
4、【Python】Python 3入門(模組/面向物件/錯誤和異常/檔案操作/序列化/命名規範)
一、模組
編寫模組有很多種方法,其中最簡單的一種便是建立一個包含函式與變數、以 .py 為字尾的檔案。
另一種方法是使用撰寫 Python 直譯器本身的本地語言來編寫模組。舉例來說,你可以使用 C 語言來撰寫 Python 模組,並且在編譯後,你可以通過標準 Python 直譯器在你的 Python 程式碼中使用它們。
模組是一個包含所有你定義的函式和變數的檔案,其後綴名是.py。模組可以被別的程式引入,以使用該模組中的函式等功能。這也是使用 Python 標準庫的方法。
當直譯器遇到 import 語句,如果模組在當前的搜尋路徑就會被匯入。
搜尋路徑是一個直譯器會先進行搜尋的所有目錄的列表。如想要匯入模組,需要把命令放在指令碼的頂端。
一個模組只會被匯入一次,這樣可以防止匯入模組被一遍又一遍地執行。
搜尋路徑被儲存在 sys 模組中的 path 變數。當前目錄指的是程式啟動的目錄。
1、匯入模組
import module1[, module2[, ... moduleN]]
從模組中匯入一個指定的部分到當前命名控制元件中:
from modname import name1[, name2[, ... nameN]]
把一個模組的所有內容全都匯入當前的名稱空間:
from 2、__name__屬性
每個模組都有一個 name 屬性,當其值是 ‘main’ 時,表明該模組自身在執行,否則是被引入。
一個模組被另一個程式第一次引入時,其主程式將執行。如果我們想在模組被引入時,模組中的某一程式塊不執行,我們可以用 name 屬性來使該程式塊僅在該模組自身執行時執行。
if __name__ == '__main__':
print('程式自身在執行')
else:
print('我來自另一模組')
3、dir函式
內建的函式 dir() 可以找到模組內定義的所有名稱。以一個字串列表的形式返回。
如果沒有給定引數,那麼 dir() 函式會羅列出當前定義的所有名稱。
在 Python 中萬物皆物件,int、str、float、list、tuple等內建資料型別其實也是類,也可以用 dir(int) 檢視 int 包含的所有方法。也可以使用 help(int) 檢視 int 類的幫助資訊。
4、包
包是一種管理 Python 模組名稱空間的形式,採用”點模組名稱”。
比如一個模組的名稱是 A.B, 那麼他表示一個包 A中的子模組 B 。
就好像使用模組的時候,你不用擔心不同模組之間的全域性變數相互影響一樣,採用點模組名稱這種形式也不用擔心不同庫之間的模組重名的情況。
在匯入一個包的時候,Python 會根據 sys.path 中的目錄來尋找這個包中包含的子目錄。
目錄只有包含一個叫做 init.py 的檔案才會被認作是一個包,主要是為了避免一些濫俗的名字(比如叫做 string)不小心的影響搜尋路徑中的有效模組。
最簡單的情況,放一個空的 init.py 檔案就可以了。當然這個檔案中也可以包含一些初始化程式碼或者為 all 變數賦值。
5、第三方模組
- easy_install 和 pip 都是用來下載安裝 Python 一個公共資源庫 PyPI 的相關資源包的,pip 是
easy_install 的改進版,提供更好的提示資訊,刪除 package 等功能。老版本的 python 中只有
easy_install,沒有pip。 - easy_install 打包和釋出 Python 包,pip 是包管理。
easy_install 的用法:
- 安裝一個包
easy_install 包名
easy_install "包名 == 包的版本"
- 升級一個包
easy_install -U "包名 >= 包的版本號"
pip 的用法:
- 安裝一個包
pip install 包名pip install 包名 == 包的版本號
- 升級一個包
pip install —upgrade 包名 >= 包的版本號
- 刪除一個包
pip uninstall 包名
- 以安裝包列表
pip list
二、面向物件
類與物件是面向物件程式設計的兩個主要方面。一個類(Class)能夠建立一種新的型別(Type),其中物件(Object)就是類的例項(Instance)。可以這樣來類比:你可以擁有型別 int 的變數,也就是說儲存整數的變數是 int 類的例項(物件)。
- 類(Class):用來描述具有相同的屬性和方法的物件的集合。它定義了該集合中每個物件所共有的屬性和方法。物件是類的例項。
- 方法:類中定義的函式。
- 類變數:類變數在整個例項化的物件中是公用的。類變數定義在類中且在函式體之外。類變數通常不作為例項變數使用。
- 資料成員:類變數或者例項變數用於處理類及其例項物件的相關的資料。
- 方法重寫:如果從父類繼承的方法不能滿足子類的需求,可以對其進行改寫,這個過程叫方法的覆蓋(override),也稱為方法的重寫。
- 例項變數:定義在方法中的變數,只作用於當前例項的類。
- 繼承:即一個派生類(derived class)繼承基類(base
class)的欄位和方法。繼承也允許把一個派生類的物件作為一個基類物件對待。例如,有這樣一個設計:一個Dog型別的物件派生自Animal類,這是模擬”是一個(is-a)”關係(例圖,Dog是一個Animal)。 - 例項化:建立一個類的例項,類的具體物件。
- 物件:通過類定義的資料結構例項。物件包括兩個資料成員(類變數和例項變數)和方法。
Python 中的類提供了面向物件程式設計的所有基本功能:類的繼承機制允許多個基類,派生類可以覆蓋基類中的任何方法,方法中可以呼叫基類中的同名方法。
物件可以包含任意數量和型別的資料。
1、self
self 表示的是當前例項,代表當前物件的地址。類由 self.class 表示。
self 不是關鍵字,其他名稱也可以替代,但 self 是個通用的標準名稱。
2、類
類由 class 關鍵字來建立。 類例項化後,可以使用其屬性,實際上,建立一個類之後,可以通過類名訪問其屬性。
3、物件方法
方法由 def 關鍵字定義,與函式不同的是,方法必須包含引數 self, 且為第一個引數,self 代表的是本類的例項。
3、類方法
裝飾器 @classmethod 可以將方法標識為類方法。類方法的第一個引數必須為 cls,而不再是 self。
4、靜態方法
裝飾器 @staticmethod 可以將方法標識為靜態方法。靜態方法的第一個引數不再指定,也就不需要 self 或 cls。
5、__init__方法
init 方法即構造方法,會在類的物件被例項化時先執行,可以將初始化的操作放置到該方法中。如果重寫了 init,例項化子類就不會呼叫父類已經定義的 init。
6、變數
類變數(Class Variable)是共享的(Shared)——它們可以被屬於該類的所有例項訪問。該類變數只擁有一個副本,當任何一個物件對類變數作出改變時,發生的變動將在其它所有例項中都會得到體現。
物件變數(Object variable)由類的每一個獨立的物件或例項所擁有。在這種情況下,每個物件都擁有屬於它自己的欄位的副本,也就是說,它們不會被共享,也不會以任何方式與其它不同例項中的相同名稱的欄位產生關聯。
在 Python 中,變數名類似 xxx 的,也就是以雙下劃線開頭,並且以雙下劃線結尾的,是特殊變數,特殊變數是可以直接訪問的,不是 private 變數,所以,不能用 name、score 這樣的變數名。
7、訪問控制
-
私有屬性
__private_attr:兩個下劃線開頭,宣告該屬性為私有,不能在類地外部被使用或直接訪問。 -
私有方法
__private_method:兩個下劃線開頭,宣告該方法為私有方法,只能在類的內部呼叫,不能在類地外部呼叫。
我們還認為約定,一個下劃線開頭的屬性或方法為受保護的。比如,_protected_attr、_protected_method。
8、繼承
類可以繼承,並且支援繼承多個父類。在定義類時,類名後的括號中指定要繼承的父類,多個父類之間用逗號分隔。
子類的例項可以完全訪問所繼承所有父類的非私有屬性和方法。
若是父類中有相同的方法名,而在子類使用時未指定,Python 從左至右搜尋,即方法在子類中未找到時,從左到右查詢父類中是否包含方法。
9、方法重寫
子類的方法可以重寫父類的方法。重寫的方法引數不強制要求保持一致,不過合理的設計都應該保持一致。
super() 函式可以呼叫父類的一個方法,以多繼承問題。
10、類的轉悠方法:
- init: 建構函式,在生成物件時呼叫
- del: 解構函式,釋放物件時使用
- repr: 列印,轉換
- setitem: 按照索引賦值
- getitem: 按照索引獲取值
- len: 獲得長度
- cmp: 比較運算
- call: 函式呼叫
- add: 加運算
- sub: 減運算
- mul: 乘運算
- div: 除運算
- mod: 求餘運算
- pow: 乘方
類的專有方法也支援過載。
11、例項
class Person:
"""人員資訊"""
# 姓名(共有屬性)
name = ''
# 年齡(共有屬性)
age = 0
def __init__(self, name='', age=0):
self.name = name
self.age = age
# 過載專有方法: __str__
def __str__(self):
return "這裡過載了 __str__ 專有方法, " + str({'name': self.name, 'age': self.age})
