
SceneGraph以及ImageCaption文章專案整理
時序不限:
1.Scene Graph Generation from Objects, Phrases and Region Captions
2018ICCV Yikang Li The Chinese University of Hong Kong
https://github.com/yikang-li/MSDN
考慮的問題:1)物體檢測,場景圖生成和影象標題是不同語義層次的三個場景理解,用場景圖(文字)描述檢測到物件之間的視覺關係
解決:提出了一種新的神經網路模型,稱為多級場景描述網路(表示為MSDN),以端到端的方式聯合解決三個視覺任務該網路細化處理為五個部分,通過VGG16

2.Scene Graph Generation by Iterative Message Passing
CVPR2017Danfei Xu1 Yuke Zhu1 Christopher B. Choy2 Li Fei-Fei1
https://github.com/danfeiX/scene-graph-TF-release
解決的問題:1)影象語義理解需要搞清楚object之間的關聯,有個直接的辦法就是生成關係圖來建模relationship
解決:關於這裡所說的關係往往指主-謂-賓的結構,預測關係就是可以理解為給定主語和賓語時,能夠準確預測謂語。
網路構成:
1.fast-RCNN檢測得到object
2.採用CRF(條件隨機場)來建模,推斷節點和邊的關係
3.使用兩個GRU來表示所有node和edge
3.將graph的推斷迭代問題建模為RNN方式
4.利用message passing提高精度。
5.CRF利用平均場方法來解,(可以認為圖是由頂點和邊構成二分結構,利用平均場,所有對某個定點的影響是由其所連線的所有邊造成的,反過來對於邊也可解釋

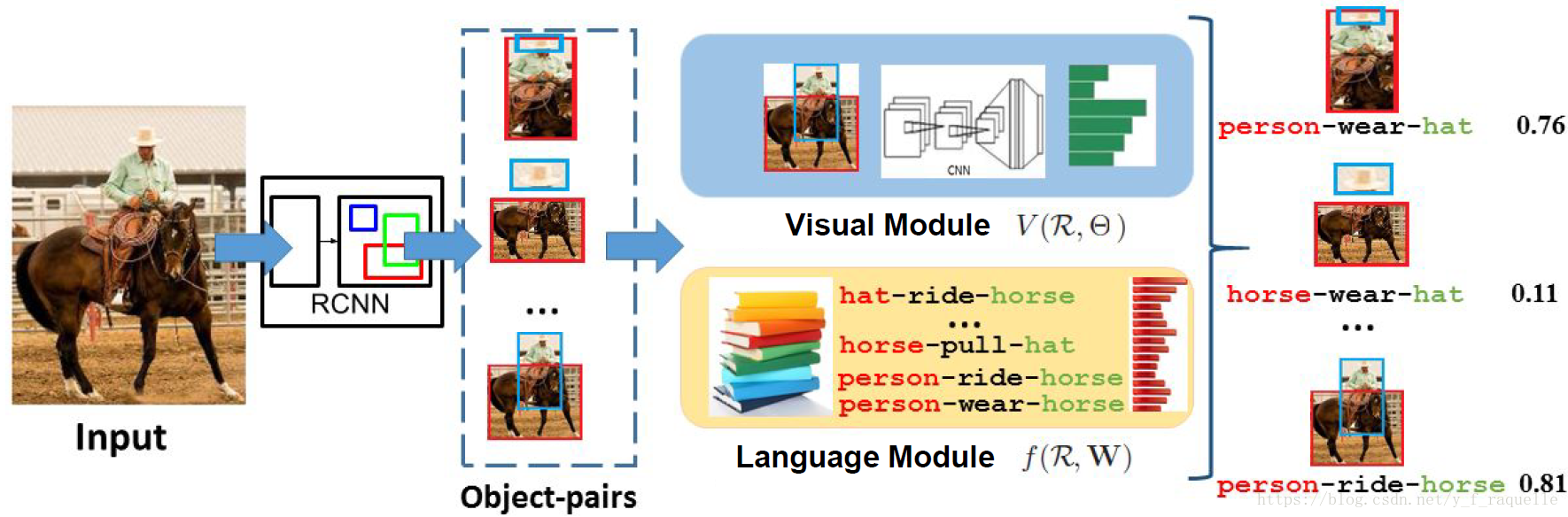
3.Visual Relationship Detection with Language Priors
https://github.com/Prof-Lu-Cewu/Visual-Relationship-Detection
在視覺模型之外引入了語言模型,將關係對映到一個embedding space(embedding我的理解就是抽象為向量),通過學習關係先驗使得相近的關係向量距離很近,輸出可能性評分。
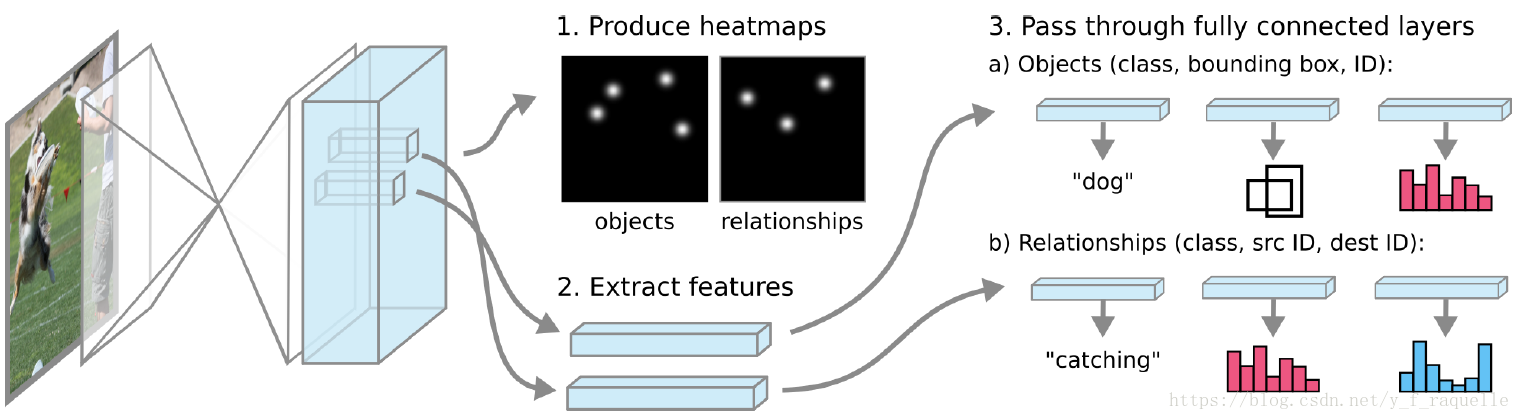
4.Pixels to Graphs by Associative Embedding
https://github.com/princeton-vl/px2graph
引入Human Pose Estimation中的associative embedding。構造一個畫素級網路輸出object和relationship的熱點圖並匯出畫素級features,將帶有id的features匯入全連線層預測object和relationship。
Im2Text:使用100萬張標題照片描述影象

- 論文:http://tamaraberg.com/papers/generation_nips2011.pdf
- 專案:http://vision.cs.stonybrook.edu/~vicente/sbucaptions/
用於視覺識別和描述的長期迴圈卷積網路
