
==1==rcnn/fast_rcnn/faster_rcnn/mask_rcnn (目標檢測與目標例項分割 論文理解)
@TOC
原文連結 mask_rcnn paper
原文連結 r_cnn
原文連結 fast_rcnn
原文連結 FPN
opencv 4.0 程式碼-mask_rcnn
深度學習筆記1
R_CNN
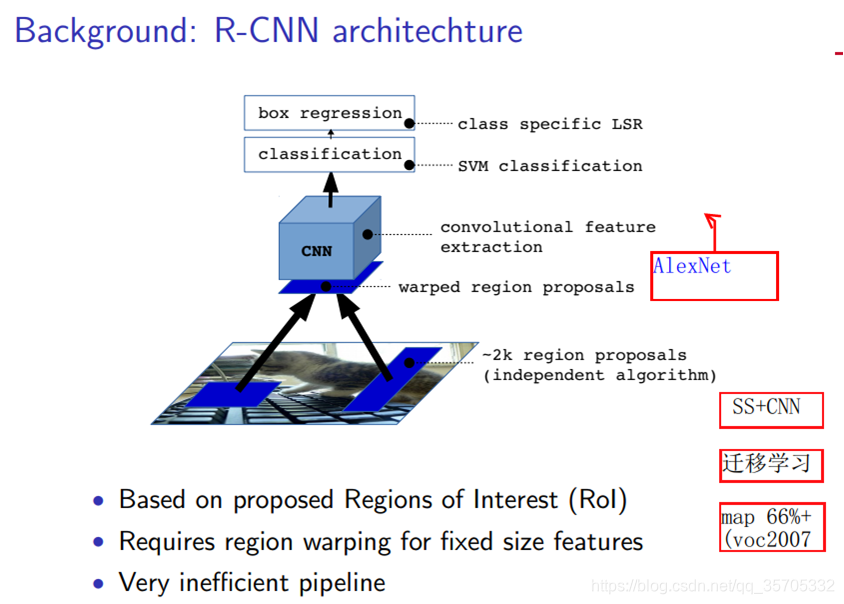
說明
Ross Girshick 2014年提出的,第一次用CNN卷積特徵做目標檢測,框圖如上。首先使用ss演算法進行候選框的提取,然後將每個候選框warped(將輸入的候選區尺寸統一為224*224,Alexnet輸入 尺寸要求),然後使用Alexnet CNN網路進行卷積特徵提取,然後進行類別區分與bounding box迴歸。創新點如下:
-
遷移學習
,這是最震撼我的一種想法,由於標註有位置資訊的資料集很少,PASCAL VOC只有20類,10k的資料量,對於深度學習網路很容易過擬合。
預訓練:遷移學習的想法就是先用ILSVR 目標識別資料(1000類 100萬的資料量)進行訓練CNN卷積特徵。
微調:然後在用少量的標有位置資訊的資料集進行訓練後面的FCN層(特定任務層);意思作者認為卷積特徵出來的資料是公用的基礎的資料,作為不同任務的區分層為全連線層。 -