def set_age(self, age):
self.age = age
class Account:
"""賬戶資訊"""
# 賬戶餘額(私有屬性)
__balance = 0
# 所有賬戶總額
__total_balance = 0
# 獲取賬戶餘額
# self 必須是方法的第一個引數
def balance(self):
return self.__balance
# 增加賬戶餘額
def balance_add(self, cost):
# self 訪問的是本例項
self.__balance += cost
# self.__class__ 可以訪問類
self.__class__.__total_balance += cost
# 類方法(用 @classmethod 標識,第一個引數為 cls)
@classmethod
def total_balance(cls):
return cls.__total_balance
# 靜態方法(用 @staticmethod 標識,不需要類引數或例項引數)
@staticmethod
def exchange(a, b):
return b, a
class Teacher(Person, Account):
"""教師"""
# 班級名稱
_class_name = ''
def __init__(self, name):
# 第一種過載父類__init__()構造方法
# super(子類,self).__init__(引數1,引數2,....)
super(Teacher, self).__init__(name)
def get_info(self):
# 以字典的形式返回個人資訊
return {
'name': self.name, # 此處訪問的是父類Person的屬性值
'age': self.age,
'class_name': self._class_name,
'balance': self.balance(), # 此處呼叫的是子類過載過的方法
}
# 方法過載
def balance(self):
# Account.__balance 為私有屬性,子類無法訪問,所以父類提供方法進行訪問
return Account.balance(self) * 1.1
class Student(Person, Account):
"""學生"""
_teacher_name = ''
def __init__(self, name, age=18):
# 第二種過載父類__init__()構造方法
# 父類名稱.__init__(self,引數1,引數2,...)
Person.__init__(self, name, age)
def get_info(self):
# 以字典的形式返回個人資訊
return {
'name': self.name, # 此處訪問的是父類Person的屬性值
'age': self.age,
'teacher_name': self._teacher_name,
'balance': self.balance(),
}
# 教師 John
john = Teacher('John')
john.balance_add(20)
john.set_age(36) # 子類的例項可以直接呼叫父類的方法
print("John's info:", john.get_info())
# 學生 Mary
mary = Student('Mary', 18)
mary.balance_add(18)
print("Mary's info:", mary.get_info())
# 學生 Fake
fake = Student('Fake')
fake.balance_add(30)
print("Fake's info", fake.get_info())
# 三種不同的方式呼叫靜態方法
print("john.exchange('a', 'b'):", john.exchange('a', 'b'))
print('Teacher.exchange(1, 2)', Teacher.exchange(1, 2))
print('Account.exchange(10, 20):', Account.exchange(10, 20))
# 類方法、類屬性
print('Account.total_balance():', Account.total_balance())
print('Teacher.total_balance():', Teacher.total_balance())
print('Student.total_balance():', Student.total_balance())