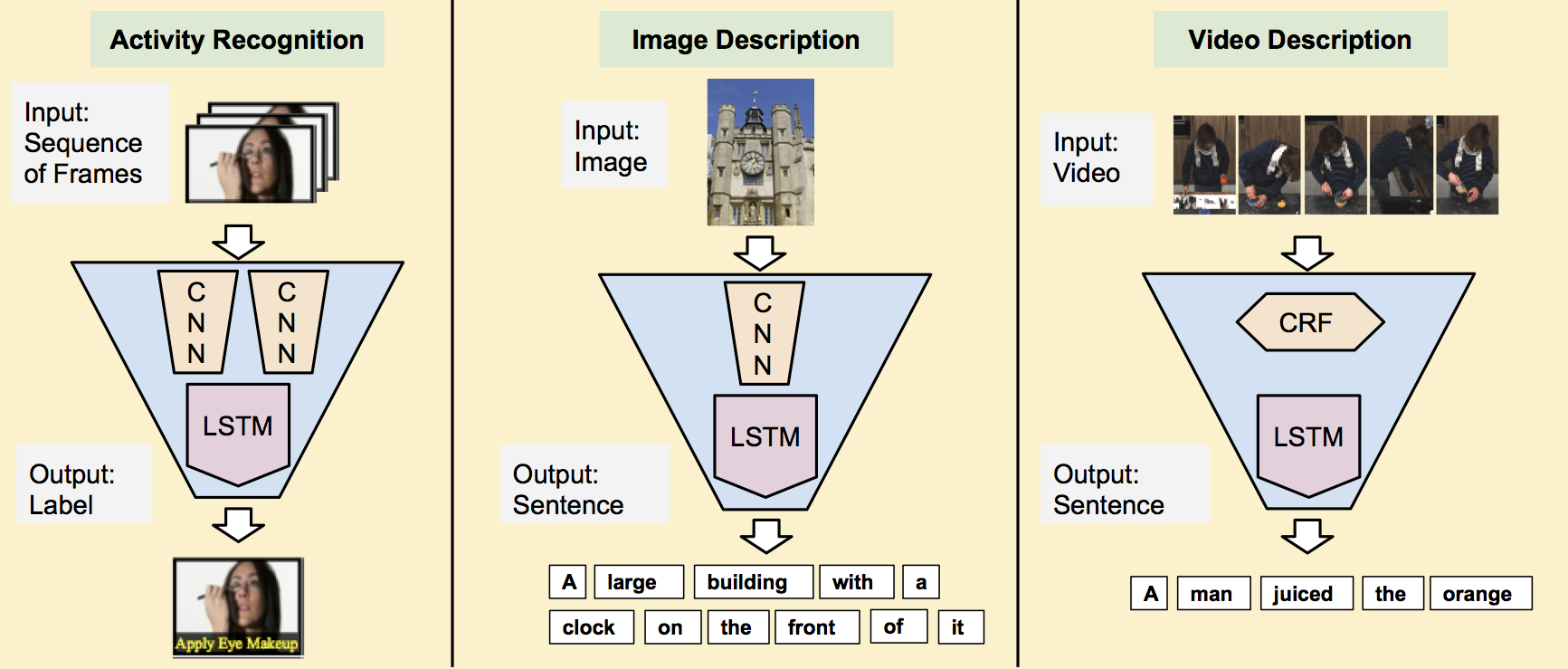
- 簡介:2015年CVPR的口頭報告.LRCN
- 專案頁面:http://jeffdonahue.com/lrcn/
- arxiv:http://arxiv.org/abs/1411.4389
- github:https://github.com/BVLC/caffe/pull/2033
展示並演講
顯示和說明:神經影象標題生成器
- 介紹:谷歌
- arxiv:http://arxiv.org/abs/1411.4555
- github:https://github.com/karpathy/neuraltalk
- gitxiv:http://gitxiv.com/posts/7nofxjoYBXga5XjtL/show-and-tell-a-neural-image-caption-nic-generator
- github:https://github.com/apple2373/chainer_caption_generation
- github(TensorFlow):https://github.com/tensorflow/models/tree/master/im2txt
- github(TensorFlow):https://github.com/zsdonghao/Image-Captioning
CNN和LSTM生成影象標題

- 部落格:http://t-satoshi.blogspot.com/2015/12/image-caption-generation-by-cnn-and-lstm.html
- github:https://github.com/jazzsaxmafia/show_and_tell.tensorflow
展示和講述:從2015年MSCOCO影象字幕挑戰中吸取的教訓
- arxiv:http://arxiv.org/abs/1609.06647
- github:https://github.com/tensorflow/models/tree/master/im2txt
學習影象標題生成的週期性視覺表示
- arxiv:http://arxiv.org/abs/1411.5654
Mind's Eye:影象標題生成的週期性視覺表示
- 簡介:CVPR 2015
- 論文:http://www.cs.cmu.edu/~xinleic/papers/cvpr15_rnn.pdf
用於生成影象描述的深層視覺語義對齊
- 介紹:“提出一個多模態深度網路,使用CNN特徵表示影象的各個有趣區域與相關詞彙對齊。然後,所學習的對應關係用於訓練雙向RNN。該模型不僅能夠生成影象描述,還能夠將句子的不同部分定位到相應的影象區域。“
- 專案頁面:http://cs.stanford.edu/people/karpathy/deepimagesent/
- arxiv:http://arxiv.org/abs/1412.2306
- 幻燈片:http://www.cs.toronto.edu/~vendrov/DeepVisualSemanticAlignments_Class_Presentation.pdf
- github:https://github.com/karpathy/neuraltalk
- 演示:http://cs.stanford.edu/people/karpathy/deepimagesent/rankingdemo/
多模態迴歸神經網路的深字幕
