
07-Hive高階查詢order by、group by
宣告:未經本人允許,不得轉載哦!
哈嘍,大家好。這兩天就要高考了,我原本是一名物理老師,這一屆初高中的學生帶完,估計就要開始找大資料崗位的工作了。目前掌握的是技能有java+linux++mysql+hadoop+hive+hbase,正在學習的是shell,計劃2016年接著要學習的是scala+spark。祝我好運吧。
今天我們一起來學習的是【Hive高階查詢group、order語法】。話不多說,咱們開始吧。
1 Hive的高階查詢操作有很多,主要有:
group by #按K來把資料進行分組
order by #全域性排序
join #兩個表進行連線
distribute by 這些操作其底層實現的都是mapreduce.
2 幾個簡單得聚合操作
count計數
count(*) count(1) count(col)
sum求和
sum(可轉成數字的值)返回bigint
sum(col)+cast(1 as bigint)
avg 3 order by
這個函式的功能是:按照某些欄位排序
樣例是:
select col1,other...
from table
where condition
order by col1,col2[asc|desc]關於order by值得注意的是:
order by 後面可以有多列進行排序,預設按字典排序;
order by為全域性排序;
order by需要reduce操作,且只有一個reduce,與配置有關。
4好的,接下來我們來實戰一下:建立一個M表。
hive> create table M(
> col string,
> col2 string
> )
> row format delimited fields terminated by '\t'
> lines terminated by '\n'
> stored as textfile;
OK
Time taken: 0.283 seconds
hive> 載入本地的資料進入M表中:
hive> load data local inpath '/usr/host/M' into table M;
Copying data from file:/usr/host/M
Copying file: file:/usr/host/M
Loading data to table default.m
OK
Time taken: 0.721 seconds
hive> 接下來進行查詢:
hive> select * from M;
OK
A 1
B 5
B 2
C 3
Time taken: 0.288 seconds
hive> select * from M order by col desc,col2 asc;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 1
2016-06-06 01:28:20,284 null map = 0%, reduce = 0%
2016-06-06 01:28:40,233 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:43,409 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:44,480 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:45,560 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:46,621 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:47,676 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:48,753 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:49,831 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:50,918 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:51,987 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:53,041 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:54,137 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:55,198 null map = 100%, reduce = 0%, Cumulative CPU 1.18 sec
2016-06-06 01:28:56,242 null map = 100%, reduce = 100%, Cumulative CPU 1.86 sec
2016-06-06 01:28:57,284 null map = 100%, reduce = 100%, Cumulative CPU 1.86 sec
2016-06-06 01:28:58,326 null map = 100%, reduce = 100%, Cumulative CPU 1.86 sec
MapReduce Total cumulative CPU time: 1 seconds 860 msec
Ended Job = job_1465200327080_0001
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
C 3
B 2
B 5
A 1
Time taken: 80.999 seconds
hive> 注意:(desc降序,asc升序)。很顯然col列是按照降序拍的,col2是按照升序排的,所以會出現
B 2
B 5另外:聽說生產中一般都不會在hive裡面做order by,會很慢,而是在hive裡面統計結果後匯入一部分去關係型資料庫中,在關係型資料庫中做order by,那就會很快。我覺得確實是如此,因為匯入mysql中查詢會快很多。

4 group by
這個函式的功能是:按照某些欄位的值進行分組,有相同值放到一起。
樣例:
select col1[,col2],count(1),sel_expr(聚合操作)
from table
where condition
group by col1[,col2]
[having]注意:
select 後面非聚合列必須出現在gruopby中
除了普通列就是一些聚合操作
groupby後面也可以跟表示式,比如substr(col)
我們來實際實驗一下:
hive> desc M;
OK
col string
col2 string
Time taken: 0.28 seconds
hive> select col from M group by col;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of **reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>**
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 1
2016-06-06 02:33:50,712 null map = 0%, reduce = 0%
2016-06-06 02:34:12,802 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:13,911 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:15,018 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:16,099 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:17,315 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:18,452 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:19,558 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:20,612 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:21,699 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:22,804 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:23,870 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:24,937 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:25,978 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:27,075 null map = 100%, reduce = 0%, Cumulative CPU 1.53 sec
2016-06-06 02:34:28,145 null map = 100%, reduce = 100%, Cumulative CPU 2.33 sec
2016-06-06 02:34:29,255 null map = 100%, reduce = 100%, Cumulative CPU 2.33 sec
MapReduce Total cumulative CPU time: 2 seconds 330 msec