# 過載專有方法
print(fake)
輸出:
John's info: {'name': 'John', 'age': 36, 'class_name': '', 'balance': 22.0}Mary's info: {'name': 'Mary', 'age': 18, 'teacher_name': '', 'balance': 18}Fake's info {'name': 'Fake', 'age': 18, 'teacher_name': '', 'balance': 30}john.exchange('a', 'b'): ('b', 'a')Teacher.exchange(1, 2) (2, 1)Account.exchange(10, 20): (20, 10)Account.total_balance(): 0Teacher.total_balance(): 20Student.total_balance(): 48這裡過載了 __str__ 專有方法, {'name': 'Fake', 'age': 18}
三、錯誤和異常
1、語法錯誤
SyntaxError 類表示語法錯誤,當直譯器發現程式碼無法通過語法檢查時會觸發的錯誤。語法錯誤是無法用 try…except…捕獲的。
>>>print:
>>> print:
File "<stdin>", line 1
print:
^
SyntaxError: invalid syntax
2、異常
即便程式的語法是正確的,在執行它的時候,也有可能發生錯誤。執行時發生的錯誤被稱為異常。 錯誤資訊的前面部分顯示了異常發生的上下文,並以呼叫棧的形式顯示具體資訊。
>>> 1 + '0'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'int' and 'str'
3、異常處理
Python 提供了 try … except … 的語法結構來捕獲和處理異常。try 語句執行流程大致如下:
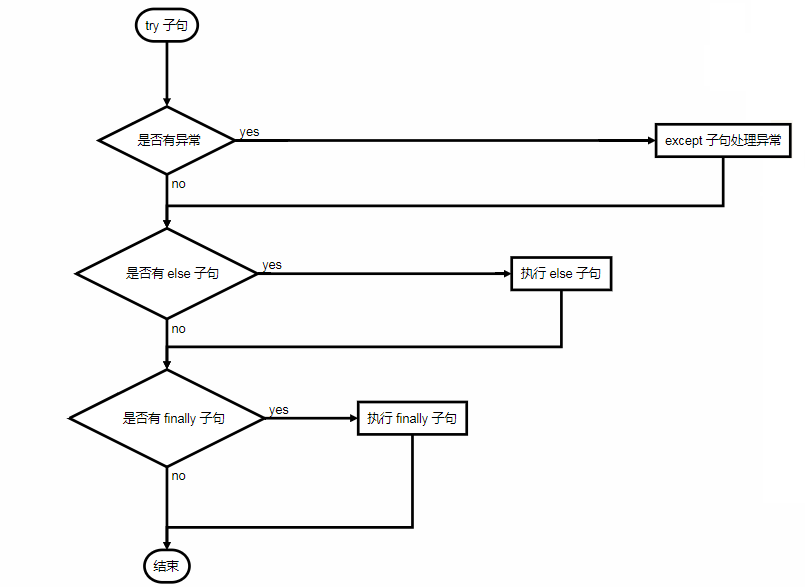
- 首先,執行 try 子句(在關鍵字 try 和關鍵字 except 之間的語句)
- 如果沒有異常發生,忽略 except 子句,try 子句執行後結束。
- 如果在執行 try 子句的過程中發生了異常,那麼 try 子句餘下的部分將被忽略。如果異常的型別和 except 之後的名稱相符,那麼對應的 except 子句將被執行。最後執行 try 語句之後的程式碼。
- 如果一個異常沒有與任何的 except 匹配,那麼這個異常將會傳遞給上層的 try 中。
- 一個 try 語句可能包含多個 except 子句,分別來處理不同的特定的異常。
- 最多隻有一個 except 子句會被執行。
- 處理程式將只針對對應的 try 子句中的異常進行處理,而不是其他的 try 的處理程式中的異常。
- 一個 except 子句可以同時處理多個異常,這些異常將被放在一個括號裡成為一個元組。
- 最後一個 except 子句可以忽略異常的名稱,它將被當作萬用字元使用。可以使用這種方法列印一個錯誤資訊,然後再次把異常丟擲。
- try except 語句還有一個可選的 else 子句,如果使用這個子句,那麼必須放在所有的 except 子句之後。這個子句將在try 子句沒有發生任何異常的時候執行。
- 異常處理並不僅僅處理那些直接發生在 try 子句中的異常,而且還能處理子句中呼叫的函式(甚至間接呼叫的函式)裡丟擲的異常。
- 不管 try 子句裡面有沒有發生異常,finally 子句都會執行。
- 如果一個異常在 try 子句裡(或者在 except 和 else 子句裡)被丟擲,而又沒有任何的 except 把它截住,那麼這個異常會在 finally 子句執行後再次被丟擲。
4、丟擲異常
使用 raise 語句丟擲一個指定的異常。
raise 唯一的一個引數指定了要被丟擲的異常。它必須是一個異常的例項或者是異常的類(也就是 Exception 的子類)。
如果你只想知道這是否丟擲了一個異常,並不想去處理它,那麼一個簡單的 raise 語句就可以再次把它丟擲。
5、自定義異常
可以通過建立一個新的異常類來擁有自己的異常。異常類繼承自 Exception 類,可以直接繼承,或者間接繼承。
當建立一個模組有可能丟擲多種不同的異常時,一種通常的做法是為這個包建立一個基礎異常類,然後基於這個基礎類為不同的錯誤情況建立不同的子類。
大多數的異常的名字都以”Error”結尾,就跟標準的異常命名一樣。
【例項】
import sys
class Error(Exception):
"""Base class for exceptions in this module."""
