
==4==tesorflow目標識別API跑VOC2012資料集
沒有做 mask_rcnn的模型,因為不知道掩膜資訊怎麼匯入!其他模型兼可以按照以下步驟執行!(mask_rcnn會單獨總結一篇)
說明:執行已有模型 執行demo是針對coco資料集;而本文是利用基於coco資料集訓練的模型結合VOC2012資料微調,生成新的frozen_inference_graph.pb(儲存網路結構和資料)~可以再次利用jupyter-notebook執行程式,把frozen_inference_graph.pb的路徑更改為新生成的路徑!,類別標籤對映文字修改為pascal的類別標籤對映文字~pascal_lab_map.txt(data資料夾下面)
參考部落格
一 下載VOC2012資料集
二 分析資料集結構
下載完成之後,解壓;解壓完成後資料夾名字為 VOCdevkit,包含子資料夾VOC2012,子資料夾下包含下面五個資料夾。

- Annotations
Annotations資料夾中存放的是xml格式的標籤檔案,每一個xml檔案都對應於JPEGImages資料夾中的一張圖片。

- ImageSets
其中Action下存放的是人的動作(例如running、jumping等等,這也是VOC challenge的一部分)VOC2007就沒有Action,Layout下存放的是具有人體部位的資料(人的head、hand、feet等等,這也是VOC challenge的一部分)Main下存放的是影象物體識別的資料,總共分為20類。Main資料夾下包含了20個分類的***_train.txt、***_val.txt和***_trainval.txt。是兩列資料,左邊一列是對應圖片的序號,右邊一列是樣本標籤,-1表示負樣本,+1表示正樣本。
- JPEGImages
對應的圖片資訊

- SegmentationClass
語義分割的掩膜

- SegmentationObeject

4和5的區別是什麼呢?待補充
- class segmentation: 標註出每一個畫素的類別
- object segmentation: 標註出每一個畫素屬於哪一個物體
三 將VOC2012資料集格式轉換為tfrecord格式
藉助object_detection下的create_pascal_tf_record.py直接可以匯出tf格式~

cd dir #dir為的models_master下的research中 # From tensorflow/models python3 object_detection/create_pascal_tf_record.py \ --label_map_path=object_detection/data/pascal_label_map.pbtxt \ --data_dir=VOCdevkit --year=VOC2012 --set=train \ --output_path=pascal_train.record python3 object_detection/create_pascal_tf_record.py \ --label_map_path=object_detection/data/pascal_label_map.pbtxt \ --data_dir=VOCdevkit --year=VOC2012 --set=val \ --output_path=pascal_val.record
跟新:以上出來的少了掩膜資訊,針對mask_rcnn模型則無法訓練
截圖如下:

生成的結果在voc資料夾下面,結果資訊如下


四 將pascal_lable_map.pbtxt 移到voc目錄下
pascal_lable_map.pbtxt:原本在object_detection下data資料夾下
sudo cp pascal_lable_map.pbtxt voc/
五 下載模型 並訓練
1我下載的是faster_rcnn_resnet101_coco_11_06_2017.tar.gz
2移動到voc下面,解壓包含五個檔案,並且修改檔名為train;
3此時voc下面包含如下幾個檔案


4在voc下建立train_dir
5object_detection/samples/config/faster_rcnn_resnet101_coco.config 檔案移動到voc下;
6修改上一步的config檔案 共七處
num_classes: 20
fine_tune_checkpoint: “voc/train/model.ckpt”
input_path: “voc/pascal_train.record”
label_map_path: “voc/pascal_label_map.pbtxt”
input_path: “voc/pascal_val.record”
label_map_path: “voc/pascal_label_map.pbtxt”
num_examples: 5823
7.在object_detection 開啟終端,執行
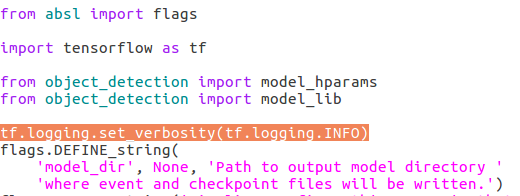
說明,最新的下載下來的model,train.py移動到了legacy資料夾下面,object_detection下面的model_main.py檔案可以替代train.py,但是不會輸出日誌,只需加上tf.logging.set_verbosity(tf.logging.INFO)
python3 model_main --train_dir voc/train_dir
/ --pipeline_config_path voc/faster_rcnn_resnet101_coco.config
(為什麼訓練了之後train_dir還是為空?)
答:注意 ~~ --train_dir voc/train_dir~~ 改為 –model_dir voc/train_dir
因為之前版本訓練用的是train.py 現在訓練使用的是model_main.py 內部定義有輕微改變
報錯1:from pycocotools import coco

