
[吳恩達機器學習筆記]15.1-3非監督學習異常檢測演算法/高斯回回歸模型
阿新 • • 發佈:2018-12-09
15.異常檢測 Anomaly detection
覺得有用的話,歡迎一起討論相互學習~Follow Me
15.1問題動機 Problem motivation
飛機引擎異常檢測
- 假想你是一個飛機引擎製造商,當你生產的飛機引擎從生產線上流出時,你需要進行 QA(質量控制測試),而作為這個測試的一部分,你測量了飛機引擎的一些特徵變數,比如引擎運轉時產生的熱量,或者引擎的振動等等。如下圖所示: 用以表示測量得到的飛機引擎的特徵。而資料集中的m個數據用表示
- 這樣一來,你就有了一個數據集,從 ,如果你生產了 m 個引擎的話,你將這些資料繪製成圖表,看起來就是這個樣子:
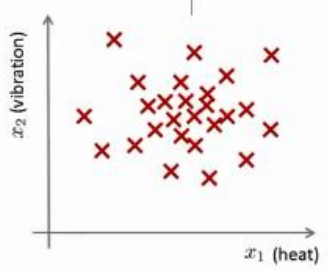
- 這裡的每個點、每個叉,都是你的 無標籤資料 。這樣,異常檢測問題可以定義如下:假設後來有一天,你有一個新的飛機引擎從生產線上流出,而你的新飛機引擎有特徵變數。所謂的異常檢測問題就是:希望知道這個新的飛機引擎是否有某種異常,或者說,我們希望判斷這個引擎是否需要進一步測試。因為,如果它看起來像一個正常的引擎,那麼我們可以直接將它運送到客戶那裡,而不需要進一步的測試。
- 給定一個訓練集,然後對訓練資料進行建模即,即對飛機引擎的特徵進行建模,然後當給定一個新的資料即,如果概率低於閾值ε– 那麼就將其標記為異常,如果概率大於等於閾值ε– 那麼就將其標記為正常
- 觀察模型,將會發現在中心區域的這些點概率相當大,而稍微遠離中心的點概率會少些,而離中心更遠的點,其概率會更小即出現異常的概率會更大,而最外的標記點就是 異常點(anomaly) ,而中心區域的點P(x)很大即是 正確的點

- 這種方法稱為 密度估計 表達如下:
欺騙識別
- 使用,通過檢測是否有來斷定使用者是否是一個非正常使用者。
- 異常檢測主要用來識別欺騙。例如線上採集而來的有關使用者的資料,一個特徵向量中可能會包含如:使用者多久登入一次,訪問過的頁面,在論壇釋出的帖子數量,甚至是打字速度等。嘗試根據這些特徵構建一個模型,可以用這個模型來識別行為異常的使用者。
資料中心異常檢測
- 特徵可能包含:記憶體使用情況,被訪問的磁碟數量,CPU的負載,網路的通訊量等。根據這些特徵可以構建一個模型,用來是否有來判斷某些計算機是不是有可能出錯了
15.2高斯分佈 Gaussian Distribution
- 通常如果我們認為變數 x 符合高斯分佈 x~N(μ,σ2)則其概率密度函式為:
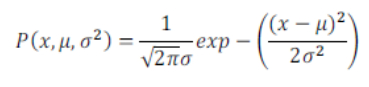
其中表示資料的平均值而表示樣本的方差,橫軸表示資料的值,而縱軸則表示此值出現的概率密度,影象與一段範圍內的橫軸包圍的面積即為x的取值落在此範圍內的概率,其影象如下圖所示:
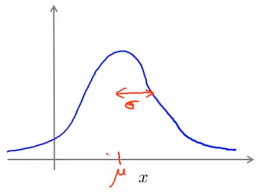
其中控制影象的中線所在位置,而控制影象的寬度,並且對於概率密度函式而言,其與座標軸包圍的區域的面積始終為1 - 利用已有的資料來預測總體中的的計算方法如下:
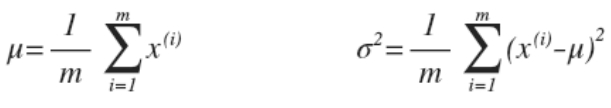
其中統計學家認為計算方法中的分母應該為(m+1),而機器學習學者則認為其中的分母為m也很合適,當時資料量十分巨大時,分母為m或者為(m+1)實質上沒有很大的區別。

15.3非監督學習的異常檢測演算法
- 假定有共m個樣本的無標籤訓練集,訓練集中的每個樣本都是一個維的特徵向量。
則處理異常檢測的方法是 使用資料集建立起概率模型p(x) 試圖通過特徵量的乘積來對樣本的異常狀況進行檢測。 - 假設特徵量之間是相互獨立的,則概率模型可表示為特徵量的概率的乘積: