
在cm安裝的大資料管理平臺中整合impala之後讀取hive表中的資料的設定(hue當中執行impala的資料查詢)
今天裝了CM叢集,在叢集當中集成了impala,hive。然後一直覺得認為impala自動共享hive的元資料,最後發現好像並不是這樣的,需要經過一個同步元資料的操作才能實現資料的同步。
具體的做法如下:
(1)安裝好hive和impala,然後在hive當中建立目標資料庫,建立一張表

[[email protected] ~]# impala-shell (通過shell的形式進入到impala的命令行當中)
2. 在Impala中同步元資料(這裡的元資料是hive當中的元資料)
[VM200-120:21000] > INVALIDATE METADATA;
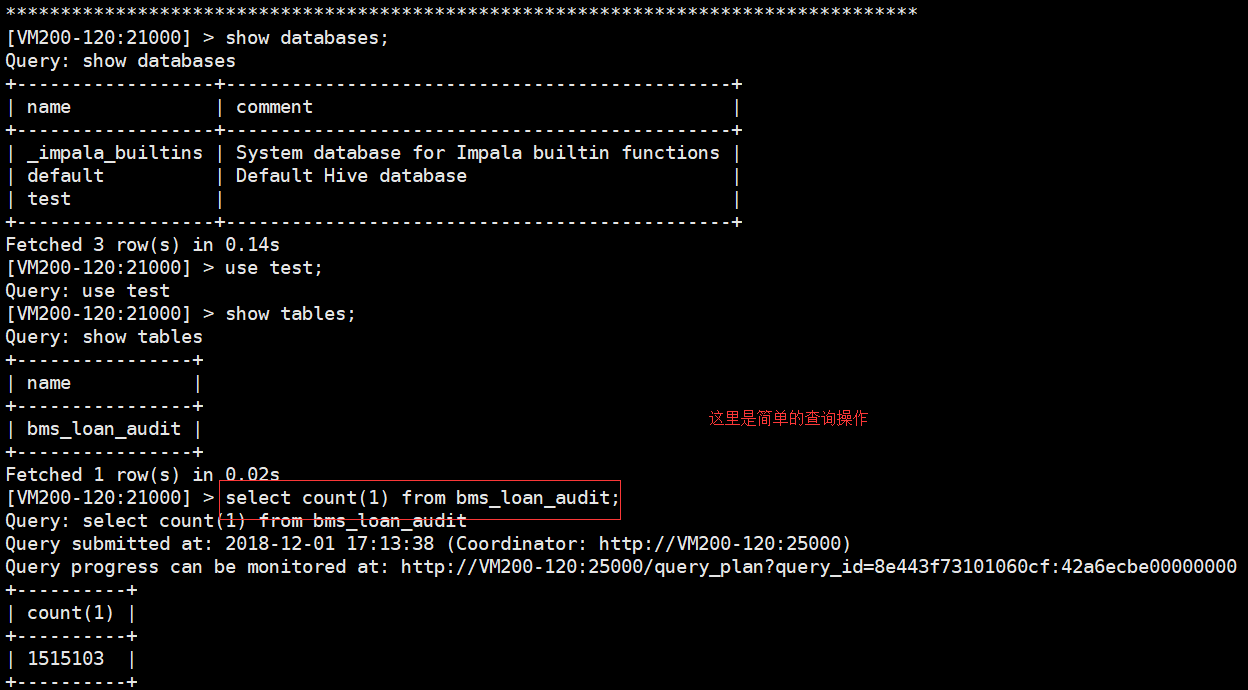
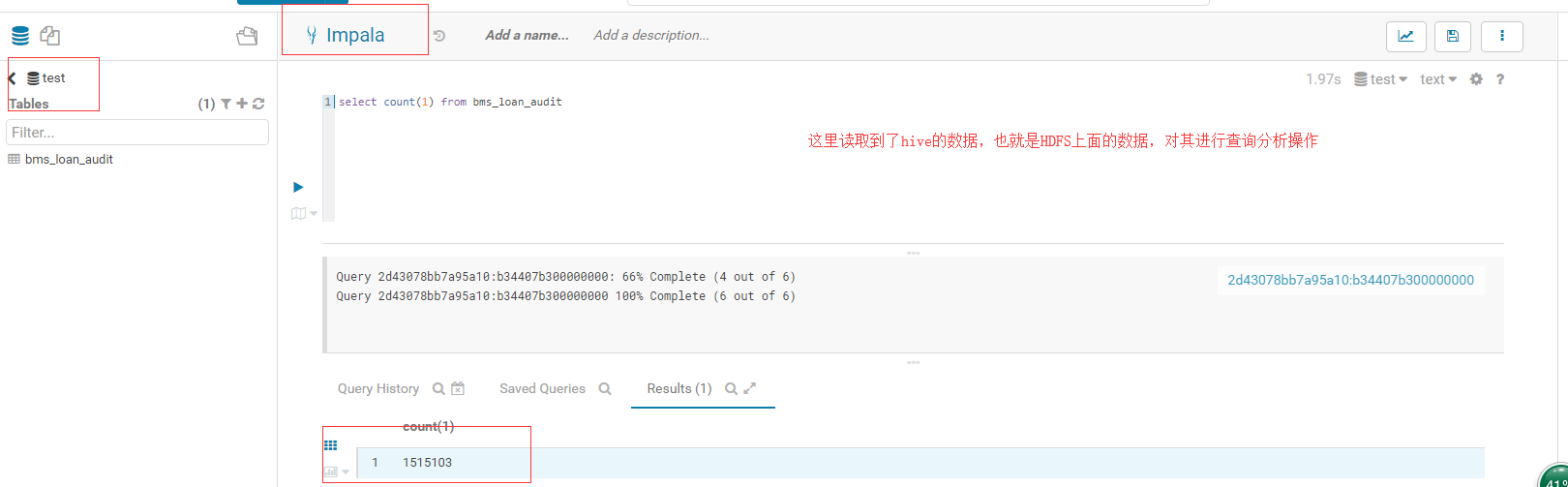
然後我們去hue的管理介面就可以看到impala當中已經同步了hive當中的資料。可以對資料進行操作了:
相關推薦
在cm安裝的大資料管理平臺中整合impala之後讀取hive表中的資料的設定(hue當中執行impala的資料查詢)
今天裝了CM叢集,在叢集當中集成了impala,hive。然後一直覺得認為impala自動共享hive的元資料,最後發現好像並不是這樣的,需要經過一個同步元資料的操作才能實現資料的同步。 具體的做法如下: (1)安裝好hive和impala,然後在hive當中建立目標資料庫,建立一張表
在cm安裝的大數據管理平臺中集成impala之後讀取hive表中的數據的設置(hue當中執行impala的數據查詢)
數據庫 自動 shell bubuko div 裏的 界面 行操作 .com 今天裝了CM集群,在集群當中集成了impala,hive。然後一直覺得認為impala自動共享hive的元數據,最後發現好像並不是這樣的,需要經過一個同步元數據的操作才能實現數據的同步。 具體的做
華宇大資料管理平臺通過中國資訊通訊研究院資料中心聯盟《Hadoop平臺基礎能力測試方法2.0》
近日,經中國資訊通訊研究院與資料中心聯盟評審認定,北京華宇資訊科技有限公司大資料管理平臺通過資料中心聯盟技術檔案《Hadoop平臺基礎能力測試方法2.0》要求的標準測試,該產品的運維、多租戶、可用性、安全性、相容性、擴充套件性、功能、易用性等8項指標均滿足大資料產品能力評測要求。 在這裡
大資料管理平臺-資料處理與資料集市
對於資料的理解,不同行業不同人都有不同的見解。從計算機角度來說,全部資料包括食品、文字、資料....都是1和0,或者說是高低電平。對於化學家來說所有的資料也是各種元素的不同狀態的組成,哪怕是高低電平儲存到硬體上也是si材料或記憶材料的行變。但對於廣大群眾、對於人本身,還是
智慧園區智慧管理平臺如何整合管控?
關於智慧園區 園區規模一般都很龐大,對於園區內的各項管控與治理,管理層在做出決策時往往會遇到很多困難。對於園區中人員管理與分工、資源整合與利用、硬體裝置管控以及處理各類問題等方面都是園區管理方所面臨的挑戰。 智慧園區是指通過各種資訊科技(比如網際網路、物聯網、大資料、人工智慧等)或者創新科技相結合,幫
安裝YApi 介面管理平臺
背景 在前後端分工合作的專案中,會出現一種尷尬局面。在專案進入研發階段初期,前端和後端人員約定api介面,請求引數,返回引數。往往兩端人員都在糾結模擬資料應該由誰來負責,但無論誰負責也好,必然會對專案產生一些冗餘的程式碼或檔案。而YApi正好為我們解決了這個大問題
基於ArcGIS10.0和Oracle10g的空間資料管理平臺一(C#開發)
很久沒有寫技術部落格了,記得最後一次在CSDN上寫技術部落格還是2010-08-09 00:31的時候了,那個時候還在學校,雖然大部分時間用於學習程式設計技術,但是還是有一點的時間和精力來寫一些自己學到的東西。學到的程式設計基礎知識在很多書籍和google都能很容易找到,所以
大資料||匯出Hive表中的資料
匯出Hive表中的資料方式由很多種。一下就介紹一下方式一:在hive的命令列內insert overwrite local directory '/opt/datas/hive_emp_exp' ROW FORMAT DELIMITED FIELDS TERMINATED
資料管理平臺DMP細緻研究——BlueKai
產品簡介BlueKai提供的服務是各種網際網路的流量資料, 它提供以下四項資料服務:1.資料管理平臺(DMP):用來幫助使用者組織並分析資料,功能包括:(1)收集整合線上線下的資料(使用者的自有資料)(2)對資料進行劃分(可以針對不同的營銷活動,如展示、搜尋、視訊、社交廣告等
使用spark將記憶體中的資料寫入到hive表中
使用spark將記憶體中的資料寫入到hive表中 hive-site.xml <?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configurati
利用sqoop指定列指定條件的方式將資料從mysql中增量匯入hive表中
========1、sqoop增量(指定列指定條件的方式增量匯入hive表中)匯入hive指令碼======= #!/bin/bash #Set the RDBMS connection params rdbms_ip=$1 rdbms_connect="jdbc:mysq
sql 中怎麼將A表插入B表中,,去除兩張 表中含有的重複資料
insert into B(欄位列表) select 欄位列表 from A where not exists(select * from B where a.keycol1 = b.keycol1) keycol1為A表和B 表中的欄位,可能帶有主鍵,可以此欄位來判斷A表和B表中是
資料結構實驗之連結串列七:單鏈表中重複元素的刪除(SDUT 2122)
#include <bits/stdc++.h> using namespace std; typedef struct node { int data; struct no
將表中的資料複製到另一個數據庫的表中
1. 在 src 目錄下建立 jdbc.properties #Oracle oracle.driver=oracle.jdbc.driver.OracleDriver oracle.jdbcUrl=jdbc:oracle:thin:@localhost:1521:orcl
shell指令碼載入資料檔案到hive表中
如果執行時間允許,還可以增加判斷hive表是否存在的。 #!/bin/ksh #------------------------------------------------------------------------------------- #-
使用shell將hdfs上的資料匯入到hive表中
days=($(seq 20150515 20150517)) hours=() for (( i=0; i<=23;++i)) do if [ $i -lt 10 ]; then
Hive 實戰練習(一)—按照日期將每天的資料匯入Hive表中
需求: 每天會產生很多的日誌檔案資料,有這麼一種需求:需要將每天產生的日誌資料在晚上12點鐘過後定時執行操作,匯入到Hive表中供第二天資料分析使用。要求建立分割槽表,並按照日期分割槽。資料檔案命名是以當天日期命名的,如2015-01-09.txt一、建立分割
將其他庫中的表的資料批量插入新增到另一個庫的表中
jkdb.factory中的jkdb為資料庫,factory為表名 兩張表的欄位和欄位型別需要一致。 INSERT INTO jkdb.factory SELECT id, name, sex
將一個庫裡的一張表中的資料複製到另一個庫的一張表中
首先,要在A和B資料庫中建立兩個同名同結構的表,其中B資料庫的表為目標表. private static void SQLCH() { SqlConnection ConectionFrom = new SqlConnection("Data So
用sqoop將mysql的資料匯入到hive表中,原理分析
Sqoop 將 Mysql 的資料匯入到 Hive 中 準備Mysql 資料 如圖所示,準備一張表,資料隨便造一些,當然我這裡的資料很簡單。 編寫命令 編寫引數檔案 個人習慣問題,我喜歡把引數寫到檔案裡,然後再命令列引用。 vim mysql-info, #