
gcc 的執行過程詳解 預處理 編譯 彙編 連結
在Linux中,使用GCC編譯程式的過程可以被分為四個階段:
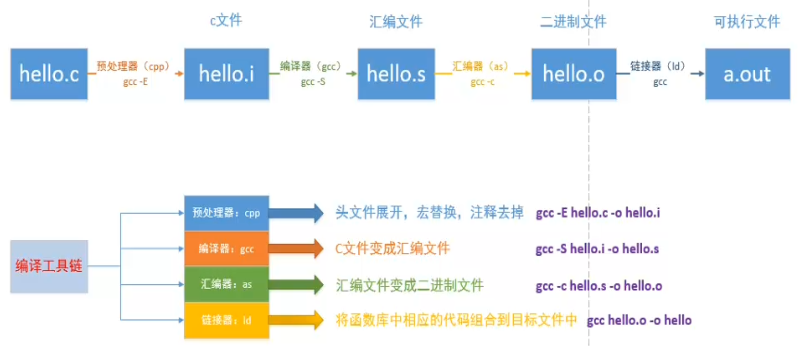
下面我們以hello.c為例,來看看各個階段,編譯器做了什麼

----對hello.c進行預編譯
執行命令:gcc -E hello.c -o hello.i,開啟生成的hello.i檔案

可以看到由原來的10行變成了858行。
----對hello.i進行編譯,這個時候我們的程式碼就變成彙編指令了。
gcc -S hello.i -o hello.s
----對hello.s進行彙編,這一步的工作是生成二進位制機器指令,
gcc -c hello.s -o hello.o