- 介紹:m-RNN。ICLR 2015
- 簡介:“在RNN的嵌入和復發層之後,通過引入新的多模式層,結合了CNN和RNN的功能。”
- 主頁:http://www.stat.ucla.edu/~junhua.mao/m-RNN.html
- arxiv:http://arxiv.org/abs/1412.6632
- github:https://github.com/mjhucla/mRNN-CR
- github:https://github.com/mjhucla/TF-mRNN
顯示,出席和講述
顯示,參與和講述:視覺注意的神經影象標題生成(ICML 2015)
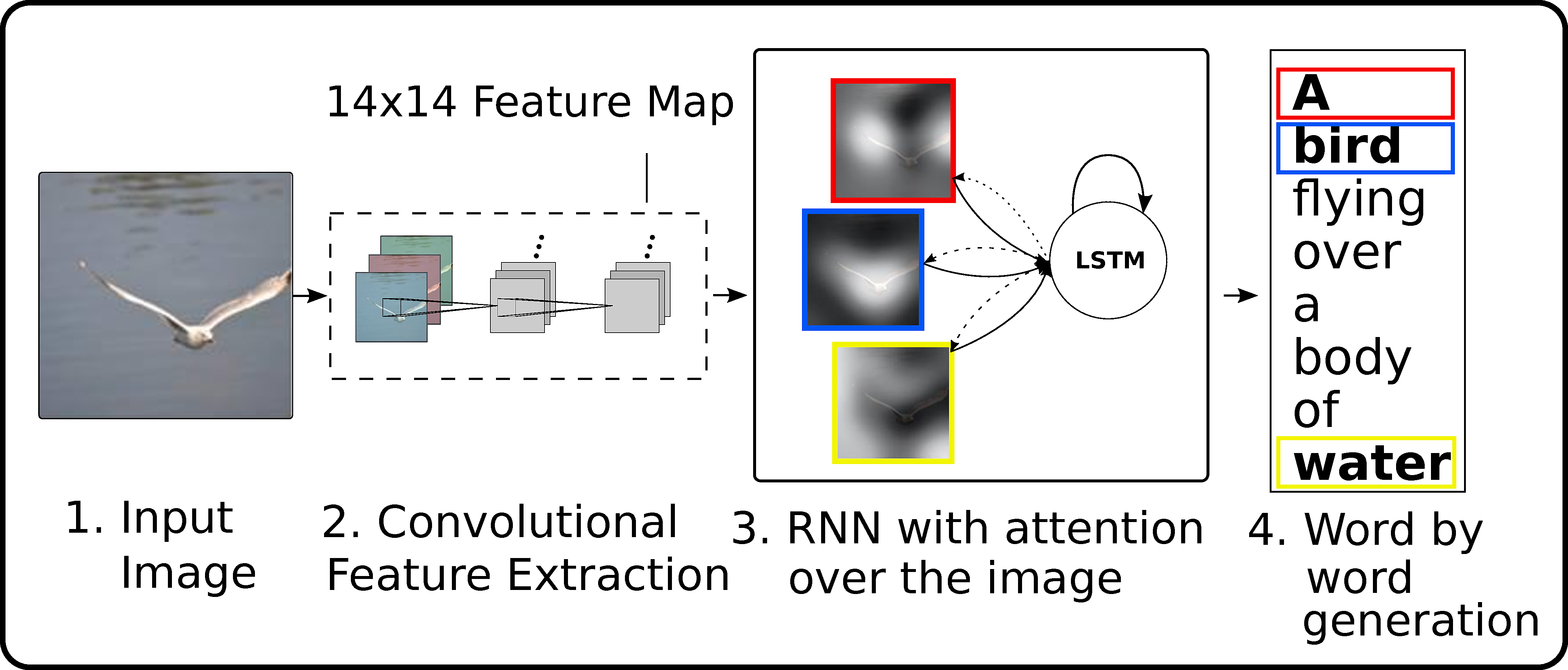
- 專案頁面:http://kelvinxu.github.io/projects/capgen.html
- arxiv:http://arxiv.org/abs/1502.03044
- github:https://github.com/kelvinxu/arctic-captions
- github:https://github.com/jazzsaxmafia/show_attend_and_tell.tensorflow
- github(TensorFlow):https://github.com/yunjey/show-attend-and-tell-tensorflow
- 演示:http://www.cs.toronto.edu/~rkiros/abstract_captions.html
自動描述歷史照片
像孩子一樣學習:從影象句子描述學習快速小說視覺概念
- arxiv:http://arxiv.org/abs/1504.06692
- 主頁:http://www.stat.ucla.edu/~junhua.mao/projects/child_learning.html
- github:https://github.com/mjhucla/NVC-Dataset
明確的高階概念在視覺上對語言問題有什麼價值?
- arxiv:http://arxiv.org/abs/1506.01144
調整在哪裡看和說什麼:影象標題與基於區域的注意和場景分解
- arxiv:http://arxiv.org/abs/1506.06272
使用CNN過濾器學習FRAME模型以進行知識視覺化(CVPR 2015)
- 專案頁面:http://www.stat.ucla.edu/~yang.lu/project/deepFrame/main.html
- arxiv:http://arxiv.org/abs/1509.08379
- 程式碼+資料:http://www.stat.ucla.edu/~yang.lu/project/deepFrame/doc/deepFRAME_1.1.zip
從注意的字幕生成影象
- arxiv:http://arxiv.org/abs/1511.02793
- github:https://github.com/emansim/text2image
- 演示:http://www.cs.toronto.edu/~emansim/cap2im.html
影象和語言的順序嵌入
- arxiv:http://arxiv.org/abs/1511.06361
- github:https://github.com/ivendrov/order-embedding
DenseCap:用於密集字幕的完全卷積定位網路
- 專案頁面:http://cs.stanford.edu/people/karpathy/densecap/
- arxiv:http://arxiv.org/abs/1511.07571
- github(Torch):https://github.com/jcjohnson/densecap
用一系列自然句子表達一個影象流
- 簡介:NIPS 2015. CRCN
- nips-page:http://papers.nips.cc/paper/5776-expressing-an-image-stream-with-a-sequence-of-natural-sentences
- 論文:http://papers.nips.cc/paper/5776-expressing-an-image-stream-with-a-sequence-of-natural-sentences.pdf
- 論文:http://www.cs.cmu.edu/~gunhee/publish/nips15_stream2text.pdf
- 作者頁面:http://www.cs.cmu.edu/~gunhee/
- github:https://github.com/cesc-park/CRCN
影象標題翻譯的多模態支點
- 簡介:ACL 2016
- arxiv:http://arxiv.org/abs/1601.03916
使用深度雙向LSTM的影象字幕
- 簡介:ACMMM 2016
- arxiv:http://arxiv.org/abs/1604.00790
- github(Caffe):https://github.com/deepsemantic/image_captioning
- 演示:https://youtu.be/a0bh9_2LE24
編碼,檢查和解碼:用於生成標題的審閱者模組
檢視網路的標題生成
- 簡介:NIPS 2016
- arxiv:https://arxiv.org/abs/1605.07912
- github:https://github.com/kimiyoung/review_net
神經影象標題中的注意正確性
- arxiv:http://arxiv.org/abs/1605.09553
具有文字條件語義注意的影象標題生成
- arxiv:https://arxiv.org/abs/1606.04621
- github:https://github.com/LuoweiZhou/e2e-gLSTM-sc
DeepDiary:終身影象流的自動字幕生成
- 簡介:ECCV國際自我中心感知,互動和計算研討會
- arxiv:http://arxiv.org/abs/1608.03819
phi-LSTM:基於短語的影象字幕分層LSTM模型
- 簡介:ACCV 2016
- arxiv:http://arxiv.org/abs/1608.05813
用不同的物件標題影象
- arxiv:http://arxiv.org/abs/1606.07770
學習在影象理解中推廣到新的作品
- arxiv:http://arxiv.org/abs/1608.07639
生成字幕而不超出物件
- 簡介:ECCV2016第二屆影象和視訊講故事研討會(VisStory)
- arxiv:https://arxiv.org/abs/1610.03708
SPICE:語義命題影象標題評估
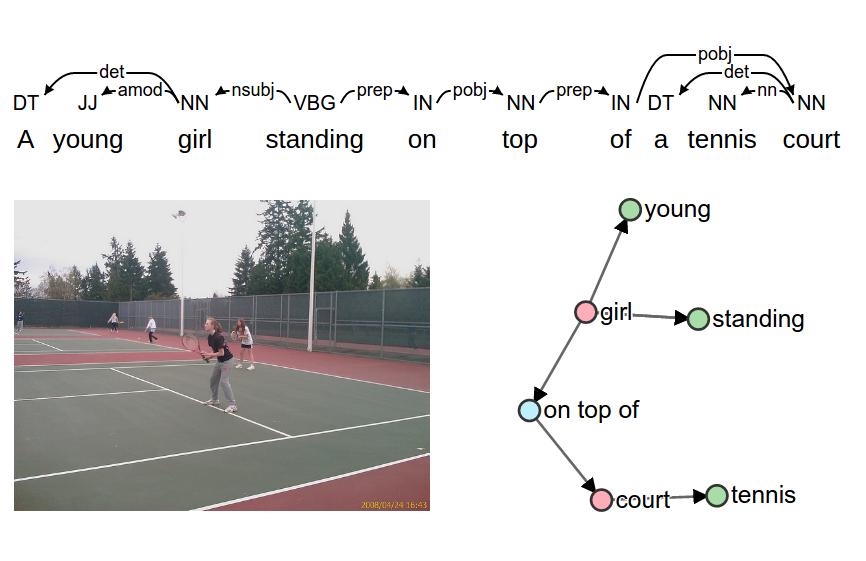
- 簡介:ECCV 2016
- 專案頁面:http://www.panderson.me/spice/
- 論文:http://www.panderson.me/images/SPICE.pdf
- github:https://github.com/peteanderson80/SPICE
使用屬性提升影象標題
- arxiv:https://arxiv.org/abs/1611.01646
Bootstrap,Review,Decode:使用域外文字資料來改進影象字幕
- arxiv:https://arxiv.org/abs/1611.05321
一種生成描述性影象段落的分層方法
- 簡介:斯坦福大學
- arxiv:https://arxiv.org/abs/1611.06607
聯合推理和視覺語境的密集字幕
- 簡介:Snap Inc.
- arxiv:https://arxiv.org/abs/1611.06949
使用策略漸變方法優化影象描述指標
- 簡介:牛津大學和谷歌
- arxiv:https://arxiv.org/abs/1612.00370
影象標題的注意區域
- arxiv:https://arxiv.org/abs/1612.01033
知道何時看:通過Visual Sentinel進行影象捕獲的自適應注意
- 簡介:CVPR 2017
- arxiv:https://arxiv.org/abs/1612.01887
- github:https://github.com/jiasenlu/AdaptiveAttention
迴圈影象捕獲器:使用空間不變變換和注意過濾描述影象
- arxiv:https://arxiv.org/abs/1612.04949
具有語言CNN的經常性公路網路用於影象捕獲
- arxiv:https://arxiv.org/abs/1612.07086
由字幕引導的自上而下的視覺顯著性
- arxiv:https://arxiv.org/abs/1612.07360
- github:https://github.com/VisionLearningGroup/caption-guided-saliency
MAT:用於影象捕獲的多模態注意轉換器
https://arxiv.org/abs/1702.05658
基於深度強化學習的嵌入獎勵影象標題
- 簡介:Snap Inc&Google Inc
- arxiv:https://arxiv.org/abs/1704.03899
參加你:使用上下文序列儲存網路的個性化影象字幕
- 簡介:CVPR 2017
- arxiv:https://arxiv.org/abs/1704.06485
- github:https://github.com/cesc-park/attend2u
Punny Captions:影象描述中的Witty Wordplay
https://arxiv.org/abs/1704.08224
展示,改編和講述:跨領域影象捕獲者的對抗性訓練
https://arxiv.org/abs/1705.00930
影象標題的演員 - 評論家序列訓練
- 簡介:倫敦大學瑪麗皇后學院和楊氏會計諮詢有限公司
- 關鍵詞:演員評論強化學習
- arxiv:https://arxiv.org/abs/1706.09601
迴歸神經網路(RNN)在影象標題生成器中的作用是什麼?
- 簡介:第十屆自然語言世界國際會議論文集(INLG'17)
- arxiv:https://arxiv.org/abs/1708.02043
Stack-Captioning:用於影象字幕的粗到細學習
https://arxiv.org/abs/1709.03376
自導多模LSTM - 當我們沒有完美的影象字幕訓練資料集時
https://arxiv.org/abs/1709.05038
影象標題的對比學習
- 簡介:NIPS 2017
- arxiv:https://arxiv.org/abs/1710.02534
基於分層LSTM模型的基於短語的影象標題
- 簡介:ACCV2016擴充套件,基於短語的影象字幕
- arxiv:https://arxiv.org/abs/1711.05557
卷積影象標題
https://arxiv.org/abs/1711.09151
顯示和傻瓜:製作神經影象字幕的對抗性示例
https://arxiv.org/abs/1712.02051
利用對偶語義對齊改進影象標題
- 簡介:IBM Research
- arxiv:https://arxiv.org/abs/1805.00063
物件計數!將顯式檢測帶回影象標題
- 簡介:NAACL 2018
- arxiv:https://arxiv.org/abs/1805.00314
去除挫敗的影象標題
- 簡介:NAACL 2018
- arxiv:https://arxiv.org/abs/1805.06549
SemStyle:學習使用未對齊文字生成程式化影象標題
- 簡介:CVPR 2018
- arxiv:https://arxiv.org/abs/1805.07030
用條件生成對抗網改進影象標題
https://arxiv.org/abs/1805.07112
CNN + CNN:用於影象捕獲的卷積解碼器
https://arxiv.org/abs/1805.09019
具有詞性引導的多樣且可控的影象標題
https://arxiv.org/abs/1805.12589
學習評估影象標題
- 簡介:CVPR 2018
- arxiv:https://arxiv.org/abs/1806.06422
主題引導注意影象標題
- 簡介:ICIP 2018
- arxiv:https://arxiv.org/abs/1807.03514
用於序列級影象捕獲的上下文感知可視策略網路
- 簡介:ACM MM 2018口服
- arxiv:https://arxiv.org/abs/1808.05864
- github:https://github.com/daqingliu/CAVP
探索影象標題的視覺關係
- 簡介:ECCV 2018
- arxiv:https://arxiv.org/abs/1809.07041
影象字幕作為SOCKEYE中的神經機器翻譯任務
https://arxiv.org/abs/1810.04101
無監督的影象標題
https://arxiv.org/abs/1811.10787
物件描述
無歧義物件描述的生成與理解
- arxiv:https://arxiv.org/abs/1511.02283
- github:https://github.com/mjhucla/Google_Refexp_toolbox
視訊字幕/說明
在統一框架中聯合建模深度視訊和合成文字以橋接視覺和語言
- 簡介:AAAI 2015
- 論文:http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Pan_Jointly_Modeling_Embedding_CVPR_2016_paper.pdf
- 論文:http://web.eecs.umich.edu/~jjcorso/pubs/xu_corso_AAAI2015_v2t.pdf
使用深度遞迴神經網路將視訊轉換為自然語言

- 介紹:NAACL-HLT 2015相機準備就緒
- 專案頁面:https://www.cs.utexas.edu/~vsub/naacl15_project.html
- arxiv:http://arxiv.org/abs/1412.4729