ss演算法 根據圖片的 顏色 紋理 尺寸大小 吻合度特徵進行融合。在進行ss演算法前圖片先通過圖論的方法預分割成若干的區域。ss演算法的流程

-
問題1 一張圖大概有2000個候選區域,每一個區域都要進行一次CNN卷積,耗時耗記憶體;
-
問題2 訓練過程中,目標分類與定位是分開訓練的,先訓練目標分類再訓練目標定位。耗時
-
優點 MAP提高到66%,創新了之前一直使用人工提取特徵產生結果的精確度!!!!精確度提升了30%;
fast_rcnn
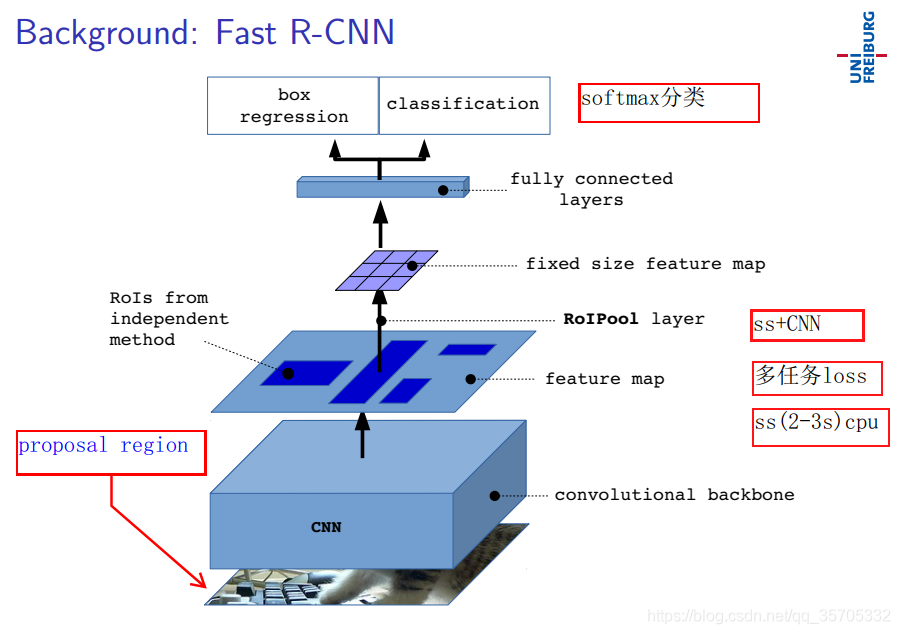
說明:可以輸入任意尺寸圖片,因為有ROIPOOL layer層。在R_CNN基礎上優化創新的,如上圖結構圖所示,將CNN卷積網路共享了,ss演算法在原圖上進行候選框的提取,在卷積後的特徵圖上進行對映的。對映關係為下采樣率,下采樣率由卷積的步長與池化層的步長決定的。舉例子,假如下采樣率為16則特徵上的一個畫素點對應原圖的16*16的矩陣區域。後續的步驟與R_CNN一致。
下面將闡述與R_CNN的區別:
-
線性分類器SVM分類器替換為softmax分類器
線性分類器SVM在SVM中,稱為Maximum Marginal;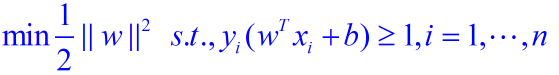
得分函式/score function:將原始資料對映到每個類的打分的函式f(xi,W,b)=Wxi+b
