
使用gym庫Classic control實現deep Q learning
阿新 • • 發佈:2018-12-06
本文轉自:https://blog.csdn.net/winycg/article/details/79468320
target="_blank">https://gym.openai.com/envs/ OpenAI gym官網
https://github.com/openai/gym#installation gym安裝教程
http://blog.csdn.net/cs123951/article/details/77854453 MountainCar原理參考
OpenAI gym提供了強化學習時的環境模組,使得我們實現強化學習演算法的時候無需關注於模擬環境的實現。
CartPole例項
運載體在一根杆子下無摩擦的跟蹤。系統通過施加+1和-1推動運載體。杆子的搖擺在初始時垂直的,目標是阻止它掉落運載體。每一步杆子保持垂直可以獲得+1的獎勵。episode將會終結於杆子的搖擺幅度超過了離垂直方向的15°或者是運載體偏移初始中心超過2.4個單位。
使用DQN程式碼測試CartPole:
import numpy as np
import random
import tensorflow as tf
import gym
max_episode = 100
env = gym.make('CartPole-v0' MountainCar例項
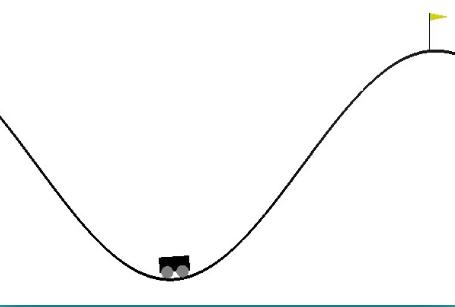
car的軌跡是一維的,定位在兩山之間,目標是爬上右邊的山頂。可是car的發動機不足以一次性攀登到山頂,唯一的方式是car來回擺動增加動量。
有3個動作:向前、不動和向後。狀態有2個:位置position和速度velocity。position的值在最低點處為-0.5左右,左邊的坡頂為-1.2,右邊與之相對應的高度位置為0,小黃旗位置為0.5。reward的值只有-1,步數越少到達終點,reward越大。
自定義reward:高度越高,reward越大,因為左邊高度高了,可以積攢的動量越大。所以可設為reward=abs(position+0.5)
RL = DeepQNetwork(n_actions=env.action_space.n,
n_features=env.observation_space.shape[0])
total_step = 0
for episode in range(max_episode):
observation = env.reset()
episode_reward = 0
while True:
env.render() # 表達環境
action = RL.choose_action_by_epsilon_greedy(observation)
observation_, reward, done, info = env.step(action)
#
position, velocity = observation_
reward=abs(position+0.5)
RL.store_transition(observation, action, reward, observation_)
if total_step > 100:
cost_ = RL.learn()
cost.append(cost_)
episode_reward += reward
observation = observation_
if done:
print('episode:', episode,
'episode_reward %.2f' % episode_reward,
'epsilon %.2f' % RL.epsilon)
break
total_step += 1
plt.plot(np.arange(len(cost)), cost)
plt.show()

更多案例請關注“思享會Club”公眾號或者關注思享會部落格:http://gkhelp.cn/
