
jmeter教程(八):關聯及正則表示式提取器
所謂關聯,就在從前面請求的響應中提取資料,給後面的請求使用。而提取資料,則需要用到後置處理器裡的正則表示式提取器。為了演示,我簡單寫了一個java請求,模擬介面的響應資料

響應的資料為一個json,這是模擬介面查詢會員列表的資料。time是查詢資料花費的時間,count是查詢出了多少條資料,memberList就是使用者的列表資訊,是個陣列,陣列的一個元素,就是一條使用者的資訊,包括使用者的id、name、phone、status資訊。在頁面顯示使用者列表資訊,都會做分頁,所以只顯示了10條使用者的資訊。這些資料,在瀏覽器中被js一解析,就可能是一個表格。
現在我們把這個java請求,當作是伺服器的介面,呼叫後獲取了響應資料,現在需要獲取使用者“張三”的id,給後面的介面做引數用,應該怎麼做?這個時候就需要用後置處理器的正則表示式提取器了


引用名稱,可以理解為就是一個變數,用來儲存提取出來的內容。正則表示式,就是提取內容的表示式,其中“(.*)”是一個捕獲組,會把 "id": 和 ,"name":"張三" 之間的內容捕獲,然後賦值給“userId”。模板和匹配數字,先就這樣寫,這個在下面再講,預設值,就是沒有提取到值的時候,那麼就會把預設值賦值給 userId,現在這個用處不大,在後面講流程控制裡的判斷語句的時候,會需要使用預設值。
那到底會提取什麼出來呢,這個時候可以使用前面講的java請求,把這個userId的實際值響應出來。

儲存指令碼,執行,看結果

可以看到,這樣就把使用者 張三 的id提取出來了。當然,正則表示式裡面,也可以使用變數。在測試計劃中宣告一個全域性變數name,值是 張三。

正則表示式中使用該變數
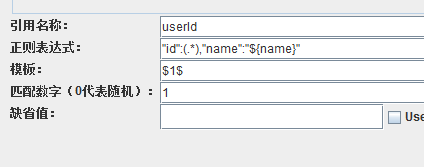
儲存指令碼,執行,可以看到結果是一樣的。現在,如果要提取使用者 李四 的id呢,改正則表示式

儲存,執行,看結果

可以看到,提取的結果,就不是我們想要的啦,那個name亂碼是因為沒有加GBK編碼,在程式碼里加上GBK編碼再重新打jar包就可以解決。正則表示式匹配,是從字串的第一個字元開始匹配,我們的正則表示式為:"id":(.*),"name":"李四",那麼就會從響應裡的第一個字元開始找,先找 "id": 這個字串,結果在張三的資訊裡找到了,那麼就會把這個作為開始標記,然後再往後找結束標記,也就是 ,"name":"李四",找到後,就會把開始標記和結束標記之間的字串捕獲,賦值給userId,這樣就出現了上面的結果了。可我們要的是李四的id啊,要怎麼弄?可以這樣做,改正則表示式提取器
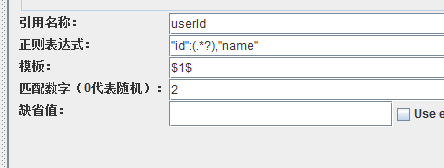
儲存,執行之後,可以看到結果就是2。為什麼呢?這裡,就涉及到一個概念:貪婪匹配和非貪婪匹配。捕獲字串,需要給一個開始標記和結束標記,或者叫左邊界和右邊界吧。那麼正則引擎就會先找開始標記,找到了就會儲存下來,然後再往後找結束標記,找到了之後,如果是非貪婪模式,那麼匹配結束,把開始和結束標記之間的字串返回。如果是貪婪模式的話,找到結束標記之後,還會繼續往後找,看後面是否還有結束標記,如果後面還有結束標記,就是把前面找到的結束標記丟掉,改用後面的結束標記,然後再往後找。。。一直找到字串的末尾。貪婪和非貪婪在寫法上的區別就是在括號中是不是以?結束。像之前寫的括號中都沒有?,就是貪婪模式,現在在括號裡的後面加上?就變成非貪婪模式了。我們現在的正則表示式為: "id":(.*?),"name",所以就先找開始標記 "id":,找到之後,再找結束標記 ,"name",找到之後,就立馬把兩者之間字串返回,這就完成了一次查詢(捕獲)。非貪婪模式和貪婪模式不一樣,貪婪模式只會查詢一次,因為它是貪婪模式,找到的結果也只會有一條,而非貪婪模式,找出的結果,就可能會是多條。所以還會有第二次查詢。第二次查詢就從第一次查詢的結束標記之後開始查詢,不過查詢的是開始標記,找到之後,再找結束標記,如果找到,再把兩者之間的字串返回,第二次查詢完成。然後第三次、第四次。。。一直到字串的結束位置。所以上面的正則表示式,實際上就是會把所有使用者的id捕獲,然後通過匹配數字來獲取對應的資料,如果要第1個使用者的id,匹配數字就是1。如果要第7個使用者的id,匹配數字就是7。所以匹配數字在貪婪模式下,只能取1,只有在非貪婪模式下,才可能有不為1的情況。
利用上面的方法,是提取出了 李四 的id,不難看出,還是有缺陷,因為要知道李四的資訊在陣列中的位置。如果不知道李四在陣列中的位置,要怎麼獲取他的id呢?這個,暫時沒有好的解決方案,後面學了流程控制,可以解決這個問題。
現在再看另一個問題:我要提取出id為1的使用者的手機號,但是我並不知道他的name是什麼。要怎麼做?
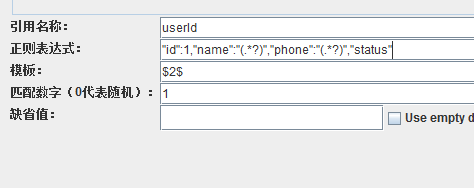
現在的正則表示式,有兩個括號了,也就是有兩個捕獲組,準確地說是有三個捕獲組,整個表示式是一個組。這個時候要取某個組裡的內容,就要用到組的序號。整個表示式是一個組,組的序號是0,name後面的組序號是1,phone後面的組,序號是2,所以模板裡寫$2$,就是取第二個捕獲組的內容的意思。執行之後,就可以看到第一個使用者的手機號13512341234了。也可以這樣寫:

執行結果:

加上了GBK編碼,中文就可以正常顯示了。現在我想要id為1的使用者的手機號的後四位,同樣不知道使用者的名字,怎麼獲取?
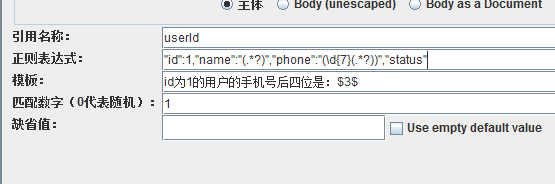
括號巢狀括號,組號,先算外層的,然後是裡層的,所以phone後面的外層括號組號是2,裡層的是3。我們想要的只是手機號的後四位,name或是phone的11位手機號,並不需要,捕獲它們,是會消耗效能和佔用記憶體的,所有,可以使用非捕獲組,非捕獲組,就是在括號內,以?:開頭,所以可以這樣寫
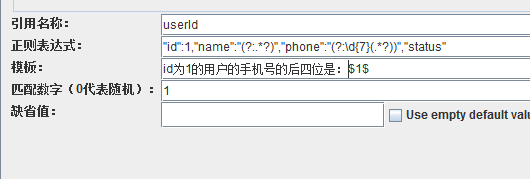
因為name後面的組,及phone後面的外層組,都使用了非捕獲,所以phone後面的裡層分組就成為了第1組,組號是1,模板裡就要用 $1$ 來取分組裡的內容。
前面講的這些都是從響應的主體資訊裡提取資料,還可以從響應的請求頭、URL等裡面提取資料。正則表示式的寫法是一樣,只是在“要檢查的響應欄位”裡選擇不同的選項就可以了

然後最上面還有一個“Apple to”,這個是一個更大範圍的從哪裡提取。前面的三個,主要涉及到重定向。重定向就會有主請求和重定向的請求,重定向的請求這裡面叫Sub-sample,也就是子請求了,這個的話,以後再演示吧。最後一個JMeter Variable,就是從一個變數中提取值。依舊用前面的模擬介面的java請求為例,比如要提取出李四的id,前面用非貪婪匹配實現了,這裡也可以用另一種方式實現,不過也不是完美的方案。先在正則表示式裡配置:

儲存,執行,看結果:

這個時候,可以在第一個請求上再加一個正則表示式提取器


執行之後,結果

這裡就要注意,兩個正則表示式提取器的位置不能反了。更好的做法是,第二個正則表示式提取器寫成:

這樣,可以做到,不管李四在什麼位置,都可以獲取到他的id。id是純數字,可以這樣解決,如果是任意字元,就不能這樣弄了。