
演算法工程師修仙之路:吳恩達機器學習(七)
吳恩達機器學習筆記及作業程式碼實現中文版
第六章 神經網路學習
非線性假設
-
無論是線性迴歸還是邏輯迴歸都有這樣一個缺點:當特徵太多時,計算的負荷會非常大。
-
使用非線性的多項式項,能夠幫助我們建立更好的分類模型。假設我們有非常多的特徵,例如大於 100 個變數,我們希望用這 100 個特徵來構建一個非線性的多項式模型,結果將是數量非常驚人的特徵組合,即便我們只採用兩兩特徵的組合( ),我們也會有接近 5000 個組合而成的特徵。這對於一般的邏輯迴歸來說需要計算的特徵太多了。
-
假設我們希望訓練一個模型來識別視覺物件(例如識別一張圖片上是否是一輛汽車),一種方法是我們利用很多汽車的圖片和很多非汽車的圖片,然後利用這些圖片上一個個畫素的值(飽和度或亮度)來作為特徵。
-
假如我們只選用灰度圖片,每個畫素則只有一個值(而非 RGB 值),我們可以選取圖片上的兩個不同位置上的兩個畫素,然後訓練一個邏輯迴歸演算法利用這兩個畫素的值來判斷圖片上是否是汽車:
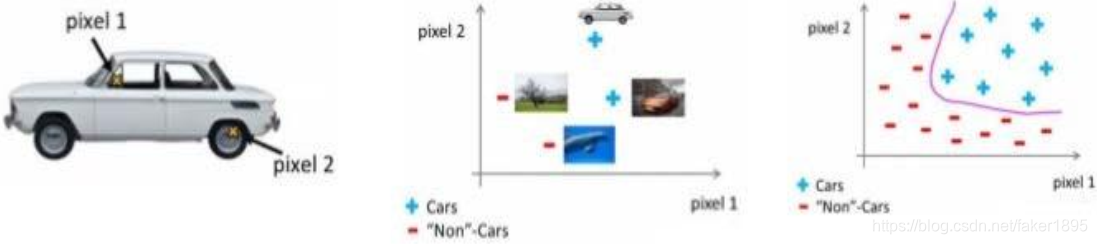
-
假使我們採用的都是 50x50 畫素的小圖片,並且我們將所有的畫素視為特徵,則會有2500 個特徵,如果我們要進一步將兩兩特徵組合構成一個多項式模型,則會有約 個(接近 3 百萬個)特徵。普通的邏輯迴歸模型,不能有效地處理這麼多的特徵,這時候我們需要神經網路。
模型展示
-
神經網路模型建立在很多神經元之上,每一個神經元又是一個個學習模型。這些神經元(也叫啟用單元,activation unit)採納一些特徵作為輸出,並且根據本身的模型提供一個輸出。
-
在神經網路中,引數又可被成為權重( weight)。
-
我們設計出了類似於神經元的神經網路,效果如下:
- 其中 是輸入單元( input units),我們將原始資料輸入給它們。
- 是中間單元,它們負責將資料進行處理,然後呈遞到下一層。
- 最後是輸出單元,它負責計算
。
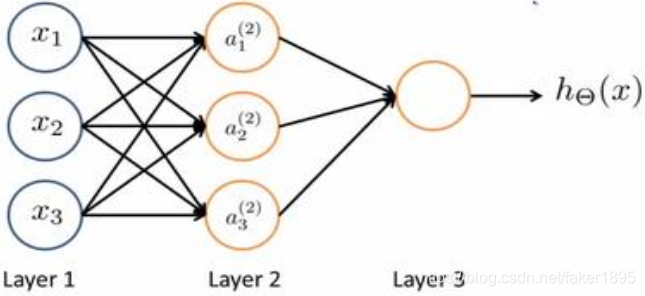
-
神經網路模型是許多邏輯單元按照不同層級組織起來的網路,每一層的輸出變數都是下一層的輸入變數。
-
下圖為一個 3 層的神經網路,第一層稱為輸入層( Input Layer),最後一層稱為輸出層( Output Layer),中間一層稱為隱藏層( Hidden Layers)。我們為每一層都增加一個偏差單位( bias unit):
-
代表第
層的第
個啟用單元。
代表從第
層對映到第
層時的權重的矩陣,例如
代表從第一層對映到第二層的權重的矩陣。其尺寸為:以第
層的啟用單元數量為行數,以第
層的啟用單元數加一為列數的矩陣。例如:下圖所示的神經網路中
的尺寸為 3*4。
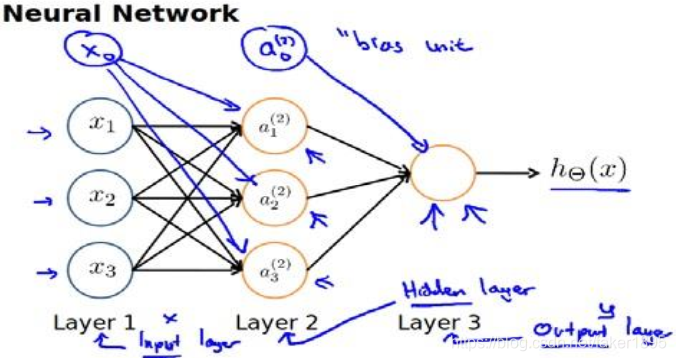
- 對於上圖所示的模型,啟用單元和輸出分別表達為:
- ;
- ;
-
代表第
層的第
個啟用單元。
代表從第
層對映到第
層時的權重的矩陣,例如
代表從第一層對映到第二層的權重的矩陣。其尺寸為:以第
層的啟用單元數量為行數,以第
層的啟用單元數加一為列數的矩陣。例如:下圖所示的神經網路中
的尺寸為 3*4。