- 幻燈片:https://www.cs.utexas.edu/~vsub/pdf/Translating_Videos_slides.pdf
- 程式碼+資料:https://www.cs.utexas.edu/~vsub/naacl15_project.html#code
利用時間結構描述視訊
- arxiv:http://arxiv.org/abs/1502.08029
- github:https://github.com/yaoli/arctic-capgen-vid
SA-tensorflow:用於生成視訊字幕的軟注意機制
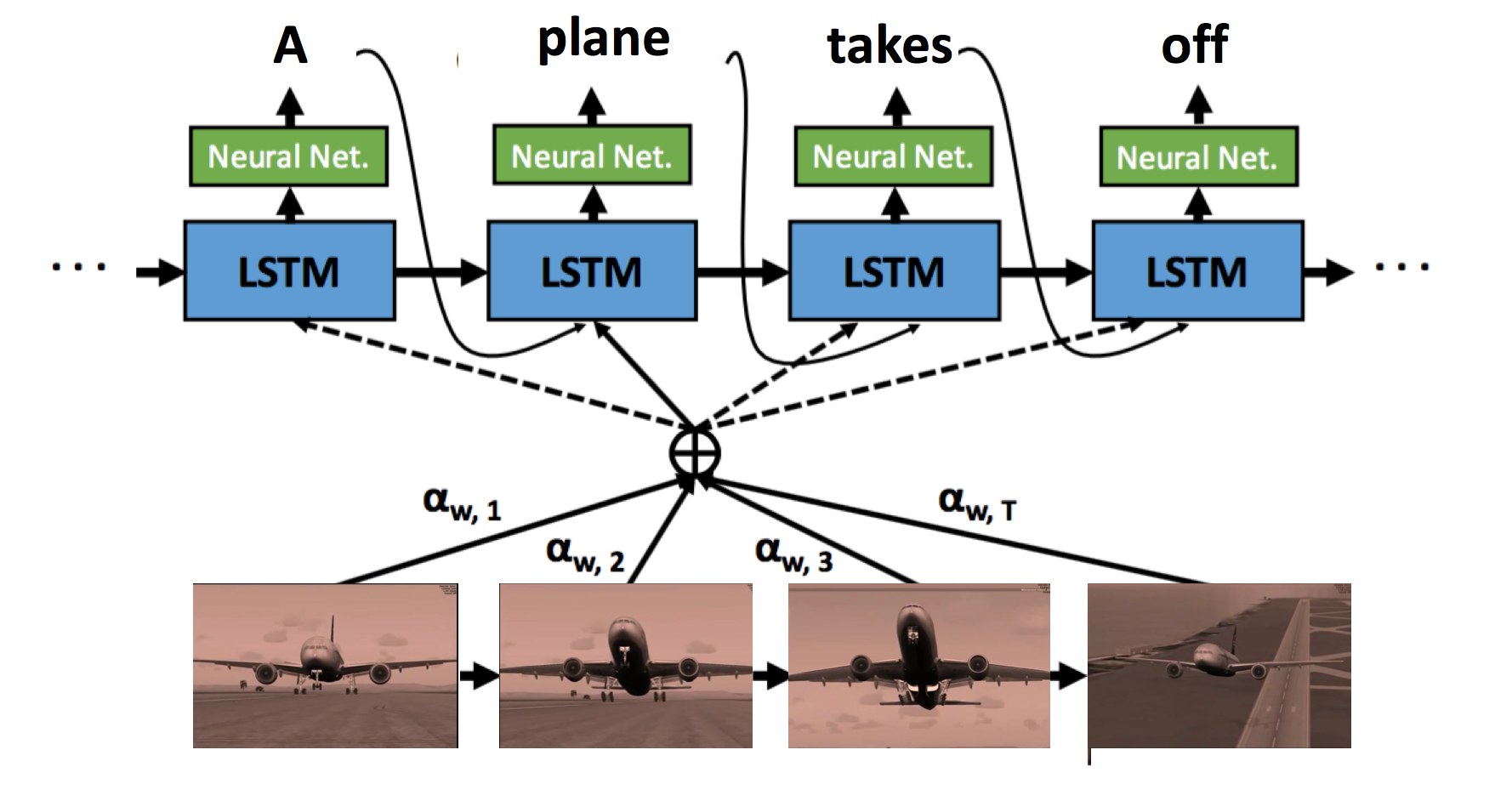
順序到序列 - 視訊到文字

- 簡介:ICCV 2015. S2VT
- 專案頁面:http://vsubhashini.github.io/s2vt.html
- arxiv:http://arxiv.org/abs/1505.00487
- 幻燈片:https://www.cs.utexas.edu/~vsub/pdf/S2VT_slides.pdf
- github(Caffe):https://github.com/vsubhashini/caffe/tree/recurrent/examples/s2vt
- github(TensorFlow):https://github.com/jazzsaxmafia/video_to_sequence
嵌入式翻譯與橋樑視訊與語言的聯合建模
- arxiv:http://arxiv.org/abs/1505.01861
使用雙向遞迴神經網路的視訊描述
- arxiv:http://arxiv.org/abs/1604.03390
視訊描述的雙向長短期記憶
- arxiv:https://arxiv.org/abs/1606.04631
使用人工智慧自動翻譯和標題視訊的3種方法
- 部落格:http://photography.tutsplus.com/tutorials/3-ways-to-subtitle-and-caption-your-videos-automatically-using-artificial-intelligence-cms-26834
用於視訊字幕生成的幀級和段級功能以及候選池評估
- arxiv:http://arxiv.org/abs/1608.04959
影象和視訊的自然語言描述的接地和生成
- 簡介:Anna Rohrbach。艾倫人工智慧研究所(AI2)
- youtube:https://www.youtube.com/watch?v = fE3FX8FowiU
具有語義注意的視訊字幕和檢索模型
- 簡介:LSMDC 2016挑戰賽的四項任務中的三項(填空,多項選擇測試和電影檢索)獲勝者(ECCV 2016研討會)
- arxiv:https://arxiv.org/abs/1610.02947
接地視訊字幕的時空注意模型
- arxiv:https://arxiv.org/abs/1610.04997
視訊和語言:通過深度學習橋接視訊和語言
- 介紹:ECCV-MM 2016.字幕,評論,對齊
- 幻燈片:https://www.microsoft.com/en-us/research/wp-content/uploads/2016/10/Video-and-Language-ECCV-MM-2016-Tao-Mei-Pub.pdf
用於描述視訊的迴圈記憶體定址
- arxiv:https://arxiv.org/abs/1611.06492
具有傳輸語義屬性的視訊字幕
- arxiv:https://arxiv.org/abs/1611.07675
用於將視訊轉換為語言的自適應特徵提取
- arxiv:https://arxiv.org/abs/1611.07837
視覺字幕的語義組合網路
- 簡介:CVPR 2017.杜克大學和清華大學及MSR
- arxiv:https://arxiv.org/abs/1611.08002
- github:https://github.com/zhegan27/SCN_for_video_captioning
用於視訊字幕的分層邊界感知神經編碼器
- arxiv:https://arxiv.org/abs/1611.09312
基於注意力的多模融合視訊描述
- arxiv:https://arxiv.org/abs/1701.03126
弱監督密集視訊字幕
- 簡介:CVPR 2017
- arxiv:https://arxiv.org/abs/1704.01502
用基礎和共同參考的人生成描述
- 簡介:CVPR 2017.電影描述
- arxiv:https://arxiv.org/abs/1704.01518
具有視訊和蘊涵生成的多工視訊字幕
- 簡介:ACL 2017. UNC教堂山
- arxiv:https://arxiv.org/abs/1704.07489
視訊中的密集字幕事件
- 專案頁面:http://cs.stanford.edu/people/ranjaykrishna/densevid/
- arxiv:https://arxiv.org/abs/1705.00754
具有視訊字幕調整時間注意的分層LSTM
https://arxiv.org/abs/1706.01231
強化視訊字幕與蘊涵獎勵
- 簡介:EMNLP 2017. UNC教堂山
- arxiv:https://arxiv.org/abs/1708.02300
用於視訊字幕,檢索和問題回答的端到端概念詞檢測
- 簡介:CVPR 2017.在LSMDC 2016挑戰賽的四項任務中,獲得三項(填空,多項選擇測試和電影檢索)
- arxiv:https://arxiv.org/abs/1610.02947
- 幻燈片:https://drive.google.com/file/d/0B9nOObAFqKC9aHl2VWJVNFp1bFk/view
從確定性到生成性:用於視訊字幕的多模態隨機RNN
https://arxiv.org/abs/1708.02478
用於視訊字幕的接地物件和互動
https://arxiv.org/abs/1711.06354
整合視覺和音訊提示以增強視訊標題
https://arxiv.org/abs/1711.08097
通過分層強化學習的視訊字幕
https://arxiv.org/abs/1711.11135
基於共識的視訊字幕序列訓練
https://arxiv.org/abs/1712.09532
少即是多:為視訊字幕選擇資訊框架
https://arxiv.org/abs/1803.01457
多工強化學習的端到端視訊字幕
https://arxiv.org/abs/1803.07950
具有遮蔽變壓器的端到端密集視訊字幕
- 簡介:CVPR 2018.密歇根大學和Salesforce Research
- arxiv:https://arxiv.org/abs/1804.00819
視訊字幕重建網路
- 簡介:CVPR 2018
- arxiv:https://arxiv.org/abs/1803.11438
用於密集視訊字幕的雙向注入融合與上下文門控
- 簡介:CVPR 2018聚光燈紙
- arxiv:https://arxiv.org/abs/1804.00100
聯合本地化和描述密集視訊字幕的事件
- 簡介:CVPR 2018 Spotlight,2017年ActivityNet Captions Challenge排名第1
- arxiv:https://arxiv.org/abs/1804.08274
語境化,顯示和講述:神經視覺講故事者
https://arxiv.org/abs/1806.00738
RUC + CMU:視訊中密集字幕事件的系統報告
- 簡介:ActivityNet 2018密集視訊字幕挑戰中的獲勝者
- arxiv:https://arxiv.org/abs/1806.08854
專案
學習用於影象標題生成的CNN-LSTM架構:CNN-LSTM影象標題生成器架構的實現,其在MSCOCO資料集上實現接近最先進的結果。
screengrab-caption:一個openframeworks應用程式,用神經網路為你的桌面螢幕加上字幕
- 介紹:openframeworks應用程式,它抓取您的桌面螢幕,然後將其傳送到暗網以進行字幕。適用於視訊通話。
- github:https://github.com/genekogan/screengrab-caption
工具
CaptionBot(微軟)