損失函式/loss function:用於量化模型預測結果和實際結果之間吻合度的函式;
決策面:Wxi+b=0(H1/H2的平行中間那條)
決策函式:f(x)=sign(Wxi+b ) 要麼+1 要麼-1 只能判斷是或不是
softmax:
logit=W‘x+b
得分函式:y=softmax(logit)
決策條件:生成的是一個K維的向量,k為類別數目。K類裡面哪個概率值大則歸為哪類。 -
多工loss 訓練一次完成目標檢測與定位多工loss 訓練一次完成目標檢測與定位
-
ROIPool layer從cnn卷積得到的特徵圖中選出了感興趣區域,又因為後面卷積層共享要將選出的區域進行尺寸統一(用池化的正規化)77;比如特徵圖上大小為2020,縮減為77,則劃分區域邊長為20/7=2(取整),22的區域裡max pool取最大值替代2*2區域
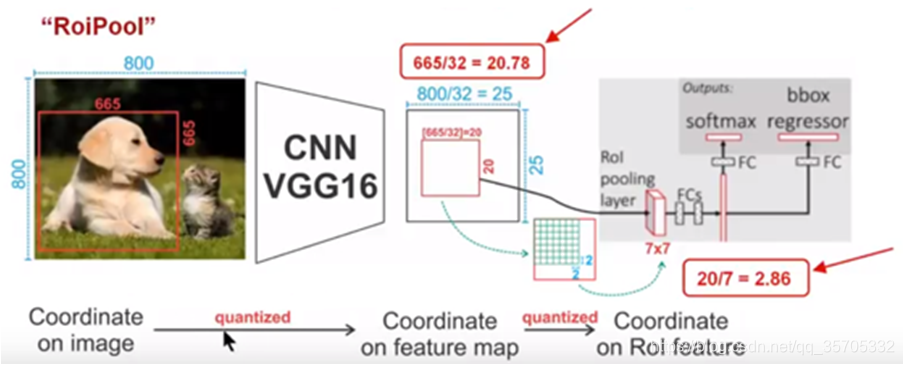
-
CNN卷積網路用VGG16替換了原來的Alexnet 卷積層更深,提取更多的語義特徵
-
指標整個過程耗時3s左右,ss區域提取就要2-3s(cpu),不能達到實時,但是比R_CNN訓練簡單 時間更短
faster_rcnn
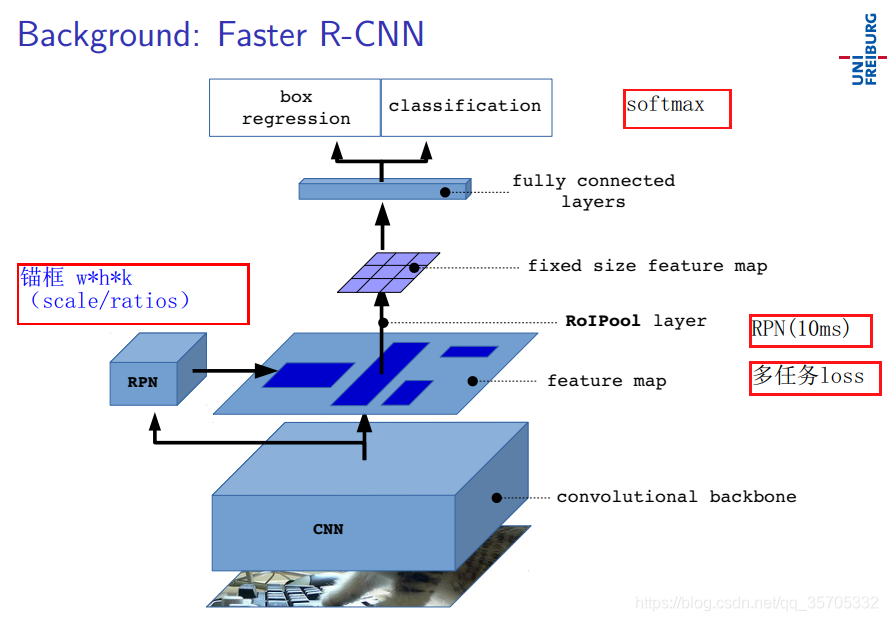