----最後,對hello.o進行連結,生成可執行程式
gcc hello.o -o hello

相關推薦
gcc 的執行過程詳解 預處理 編譯 彙編 連結
在Linux中,使用GCC編譯程式的過程可以被分為四個階段: 下面我們以hello.c為例,來看看各個階段,編譯器做了什麼 ----對hello.c進行預編譯 執行命令:gcc -E hello.c -o hello.i,開啟生成的hello.i檔案
GCC程式設計四個過程:預處理-編譯-彙編-連結
2009年12月09日 星期三 13:14 在Linux下進行C語言程式設計,必然要採用GNU GCC來編譯C原始碼生成可執行程式。 一、GCC快速入門 Gcc指令的一般格式為:Gcc [選項] 要編譯的檔案 [選項] [目標檔案] 其中,目標檔案可預設,Gcc預設生成
GCC程式設計過程:預處理-編譯-彙編-連結
在Linux下進行C語言程式設計,必然要採用GNU GCC來編譯C原始碼生成可執行程式。 一、GCC快速入門 Gcc指令的一般格式為:Gcc [選項] 要編譯的檔案 [選項] [目標檔案] 其中,目標檔案可預設,Gcc預設生成可執行的檔名為:編譯檔案.out 我們來看一下經典入門程式"Hello Worl
拆解GCC命令的預處理-編譯-彙編-連結4個階段
原文連結:http://blog.csdn.net/jmy5945hh/article/details/7435234 在linux下使用gcc命令編譯程式時,整個過程實際上在底層處理分為四個步驟--預處理/編譯/彙編/連線。 下面通過gcc的不同命令引數來拆解這四個步驟。 原始碼:
gcc編譯程式的四個階段(預處理-編譯-彙編-連結)
gcc的編譯流程分為四個步驟,分別為: ・ 預處理(Pre-Processing) ・ 編譯(Compiling) ・ 彙編(Assembling) ・ 連結(Linking) 下面就具體來檢視一下gcc是如何完成四個步驟的。 hello.c原始碼 #include
預處理->編譯->彙編->連結
這是本人的第一篇部落格,主要是想記錄一些心得,增加印象,如果能給大家提供一些參考就更好了。 水平有限,還請大家批判。 本文全部例子在centos 7上執行,gcc 版本 4.8.5 20150623 (Red Hat 4.8.5-28) (GCC) 一個例子(檔名為
C++ 編譯,執行過程 詳解。
要更深入瞭解C++, 必須要知道一個程式從開始到結束都幹了些什麼, 怎麼幹的。 所以我從C++編譯到執行過程,解析下程式是怎麼跑的。 首先,初略的說一下之前C++的編譯過程,C++編譯過程包括預編譯-》彙編-》編譯-》連結。稱為一個可執行檔案
SQL語句執行過程詳解
使用 錯誤信息 意思 排錯 表達 對象 data 才會 結果集 一、SQL語句執行原 第一步:客戶端把語句發給服務器端執行當我們在客戶端執行 select 語句時,客戶端會把這條 SQL 語句發送給服務器端,讓服務器端的進程來處理這語句。也就是說,Oracl
計算機指令執行過程詳解
一、計算機的基本組成 馮·諾依曼計算機的特點(機器以運算器為中心) 1. 計算機由控制器(分析和執行機器指令並控制各部件的協同工作)、運算器(根據控制訊號對資料進行算術運算和邏輯運算)、儲存器(記憶體儲存中間結果,外存儲存需要長期儲存的資訊)、輸入裝置(接收外界資訊)和輸出裝置(向外界輸送資
Java編譯程式和執行過程詳解
java整個編譯以及執行的過程相當繁瑣,我就舉一個簡單的例子說明: 編譯原理簡單過程:詞法分析 --> 語法分析 --> 語義分析和中間程式碼生成 --> 優化 --> 目的碼生成 Java程式從原始檔建立到程式執行要經過兩大步驟: 1、Java檔案會由
大資料基礎課之Hadoop MapReduce執行過程詳解
述一下mapreduce的流程(shuffle的sort,partitions,group) 首先是 Mapreduce經過SplitInput 輸入分片 決定map的個數在用Record記錄 key value。然後分為以下三個流程: Map: 輸入 key
Spark MLlib 貝葉斯分類演算法例項具體程式碼及執行過程詳解
import org.apache.log4j.{Level, Logger} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.mllib.classification.{NaiveBayes, Naiv
MapReduce On yarn執行過程詳解
老的MapReduce主要包括Job Tracker和Task Tracker,YARN中主要是三個元件:Resource Manager、Node Manager和Application Master。Resource Manager負責全域性資源分配,Applicatio
非相關子查詢和相關子查詢執行過程詳解
前段時間有一個相關子查詢的SQL語句,看不太懂他是如何執行的,為什麼會出現那個結果。著實糾結了一把。下面來講一下非相關子查詢和相關子查詢的執行過程是怎樣的。 非相關子查詢 先看一個非相關子查詢到sql
Spark計算Pi執行過程詳解---Spark學習筆記4
上回運行了一個計算Pi的例子 那麼Spark究竟是怎麼執行的呢? 我們來看一下指令碼 #!/bin/sh export YARN_CONF_DIR=/home/victor/software/hadoop-2.2.0/etc/hadoop SPARK_JAR=./ass
Hadoop MapReduce執行過程詳解(帶hadoop例子)
問題導讀1.MapReduce是如何執行任務的? 2.Mapper任務是怎樣的一個過程? 3.Reduce是如何執行任務的? 4.鍵值對是如何編號的? 5.例項,如何計算沒見最高氣溫? 分析MapReduce執行過程 MapReduce執行的時候,會通過Mapper執
JS的解析與執行過程—(全局預處理階段)
調用 ont err col 過程 預處理 報錯 彈出 error: 問題:有如下代碼 1 var a = 1; 2 function pop() { 3 alert(a); 4 var a = 5; 5 } 6 pop();//執行結果,彈
JS的解析與執行過程—全局預處理階段之命名沖突的處理策略
bsp env 函數表 nvi body 相同 class pre 優先級 有如下代碼: 1 <body> 2 <script> 3 alert(f); 4 5 fun
mysql中SQL執行過程詳解
mysql執行一個查詢的過程,到底做了些什麼: 客戶端傳送一條查詢給伺服器; 伺服器先
一條 sql 的執行過程詳解
寫操作執行過程 如果這條sql是寫操作(insert、update、delete),那麼大致的過程如下,其中引擎層是屬於 InnoDB 儲存引擎的,因為InnoDB 是預設的儲存引擎,也是主流的,所以這裡只說明 InnoDB 的引擎層過程。由於寫操作較查詢操作更為複雜,所以先