Ended Job = job_1465200327080_0002
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
A
B
C
Time taken: 63.381 seconds
hive> 其實group by語句是可以去重的。
hive> select distinct col from M;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
16/06/06 02:36:49 INFO Configuration.deprecation: mapred.job.name is
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 1
2016-06-06 02:37:00,159 null map = 0%, reduce = 0%
2016-06-06 02:37:18,943 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:20,203 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:21,344 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:23,459 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:24,554 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:25,589 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:26,660 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:27,735 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:28,815 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:29,906 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:30,989 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:32,054 null map = 100%, reduce = 0%, Cumulative CPU 1.1 sec
2016-06-06 02:37:33,111 null map = 100%, reduce = 100%, Cumulative CPU 1.96 sec
2016-06-06 02:37:34,223 null map = 100%, reduce = 100%, Cumulative CPU 1.96 sec
MapReduce Total cumulative CPU time: 1 seconds 960 msec
Ended Job = job_1465200327080_0003
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
A
B
C
Time taken: 55.682 secondsselect distinct col from M; //(跟上一句話是一樣的結果),可以用來去重hive> select col from m group by col,col2;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 1
2016-06-06 02:38:48,837 null map = 0%, reduce = 0%
2016-06-06 02:39:06,717 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:08,045 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:09,271 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:10,428 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:11,590 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:12,696 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:13,765 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:14,879 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:15,949 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:17,099 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:18,173 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:19,281 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:20,357 null map = 100%, reduce = 0%, Cumulative CPU 1.24 sec
2016-06-06 02:39:21,420 null map = 100%, reduce = 100%, Cumulative CPU 2.05 sec
2016-06-06 02:39:22,560 null map = 100%, reduce = 100%, Cumulative CPU 2.05 sec
MapReduce Total cumulative CPU time: 2 seconds 50 msec
Ended Job = job_1465200327080_0004
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
A
B
B
C
Time taken: 56.956 seconds
hive> 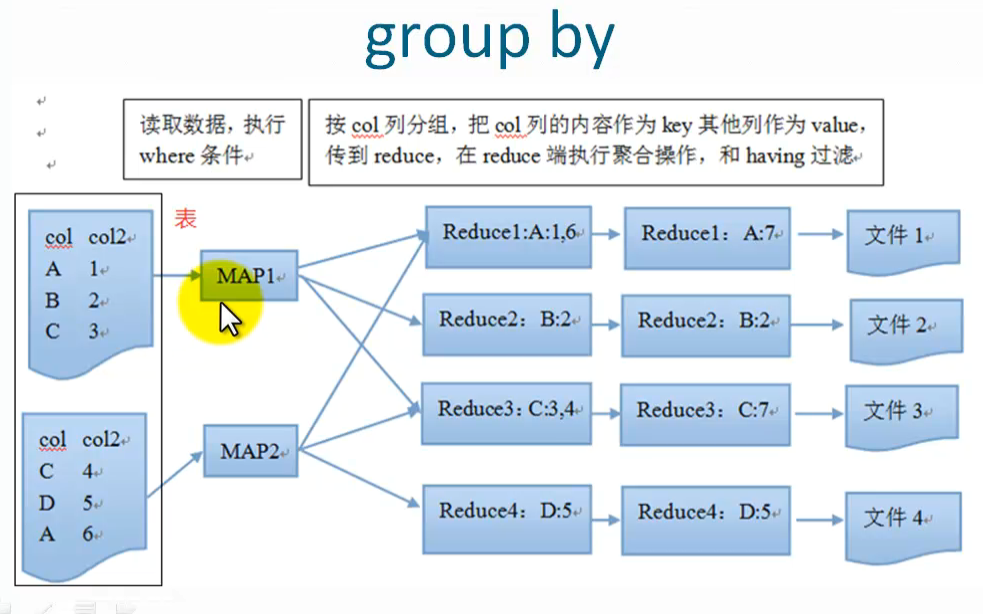
5 特性:
使用了reduce操作,受限於reduce數量,設定reduce引數mared.reduce.tasks
輸出檔案個數與reduce數相同,檔案大小與reduce處理的資料量有關
**問題:網路負載過重;
資料傾斜,優化引數**:hive.groupby.skewindata
6 什麼叫資料傾斜呢?
可以這麼簡單理解比如說:如果說某一個K值資料量過大,如果有10個reducer,其中9個數據量不大,很快執行完了,剩下一個資料量巨大,那麼這9個就會等這一個reducer執行完。換句話說就是處理某值的reduce灰常耗時。
解決思路:Hive的執行是分階段的,map處理資料量的差異取決於上一個stage的reduce輸出,所以如何將資料均勻的分配到各個reduce中,就是解決資料傾斜的根本所在。
set mapred.reduce.task=5;
select * from M order by col desc,col asc;
set hive.groupby.skewindata=true;//避免資料傾斜,total job 變為了2個,這個引數是有用的,啟用兩個job,避免資料傾斜
select country,count(1) as num from city1 group by country;驗證一下:
hive> set hive.groupby.skewindata=true;
hive> select country,count(1) as num from city1 group by country;
Total MapReduce jobs = 2
Launching Job 1 out of 2
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 1
2016-06-06 03:03:27,536 null map = 0%, reduce = 0%
2016-06-06 03:03:45,874 null map = 100%, reduce = 0%
2016-06-06 03:04:00,051 null map = 100%, reduce = 100%, Cumulative CPU 2.72 sec
2016-06-06 03:04:01,156 null map = 100%, reduce = 100%, Cumulative CPU 2.72 sec
2016-06-06 03:04:02,280 null map = 100%, reduce = 100%, Cumulative CPU 2.72 sec
MapReduce Total cumulative CPU time: 2 seconds 720 msec
Ended Job = job_1465200327080_0005
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
Launching Job 2 out of 2
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
16/06/06 03:04:13 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
16/06/06 03:04:13 INFO Configuration.deprecation: mapred.system