
linux top命令檢視記憶體及多核CPU的使用
檢視多核CPU命令
mpstat -P ALL 和 sar -P ALL
說明:sar -P ALL > aaa.txt 重定向輸出內容到檔案 aaa.txt
top命令
經常用來監控linux的系統狀況,比如cpu、記憶體的使用,程式設計師基本都知道這個命令,但比較奇怪的是能用好它的人卻很少,例如top監控檢視中記憶體數值的含義就有不少的曲解。
本文通過一個執行中的WEB伺服器的top監控截圖,講述top檢視中的各種資料的含義,還包括檢視中各程序(任務)的欄位的排序。
top進入檢視
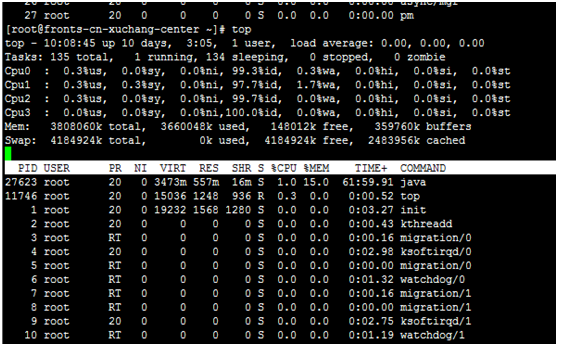
第一行:
10:08:45 — 當前系統時間
10 days, 3:05 — 系統已經運行了10天3小時5分鐘(在這期間沒有重啟過)
1 users — 當前有1個使用者登入系統
load average: 0.00, 0.00, 0.00 — load average後面的三個數分別是1分鐘、5分鐘、15分鐘的負載情況。
load average資料是每隔5秒鐘檢查一次活躍的程序數,然後按特定演算法計算出的數值。如果這個數除以邏輯CPU的數量,結果高於5的時候就表明系統在超負荷運轉了。
第二行:
Tasks — 任務(程序),系統現在共有135個程序,其中處於執行中的有1個,134個在休眠(sleep),stoped狀態的有0個,zombie狀態(殭屍)的有0個。
第三行:cpu狀態
0.3% us — 使用者空間佔用CPU的百分比。
0.0% sy — 核心空間佔用CPU的百分比。
0.0% ni — 改變過優先順序的程序佔用CPU的百分比
99.7% id — 空閒CPU百分比
0.0% wa — IO等待佔用CPU的百分比
0.0% hi — 硬中斷(Hardware IRQ)佔用CPU的百分比
0.0% si — 軟中斷(Software Interrupts)佔用CPU的百分比
在這裡CPU的使用比率和windows概念不同,如果你不理解使用者空間和核心空間,需要充充電了。
第四行:記憶體狀態
3808060k total — 實體記憶體總量(4GB)
3660048k used — 使用中的記憶體總量(3.6GB)
148012k free — 空閒記憶體總量(148M)
359760k buffers — 快取的記憶體量 (359M)
第五行:swap交換分割槽
4184924k total — 交換區總量(4G)
0k used — 使用的交換區總量(0M)
4184924k free — 空閒交換區總量(4G)
2483956k cached — 緩衝的交換區總量(2483M)
第四行中使用中的記憶體總量(used)指的是現在系統核心控制的記憶體數,空閒記憶體總量(free)是核心還未納入其管控範圍的數量。納入核心管理的記憶體不見得都在使用中,還包括過去使用過的現在可以被重複利用的記憶體,核心並不把這些可被重新使用的記憶體交還到free中去,因此在linux上free記憶體會越來越少,但不用為此擔心。
如果出於習慣去計算可用記憶體數,這裡有個近似的計算公式:第四行的free + 第四行的buffers + 第五行的cached,按這個公式此臺伺服器的可用記憶體:148M+259M+2483M = 2990M。
對於記憶體監控,在top裡我們要時刻監控第五行swap交換分割槽的used,如果這個數值在不斷的變化,說明核心在不斷進行記憶體和swap的資料交換,這是真正的記憶體不夠用了。
第六行是空行
第七行以下:各程序(任務)的狀態監控
PID — 程序id
USER — 程序所有者
PR — 程序優先順序
NI — nice值。負值表示高優先順序,正值表示低優先順序
VIRT — 程序使用的虛擬記憶體總量,單位kb。VIRT=SWAP+RES
RES — 程序使用的、未被換出的實體記憶體大小,單位kb。RES=CODE+DATA
SHR — 共享記憶體大小,單位kb
S — 程序狀態。D=不可中斷的睡眠狀態 R=執行 S=睡眠 T=跟蹤/停止 Z=殭屍程序
%CPU — 上次更新到現在的CPU時間佔用百分比
%MEM — 程序使用的實體記憶體百分比
TIME+ — 程序使用的CPU時間總計,單位1/100秒
COMMAND — 程序名稱(命令名/命令列)
多U多核CPU監控
在top基本檢視中,按鍵盤數字“1”,可監控每個邏輯CPU的狀況:
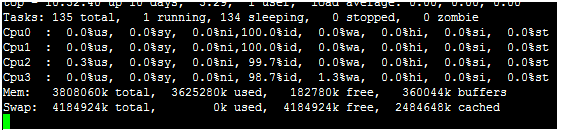
觀察上圖,伺服器有4個邏輯CPU,實際上是1個物理CPU。
如果不按1,則在top視圖裡面顯示的是所有cpu的平均值。
程序欄位排序
預設進入top時,各程序是按照CPU的佔用量來排序的,在【top檢視 01】中程序ID為14210的java程序排在第一(cpu佔用100%),程序ID為14183的java程序排在第二(cpu佔用12%)。可通過鍵盤指令來改變排序欄位,比如想監控哪個程序佔用MEM最多,我一般的使用方法如下:
1. 敲擊鍵盤“b”(開啟/關閉加亮效果),top的檢視變化如下:

