = 1 # 設定標記表明這是最小化目標
MAXSIZE = 1000 # 帕累托最優集最大個數
FieldDR = ga.crtfld(ranges, borders, precisions) # 生成區域描述器
"""=======================呼叫進化演算法模板進行種群進化==================="""
# 得到帕累托最優解集NDSet以及解集對應的目標函式值NDSetObjV
[ObjV, NDSet, NDSetObjV, times] = ga.nsga2_templet(AIM_M, AIM_F, None, None, FieldDR, 'R', maxormin, MAXGEN, MAXSIZE, NIND, SUBPOP, GGAP, selectStyle, recombinStyle, recopt, pm, distribute = True, drawing = 1)
執行結果如下:
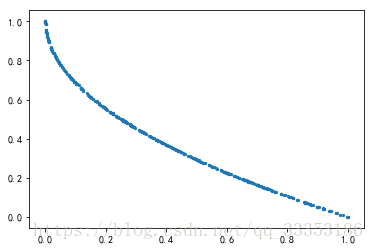
用時: 7.359716176986694 秒 帕累託前沿點個數: 479 個 單位時間找到帕累託前沿點個數: 65 個
可以改用q_sorted_templet快速非支配排序的多目標優化進化演算法模板,可以得到更好的效率和更好的結果:
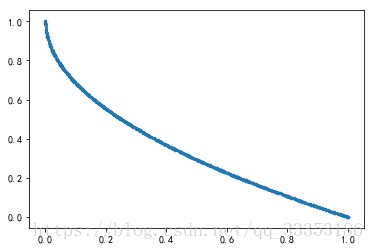
進化演算法的核心演算法邏輯是寫在進化演算法模板內部的,程式碼是開源的,我們可以參考Geatpy進化演算法模板的原始碼來自定義演算法模板,以實現豐富多樣的進化演算法,如差分進化演算法、改進的遺傳演算法等:
後面的部落格將深入理解Geatpy的庫函式用法,以及探討框架的核心——進化演算法模板的實現。還會講一些使用Geatpy解決問題的案例。歡迎繼續跟進~感謝!
下一篇:Python遺傳和進化演算法框架(二)Geatpy庫函式和資料結構