
【ML_Algorithm 1】線性迴歸——演算法推導及程式碼實現
阿新 • • 發佈:2018-12-02
::::::::線性迴歸::::::::
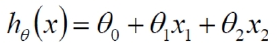 第一式
第一式
 第二式
第二式
從式一到式二,需要新增一個 項,其中
為
= 1 的常數量。只是為了容易寫成程式碼而已。

真實值=預測值+誤差(誤差是獨立且具有相同的分佈,通常認為服從均值為0的方差為 的高斯分佈。)

![]() 此式意思是要找到一個θ值使得該θ與x的組合完之後,使得組合值接近y真實值的概率最大化。
此式意思是要找到一個θ值使得該θ與x的組合完之後,使得組合值接近y真實值的概率最大化。
為了使得概率最大,我們用到了似然函式。

我們所希望的到的L(θ)的值是越大越好——代表了所有的y(i)與其真實值都是儘可能相等的。擊球什麼樣的θ可以使得L(θ)的整體值是最大的。
- 為了使得求解變得簡單一些,我們引入對數似然函式 l(θ) = ln L(θ)
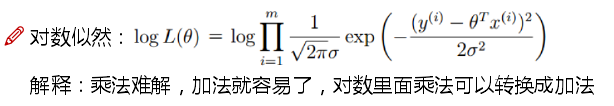

- 牢記,咱們要求的是似然函式L(θ)的值儘可能大,也就是使對數似然函式l(θ)的最大值,通過化簡的到上式,所以咱們要做的就是使右式J(θ)值最小。!
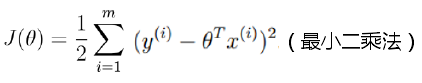
- 關於J(θ)的求解:

(上面第二步是對 θ 求偏導操作,矩陣求導不做解釋,不過可以從上圖看出一二)
#以下程式碼是對以上原理的簡單應用。目前我的環境尚未搭建妥當,所以還沒有去跑程式碼,先碼在這裡,等之後參考 import matplotlib.pyplot as plt import numpy as np from sklearn import datasets class LinearRegression(): def __init__(self): self.w = None def fit(self,X,y): #訓練階段 #Insert constant ones for bias weights print (X.shape) #x0 = 1 X=np.insert(X,0,1,axis=1) print (X.shape) #對X的轉置取逆操作。 X_ = np.linalg.iniv(X.T.dot(X)) self.w = X_.dot(X.T).dot(y) def predict(self,X): #測試階段 #Insert constant ones for bias weights X = np.insert(X,0,1,axis=1) y_pred = X.dot(self.w) return y_pred def mean_squared_error(y_true, ypred): mse = np.mean(np.power(y_true - y_pred, 2)) return mse def main(): #Load the diabetes dataset diabetes = datasets.load_diabetes() #Use only one feature X = diabetes.data[:, np.newaxis, 2] print(X.shape) #Split the data into training/testing sets x_train, x_test = X[:-20],X[-20:] #Split the targets into training/testing sets y_train, y_test = diabetes.target[:-20], diabetes.target[-20:] clf = LinearRegression() clf.fit(x_train, y_train) y_pred = clf.predict(x_test) #Print the mean squared error print ("Mean Souared Error:"mean_squared_error(y_test, y_pred)) #Plot the results plt.scatter(x_test[:,0], y_test, color='black') plt.plot(x_test[:,0], y_pred, color='blue',linewidth=3) plt.show()
參考:
機器學習課程——唐老師