
JVM調優(三)垃圾收集
前言
垃圾收集器要處理的基本問題是:
- 哪些物件需要回收?
- 何時回收這些物件?
- 如何回收這些物件?
回收演算法
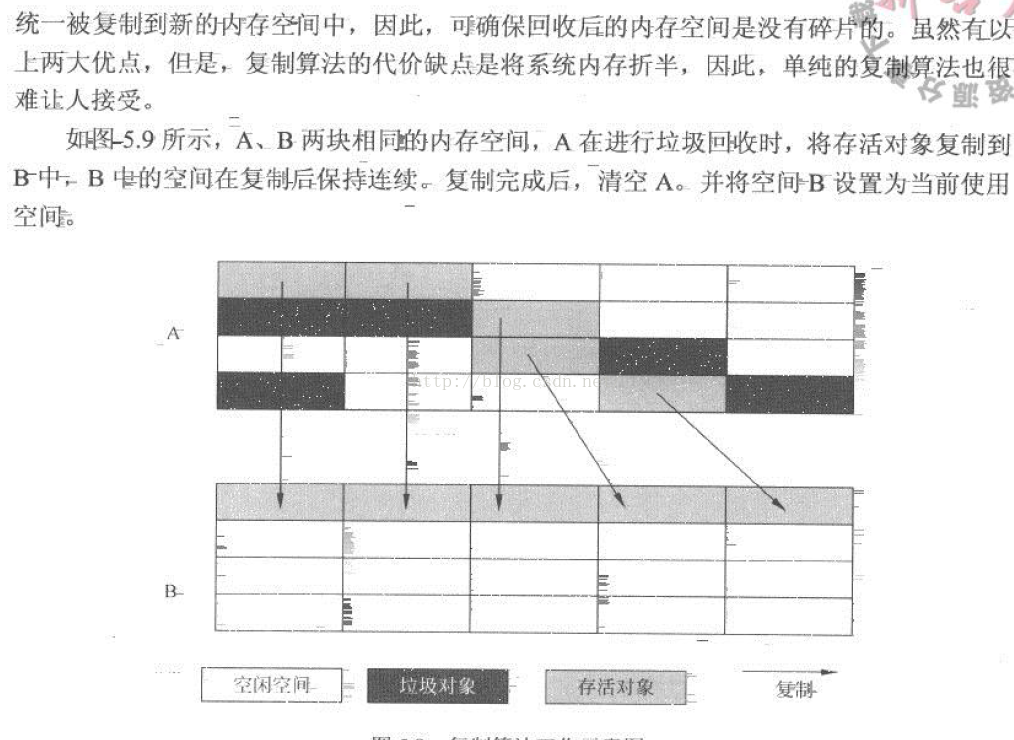
複製演算法(copying)
標記-壓縮演算法(mark-compact)



相關推薦
JVM調優(三)垃圾收集
前言 垃圾收集器要處理的基本問題是: 哪些物件需要回收? 何時回收這些物件? 如何回收這些物件? 回收演算法 複製演算法(copying) 標
JVM調優(三)程式程式碼調優
根據第一節所講的基礎知識,我們根據線上不同的異常情況做程式的優化。 CPU佔用高 us高 根據之前的分析,CPU us高的原因主要是執行執行緒無任何掛起動作,且一直執行,導致CPU沒有機會去排程執行其他的執行緒,造成執行緒餓死的現象。對於這種情況,常見的一種優化
深入理解JVM(三)——垃圾收集器
需要了解GC嗎? Q:需要了解GC和記憶體分配嗎? A:當需要排查各種記憶體溢位,記憶體洩露問題時;當垃圾回收成為系統高併發的瓶頸時 哪些記憶體需要回收? 程式計數器,虛擬機器棧,本地方法棧隨著執行緒生而生,執行緒滅而滅,棧幀隨著方法的進入和退出而進棧和出棧。基本上類結構確定下
JVM調優(4)之垃圾回收面臨的問題
如何區分垃圾 引用計數演算法: 來記錄一個物件被引用的次數,當引用計數器為0時,代表這個物件不再被使用。 優點:實現簡單,判斷效率也很高。 缺點:它很難解決物件之間相互迴圈引用的問題。 可達性分析演算法: 在主流的商用程式語言的主流實現都是通過可達性分析來判斷物件是否存活
JVM調優(3)之垃圾回收
從這篇開始我們開始探討一些jvm調優的問題。在jvm調優中一個離不開的重點是垃圾回收,當垃圾回收成為系統達到更高併發量的瓶頸時,我們就需要對jvm中如果進行“自動化”垃圾回收技術實施必要的監控和調節。 對於調優之前,我們必須要了解其執行原理,java 的垃圾收集Garbage Col
JVM調優(二)經驗參數設置
too 語言 相關 jdk5 nta 回收算法 from 情況 根據 調優設置具體解析 堆大小設置 JVM 中最大堆大小有三方面限制:相關操作系統的數據模型(32-bt還是64-bit)限制;系統的可用虛擬內存限制;系統的可用物理內存限制。32位系統下,一般限
JVM調優(四)常用調優方案
由於Full GC的成本要遠遠高於Minor GC,因此儘可能的將物件分配在新生代是一項明智的選擇。 大部分情況下,jvm會嘗試在eden區域分配物件,但是因為空間緊張等問題,很可能不得不將部分年輕物件提前向老年代壓縮。因此,可以為程式分配一個合理的新生代空間,以最大限度避免新物件直接進入老年代的情
JVM調優(二)JVM記憶體分配引數
設定最大堆記憶體 -Xmx引數指定。最大堆是新生代和老年代的大小之和的最大值,他是java應用程式的堆上限。 使用-Xmx可以設定系統的最大堆。 設定最小堆記憶體 使用-Xms可以設定系統的最小堆空間,也就是jvm啟動時,所佔據的作業系統的記憶體大小。 設定新生代
JVM調優(一)虛擬機器的記憶體模型
前言 Java虛擬機器記憶體模型是Java程式執行的基礎,JVM虛擬機器的記憶體模型如下圖: 程式計數器 程式計數器(Program Counter Register)是一塊很小的記憶體空間。由於java是支援多執行緒的語言,當執行緒數超過cpu的數量時,執行緒之間根據時間片輪詢搶
mysql效能調優(三)——列選取原則
1、列型別選擇 1)整型 > data、time > char、varchar > blob 整型、date、time運算快 &nb
JVM調優(7)問題定位和資訊列印
1.找到對應程序的pid ps -ef | grep tomcat #或者使用jps jps -lvm #檢視當前機器上執行的Java程序 jps命令格式如下: 命令格式 jps [options] [hostid] 注:如果不指定hostid就預設為當前主機或伺服器。
JVM調優(6)之引數配置
引數配置 堆大小設定 年輕代的設定很關鍵 JVM中最大堆大小有三方面限制: 相關作業系統的資料模型(32-bt還是64-bit)限制; 系統的可用虛擬記憶體限制; 系統的可用實體記憶體限制。 32位系統下,一般限制在1.5G~2G;64為
JVM調優(5)之分代
為什麼要分代 分代的垃圾回收策略,是基於這樣一個事實:不同的物件的生命週期是不一樣的。因此,不同生命週期的物件可以採取不同的收集方式,以便提高回收效率。 堆記憶體是虛擬機器管理的記憶體中最大的一塊,也是垃圾回收最頻繁的一塊區域,我們程式所有的物件例項都存放在堆記憶體中。給堆記憶體
JVM調優(2)之基本概念
資料型別 Java虛擬機器中,資料型別可以分為兩類:基本型別 和 引用型別。 基本型別的變數儲存原始值,即:他代表的值就是數值本身; 引用型別的變數儲存引用值。“引用值”代表了某個物件的引用,而不是物件本身,物件本身存放在這個引用值所表示的地址的位置。 基本型別包括:
JVM調優(1)之初見
基本結構 概述 這一節,主要來學習jvm的基本結構,也就是概述。說是概述,內容很多,而且概念量也很大,不過關於概念方面,你不用擔心,我完全有信心,讓概念在你的腦子裡變成圖形,所以只要你有耐心,仔細,認真,併發揮你的想象力,這一章之後你會充滿自信。當然,不是說看完本章,就對jvm瞭
JVM調優(二)——Linux下監控java執行緒
Linux環境下,當發現java程序佔用CPU資源非常高,且又要想更進一步查出哪一個java執行緒佔用了CPU資源時該如何做呢? 一、採用命令列形式檢視執行緒,最終用dump進行文字分析 1、top命令既可以看程序,又可以看執行緒 1、top命令找出佔用資源厲害
JVM調優(9)jstack定位死迴圈、執行緒阻塞、死鎖等問題
當我們執行java程式時,可能會出現死迴圈,IO阻塞,執行緒死鎖等問題,導致程式無法進行下去,但從程式碼上有無法確定問題出現的具體原因或者地方。可以使用JDK自帶的jstack工具去簡單定位; 死迴圈 程式如下: /** * @Author Ralph * 死迴圈定位
JVM調優(8)Java的記憶體洩漏
記憶體溢位和記憶體洩漏 記憶體溢位 out of memory,是指程式在申請記憶體時,沒有足夠的記憶體空間供其使用,出現out of memory; 記憶體洩露 memory leak,是指程式在申請記憶體後,無法釋放已申請的記憶體空間,一次記憶體洩露危害可以忽略,但記憶體洩露
spark效能調優(三)shuffle的map端記憶體緩衝reduce端記憶體佔比
效能優化 shuffle spark.shuffle.file.buffer,預設32k spark.shuffle.memoryFraction,0.2 map端記憶體緩衝,reduce端記憶體佔比;很多資料、網上視訊,都會說,這兩個引數, 是調節shuff
十八般武藝玩轉GaussDB(DWS)效能調優(三):好味道表定義
摘要:表結構設計是資料庫建模的一個關鍵環節,表定義好壞直接決定了叢集的有效容量以及業務查詢效能,本文從產品架構、功能實現以及業務特徵的角度闡述在GaussDB(DWS)的中表定義時需要關注的一些關鍵因素。 前言 GaussDB(DWS)是企業級的大規模並行處理關係型資料庫,採用Shared-nothing架構