說明:可以輸入任意尺寸圖片,因為有ROIPOOL layer層。論文題目是toward real time 向著實時處理的目標去的,但是是非實時,5PFS。ss提取候選區很耗費時間,所以本文用RPN演算法替換了ss搜尋區域演算法。其他並沒有什麼變化。
闡述一下faster_rcnn的創新點(與fast_rcnn的區別)
RPN:即滑動窗篩選候選區,定義了三種尺寸,三種長寬比,也就是說同一個錨點有9個候選區域。對於mn整幅圖而言就會提取出Mn*9個候選框。sacle表示面積。ratios表示長寬比
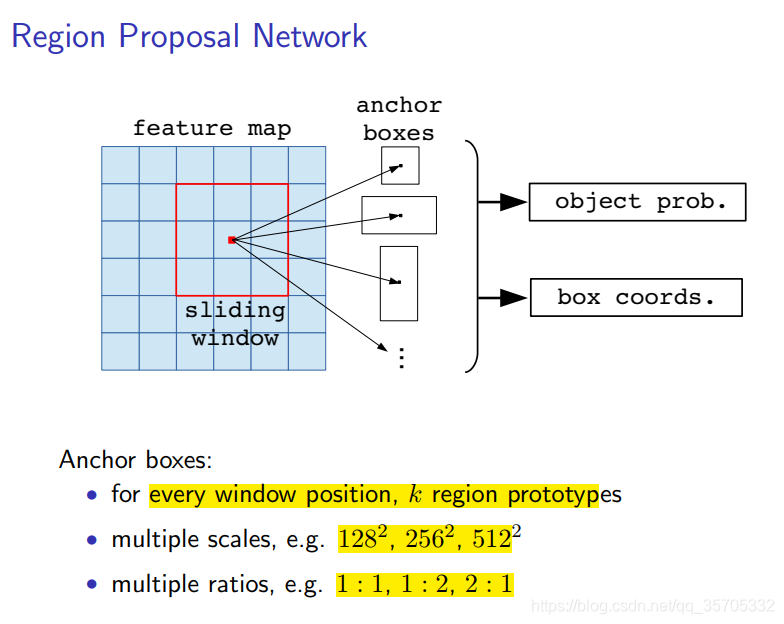
在訓練過程中的評價標準
IOU,ground truth 表示訓練過程中的監督樣本

mask_rcnn
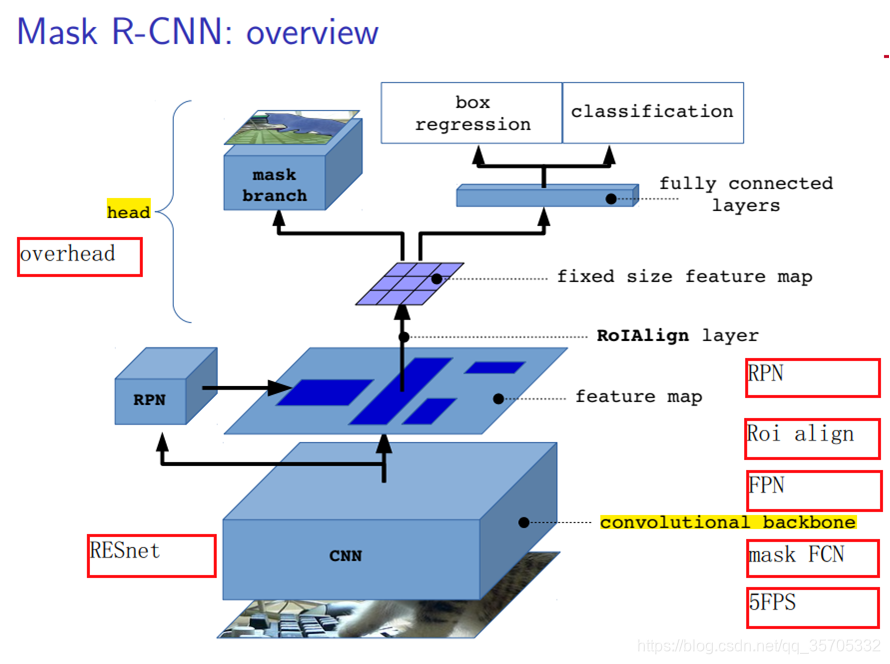
說明:mask_rcnn = faster_rcnn+fcn(識別出mask)可以輸入任意尺寸圖片,因為有ROIAlign layer層。
- resnet101/resnet50替換了VGG16網路更深,直接好處就是特徵圖語義資訊更多
- RoiAligen 替換了 Roi pool 提高了定位精確度 同時給畫素級別的例項分割提供了良好的基礎。
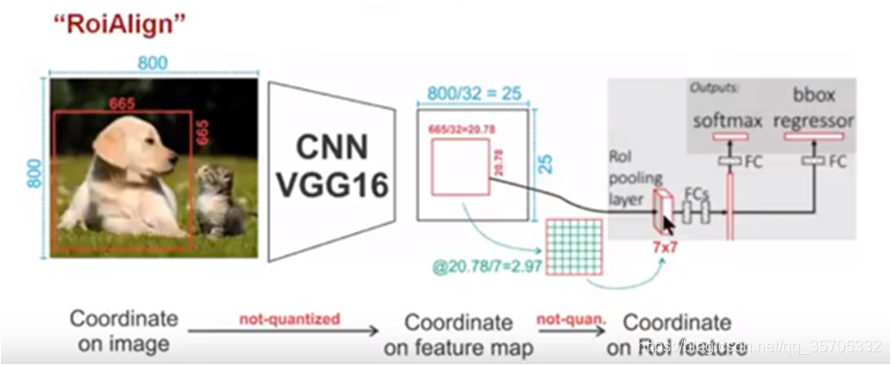
與ROIPool區別是,沒有進行兩次量化,而是保留了小數位,進行插值然後進行池化;
插值公式如下:由於插值點在正中心 其實公式可以化解為,0.25f1+0.25f2
+0.25f3+0.25f4
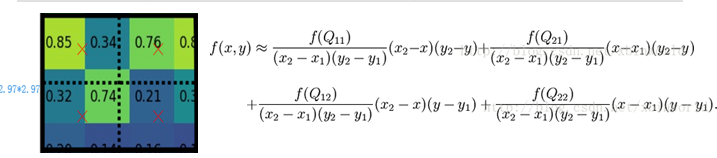
- FPN 低解析度,強語義特徵和高解析度弱語義特徵相結合,可以很好解決小尺寸目標問題(有的目標太小,還沒有步長大,這樣卷積池畫後特徵就消失了)
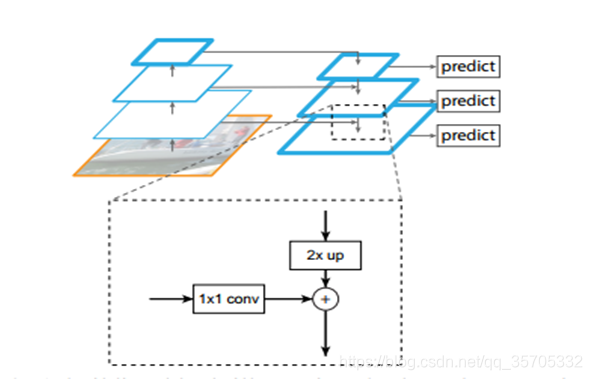
如圖所示,在本論文應用中是從第二階段卷積成對卷積特徵處理,第一階段卷積層太大。前向處理是下采樣過程,然後將最後一層最深語義特徵的特徵圖進行上取樣,每進行一次上取樣輸出大小與其上一層的大小一致,同時將上一層做11的卷積,主要是把通道數(取決於卷積的kenel數)變換為一致,然後才能融合,融合方式為1對1相加。
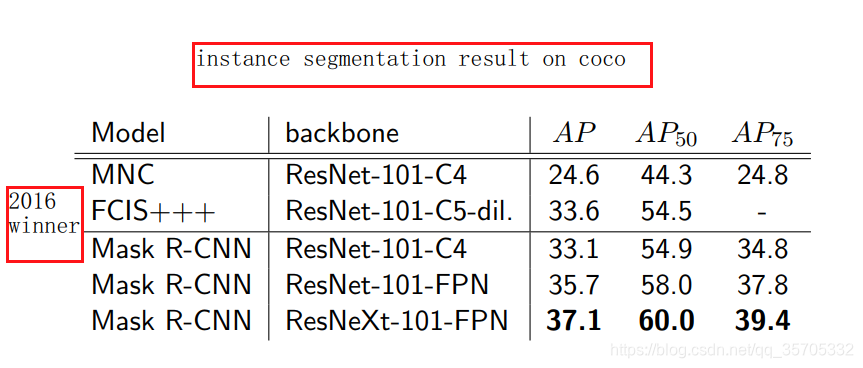
5mask_rcnn fcn
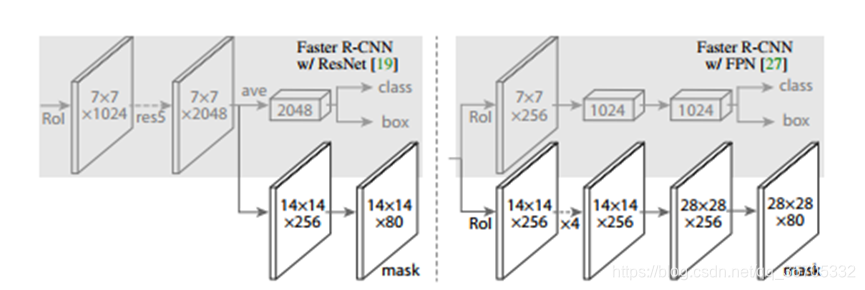
在RPN選出的roi上,進行卷積如上圖右邊所示,生成k個MM的掩膜,對每一個畫素點應用sigmoid ,然後>0.5歸為前景,反之歸為背景。
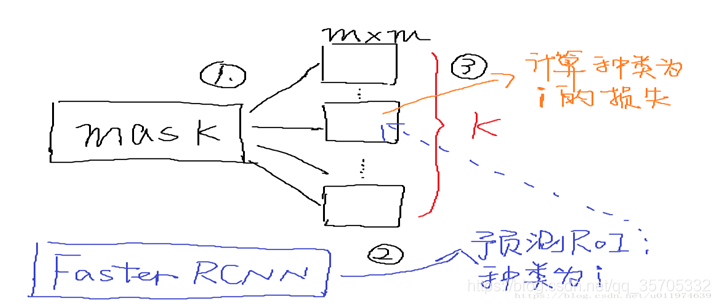
loss計算:(平均二值交叉損失熵)