pass
# 自定義異常
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
try:
print('code start running...')
raise InputError('input()', 'input error')
# ValueError
int('a')
# TypeError
s = 1 + 'a'
dit = {'name': 'john'}
# KeyError
print(dit['1'])
except InputError as ex:
print("InputError:", ex.message)
except TypeError as ex:
print('TypeError:', ex.args)
pass
except (KeyError, IndexError) as ex:
"""支援同時處理多個異常, 用括號放到元組裡"""
print(sys.exc_info())
except:
"""捕獲其他未指定的異常"""
print("Unexpected error:", sys.exc_info()[0])
# raise 用於丟擲異常
raise RuntimeError('RuntimeError')
else:
"""當無任何異常時, 會執行 else 子句"""
print('"else" 子句...')
finally:
"""無論有無異常, 均會執行 finally"""
print('finally, ending')
四、檔案操作
1、開啟檔案
open() 函式用於開啟/建立一個檔案,並返回一個 file 物件:
opencv(filename, mode)
- filename:包含了你要訪問的檔名稱的字串值
- mode:決定了開啟檔案的模式:只讀,寫入,追加等
檔案開啟模式:

2、檔案物件方法
-
fileObject.close()
close() 方法用於關閉一個已開啟的檔案。關閉後的檔案不能再進行讀寫操作,否則會觸發 ValueError 錯誤。 close()方法允許呼叫多次。
當 file 物件,被引用到操作另外一個檔案時,Python 會自動關閉之前的 file 物件。 使用 close()方法關閉檔案是一個好的習慣。
-
fileObject.flush()
flush() 方法是用來重新整理緩衝區的,即將緩衝區中的資料立刻寫入檔案,同時清空緩衝區,不需要是被動的等待輸出緩衝區寫入。
一般情況下,檔案關閉後會自動重新整理緩衝區,但有時你需要在關閉前重新整理它,這時就可以使用 flush() 方法。
-
fileObject.fileno()
fileno() 方法返回一個整型的檔案描述符(file descriptor FD 整型),可用於底層作業系統的 I/O 操作。
-
fileObject.isatty()
isatty() 方法檢測檔案是否連線到一個終端裝置,如果是返回 True,否則返回 False。
-
next(iterator[,default])
Python 3 中的 File 物件不支援 next() 方法。 Python 3 的內建函式 next() 通過迭代器呼叫 next() 方法返回下一項。在迴圈中,next() 函式會在每次迴圈中呼叫,該方法返回檔案的下一行,如果到達結尾(EOF),則觸發 StopIteration。
-
fileObject.read()
read() 方法用於從檔案讀取指定的位元組數,如果未給定或為負則讀取所有。
-
fileObject.readline()
readline() 方法用於從檔案讀取整行,包括 “” 字元。如果指定了一個非負數的引數,則返回指定大小的位元組數,包括 “” 字元。
-
fileObject.readlines()
readlines() 方法用於讀取所有行(直到結束符 EOF)並返回列表,該列表可以由 Python 的 for… in … 結構進行處理。如果碰到結束符 EOF,則返回空字串。
-
fileObject.seek(offset[, whence])
seek() 方法用於移動檔案讀取指標到指定位置。
whence 的值, 如果是 0 表示開頭, 如果是 1 表示當前位置, 2 表示檔案的結尾。whence 值為預設為0,即檔案開頭。例如:
seek(x, 0):從起始位置即檔案首行首字元開始移動 x 個字元
seek(x, 1):表示從當前位置往後移動 x 個字元
seek(-x, 2):表示從檔案的結尾往前移動 x 個字元
-
fileObject.tell(offset[, whence])
tell() 方法返回檔案的當前位置,即檔案指標當前位置。
-
fileObject.truncate([size])
truncate() 方法用於從檔案的首行首字元開始截斷,截斷檔案為 size 個字元,無 size 表示從當前位置截斷;截斷之後 V 後面的所有字元被刪除,其中 Widnows 系統下的換行代表2個字元大小。
-
fileObject.write([str])
write() 方法用於向檔案中寫入指定字串。
在檔案關閉前或緩衝區重新整理前,字串內容儲存在緩衝區中,這時你在檔案中是看不到寫入的內容的。
如果檔案開啟模式帶 b,那寫入檔案內容時,str (引數)要用 encode 方法轉為 bytes 形式,否則報錯:TypeError:
a bytes-like object is required, not ‘str’。 -
fileObject.writelines([str])
writelines() 方法用於向檔案中寫入一序列的字串。這一序列字串可以是由迭代物件產生的,如一個字串列表。換行需要指定換行符 。
【例項】
filename = 'data.log'
# 開啟檔案(a+ 追加讀寫模式)
# 用 with 關鍵字的方式開啟檔案,會自動關閉檔案資源
with open(filename, 'w+', encoding='utf-8') as file:
print('檔名稱: {}'.format(file.name))
print('檔案編碼: {}'.format(file.encoding))
print('檔案開啟模式: {}'.format(file.mode))
print('檔案是否可讀: {}'.format(file.readable()))
print('檔案是否可寫: {}'.format(file.writable()))
print('此時檔案指標位置為: {}'.format(file.tell()))
# 寫入內容
num = file.write("第一行內容")
print('寫入檔案 {} 個字元'.format(num))
# 檔案指標在檔案尾部,故無內容
print(file.readline(), file.tell())
# 改變檔案指標到檔案頭部
file.seek(0)
# 改變檔案指標後,讀取到第一行內容
print(file.readline(), file.tell())
# 但檔案指標的改變,卻不會影響到寫入的位置
file.write('第二次寫入的內容')
# 檔案指標又回到了檔案尾
print(file.readline(), file.tell())
# file.read() 從當前檔案指標位置讀取指定長度的字元
file.seek(0)
print(file.read(9))
# 按行分割檔案,返回字串列表
file.seek(0)
print(file.readlines())
# 迭代檔案物件,一行一個元素
file.seek(0)
for line in file:
print(line, end='')
# 關閉檔案資源
if not file.closed:
file.close()
輸出:
檔名稱: data.log
檔案編碼: utf-8
檔案開啟模式: w+
檔案是否可讀: True
檔案是否可寫: True
此時檔案指標位置為: 0
寫入檔案 6 個字元
16
第一行內容
16
41
第一行內容
第二次
['第一行內容', '第二次寫入的內容']
第一行內容
第二次寫入的內容
五、序列化
在 Python 中 pickle 模組實現對資料的序列化和反序列化。pickle 支援任何資料型別,包括內建資料型別、函式、類、物件等。
1、方法
dump:將資料物件序列化後寫入檔案
pickle.dump(obj, file, protocol=None, fix_imports=True)
必填引數 obj 表示將要封裝的物件。 必填引數 file 表示 obj 要寫入的檔案物件,file 必須以二進位制可寫模式開啟,即wb。 可選引數 protocol 表示告知 pickle 使用的協議,支援的協議有 0,1,2,3,預設的協議是新增在 Python 3 中的協議3。
load:從檔案中讀取內容並反序列化
pickle.load(file, fix_imports=True, encoding='ASCII', errors='strict')
dumps:以位元組物件形式返回封裝的物件,不需要寫入檔案中
pickle.dumps(obj, protocol=None, fix_imports=True)
loads:從位元組物件中讀取被封裝的物件,並返回
pickle.loads(bytes_object, fix_imports=True, encoding='ASCII', errors='strict')
【例項】
import pickle
data = [1, 2, 3]
# 序列化資料並以位元組物件返回
dumps_obj = pickle.dumps(data)
print('pickle.dumps():', dumps_obj)
# 從位元組物件中反序列化資料
loads_data = pickle.loads(dumps_obj)
print('pickle.loads():', loads_data)
filename = 'data.log'
# 序列化資料到檔案中
with open(filename, 'wb') as file:
pickle.dump(data, file)
# 從檔案中載入並反序列化