
Python資料探勘學習筆記(12)淘寶圖片爬蟲實戰
所謂圖片爬蟲,即是從網際網路中自動把對方伺服器上的圖片爬下來的爬蟲程式。
一、圖片爬蟲前的網頁連結分析
1.首先開啟淘寶首頁,在搜尋框中輸入關鍵詞,如“神舟”,在搜尋結果介面中點選下一頁,分別開啟第一頁,第二頁,第三頁的搜尋結果,並記下每一頁結果的URL至記事本中,如下:
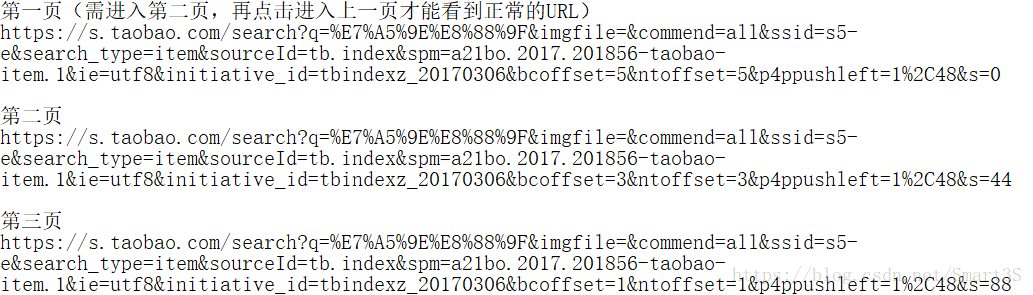
2.觀察每一個網頁的URL,不要去觀察它們不同的部分,而是著眼於每個URL中相似的部分。
(1)可以注意到每個URL中都有“s=XXX”部分,推測為代表了不同的頁碼的數值,0代表第一頁,44代表了第二頁,88代表了第三頁,推測132代表第四頁,將第一頁的URL中的“s=0”修改為“s=132”,即可發現神奇般地跳轉到了第四頁。
(2)雖然將URL複製下來之後無法看到關鍵詞,但是在瀏覽器中可以清晰看到“q=XXX”為輸入的關鍵詞內容,可以推測,瀏覽器在實際獲取網頁時將中文字元進行了編碼。
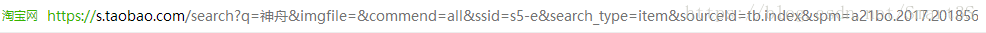
3.因此可以初步設想出圖片爬蟲所需要的網頁連結的結構:(在任意頁的URL基礎上進行修改)

二、圖片爬蟲前的圖片連結分析
1.右鍵單擊淘寶網頁上的圖片,點選複製圖片地址,貼上到記事本中分析:
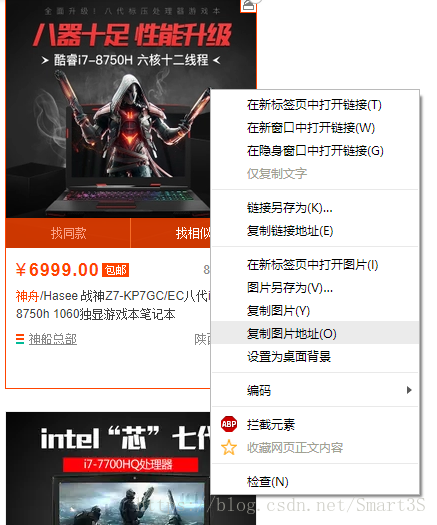
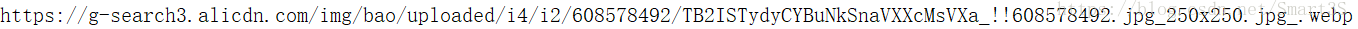
3.觀察URL,注意到前半部分為圖片資源在伺服器中的地址,後半部分為圖片名稱以及其格式,特別是“250X250”代表了圖片的解析度,因為在淘寶搜尋頁中,為節省資源,採取了縮圖的方式。
4.將圖片URL中的核心部分,如本例的“TB2ISTydyCYBuNkSnaVXXcMsVXa”在原始碼頁面中進行搜尋:
將連結複製下來開啟,即可發現,高清大圖無處遁形:
5.觀察圖片連結的前後格式,注意到前以 pic_url":" 開頭,後以 ", 結尾,本例內容比較簡單,無需進行抓包即可獲取圖片連結。
三、圖片爬蟲程式編寫
import urllib.request import re keyname="神舟" key=urllib.request.quote(keyname) #編碼 #嘗試爬取前三頁內容 for i in range(0,3): #構造頁面URL url="https://s.taobao.com/search?q="+key+"&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180915&ie=utf8&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s="+str(i*44) data=urllib.request.urlopen(url).read().decode("utf-8","ignore") pat='pic_url":"//(.*?)"' #獲得圖片URL imagelist=re.compile(pat).findall(data) for j in range(0,len(imagelist)): thisimg=imagelist[j] #構造圖片URL thisimgurl="http://"+thisimg file="F:/taobaoIMG/"+str(i)+str(j)+".jpg" urllib.request.urlretrieve(thisimgurl,filename=file)
已知問題:爬取結果圖片可能會是匹配度較差的圖片,如本例可能會出現諸如神舟飛船模型、神舟鳥電動車之類的結果,可能是淘寶網站做的反爬蟲阻攔,歡迎大神指點。