我們發現程序id為12363的“top”程序被加亮了,top程序就是檢視第二行顯示的唯一的執行態(runing)的那個程序,可以通過敲擊“y”鍵關閉或開啟執行態程序的加亮效果。
2. 敲擊鍵盤“x”(開啟/關閉排序列的加亮效果),top的檢視變化如下:
可以看到,top預設的排序列是“%CPU”。
3. 通過”shift + >”或”shift + <”可以向右或左改變排序列,下圖是按一次”shift + >”的效果圖:

檢視現在已經按照%MEM來排序了。
改變程序顯示欄位
1. 敲擊“f”鍵,top進入另一個檢視,在這裡可以編排基本檢視中的顯示欄位:
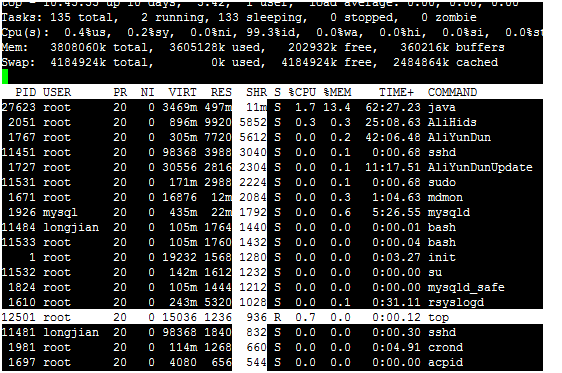
這裡列出了所有可在top基本檢視中顯示的程序欄位,有”*”並且標註為大寫字母的欄位是可顯示的,沒有”*”並且是小寫字母的欄位是不顯示的。如果要在基本檢視中顯示“CODE”和“DATA”兩個欄位,可以通過敲擊“r”和“s”鍵:
2. “回車”返回基本檢視,可以看到多了“CODE”和“DATA”兩個欄位:

top命令的補充
top命令是Linux上進行系統監控的首選命令,但有時候卻達不到我們的要求,比如當前這臺伺服器,top監控有很大的侷限性。這臺伺服器執行著websphere叢集,有兩個節點服務,就是【top檢視 01】中的老大、老二兩個java程序,top命令的監控最小單位是程序,所以看不到我關心的java執行緒數和客戶連線數,而這兩個指標是java的web服務非常重要的指標,通常我用ps和netstate兩個命令來補充top的不足。
監控java執行緒數:
ps -eLf | grep java | wc -l
監控網路客戶連線數:
netstat -n | grep tcp | grep 偵聽埠 | wc -l
上面兩個命令,可改動grep的引數,來達到更細緻的監控要求。
在Linux系統“一切都是檔案”的思想貫徹指導下,所有程序的執行狀態都可以用檔案來獲取。系統根目錄/proc中,每一個數字子目錄的名字都是執行中的程序的PID,進入任一個程序目錄,可通過其中檔案或目錄來觀察程序的各項執行指標,例如task目錄就是用來描述程序中執行緒的,因此也可以通過下面的方法獲取某程序中執行中的執行緒數量(PID指的是程序ID):
ls /proc/PID/task | wc -l
在linux中還有一個命令pmap,來輸出程序記憶體的狀況,可以用來分析執行緒堆疊:
pmap PID
大家都熟悉Linux下可以通過top命令來檢視所有程序的記憶體,CPU等資訊。除此之外,還有其他一些命令,可以得到更詳細的資訊,例如程序相關
cat /proc/your_PID/status
通過top或ps -ef | grep '程序名' 得到程序的PID。該命令可以提供程序狀態、檔案控制代碼數、記憶體使用情況等資訊。
記憶體相關
vmstat -s -S M
該可以檢視包含記憶體每個專案的報告,通過-S M或-S k可以指定檢視的單位,預設為kb。結合watch命令就可以看到動態變化的報告了。
也可用 cat /proc/meminfo
要看cpu的配置資訊可用
cat /proc/cpuinfo
它能顯示諸如CPU核心數,時鐘頻率、CPU型號等資訊。
要檢視cpu波動情況的,尤其是多核機器上,可使用
mpstat -P ALL 10
該命令可間隔10秒鐘取樣一次CPU的使用情況,每個核的情況都會顯示出來,例如,每個核的idle情況等。
只需檢視均值的,可用
iostat -c
IO相關
iostat -P ALL
該命令可檢視所有裝置使用率、讀寫位元組數等資訊。
另外,htop ,有時間可以用一下。
# 總核數 = 物理CPU個數 X 每顆物理CPU的核數
# 總邏輯CPU數 = 物理CPU個數 X 每顆物理CPU的核數 X 超執行緒數
# 檢視物理CPU個數
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 檢視每個物理CPU中core的個數(即核數)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 檢視邏輯CPU的個數
cat /proc/cpuinfo| grep "processor"| wc -l
檢視CPU資訊(型號)
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c