解決辦法:
git clone https://github.com/pdollar/coco
cd coco/PythonAPI
#make -j3 make要報錯用下面一句話代替
python3 setup.py build_ext --inplace#
#再次報錯 提示安裝python-tk
sudo apt-get install python3-tk
ipython
from pycocotools import coco
報錯2:正常了!!!但是再次執行訓練又報錯依然說找from pycocotools import coco錯誤!!然後參考網上教程,新增環境變數:
重新輸入import COCO命令即可若進入PythonAPI目錄可以,而執行程式仍然報錯則修改環境變數即可(我試了完全沒用)
網上參考辦法如下:
gedit/.bashrc 在末尾加上export PATHONPATH=/home/john/coco/PythonAPI:$PATH #當前PythonAPI目錄的絕對路徑
最後暴力解決了!把coco資料夾下面的pycocotools複製到了voc下面
報錯3超出系統記憶體

解決辦法1:對輸入圖片進行縮放尺寸,原本最小尺寸600,最大尺寸1024;修改為300,512:對於我還是不能解決問題。
解決辦法2:下載較小的模型~
解決辦法3:把batch_size 原本是24,我在執行的時候出現視訊記憶體不足的問題,為了保險起見,改為1,如果1還是出現類似問題的話,建議換電腦……
五 匯出以及測試
六 小結-溫習過程
1.新版model下訓練檔案以model_main.py(object_detection/)替換了train.py 其中訓練過程中存放路徑model_dir替換了train_dir;;;;;在看老版本書籍時一定要注意版本更新了的細微差別。
2.下載資料集,本次使用資料集為VOC2012
3.轉為tfrecord格式 需要檔案有:create_pascal_tf_record.py (官方給的就是針對voc2012資料集的)

From tensorflow/models
python3 object_detection/create_pascal_tf_record.py
–label_map_path=object_detection/data/pascal_label_map.pbtxt
–data_dir=VOCdevkit --year=VOC2007 --set=train
–output_path=pascal_train.record
python3 object_detection/create_pascal_tf_record.py
–label_map_path=object_detection/data/pascal_label_map.pbtxt
–data_dir=VOCdevkit --year=VOC2007 --set=val
–output_path=pascal_val.record
4.下載模型修改配置檔案
5.匯出凍結檔案
6.測試
官方給的pascal2tf.py
沒有修改任何東西!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
r"""Convert raw PASCAL dataset to TFRecord for object_detection.
Example usage:
./create_pascal_tf_record --data_dir=/home/user/VOCdevkit \
--year=VOC2012 \
--output_path=/home/user/pascal.record
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import hashlib
import io
import logging
import os
from lxml import etree
import PIL.Image
import tensorflow as tf
from object_detection.utils import dataset_util
from object_detection.utils import label_map_util
flags = tf.app.flags
flags.DEFINE_string('data_dir', '', 'Root directory to raw PASCAL VOC dataset.')
flags.DEFINE_string('set', 'train', 'Convert training set, validation set or '
'merged set.')
flags.DEFINE_string('annotations_dir', 'Annotations',
'(Relative) path to annotations directory.')
flags.DEFINE_string('year', 'VOC2007', 'Desired challenge year.')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
flags.DEFINE_string('label_map_path', 'object_detection/data/pascal_label_map.pbtxt',
'Path to label map proto')
flags.DEFINE_boolean('ignore_difficult_instances', False, 'Whether to ignore '
'difficult instances')
FLAGS = flags.FLAGS
SETS = ['train', 'val', 'trainval', 'test']
YEARS = ['VOC2007', 'VOC2012', 'merged']
def dict_to_tf_example(data,
dataset_directory,
label_map_dict,
ignore_difficult_instances=False,
image_subdirectory='JPEGImages'):
"""Convert XML derived dict to tf.Example proto.
Notice that this function normalizes the bounding box coordinates provided
by the raw data.
Args:
data: dict holding PASCAL XML fields for a single image (obtained by
running dataset_util.recursive_parse_xml_to_dict)
dataset_directory: Path to root directory holding PASCAL dataset
label_map_dict: A map from string label names to integers ids.
ignore_difficult_instances: Whether to skip difficult instances in the
dataset (default: False).
image_subdirectory: String specifying subdirectory within the
PASCAL dataset directory holding the actual image data.
Returns:
example: The converted tf.Example.
Raises:
ValueError: if the image pointed to by data['filename'] is not a valid JPEG
"""
img_path = os.path.join(data['folder'], image_subdirectory, data['filename'])
full_path = os.path.join(dataset_directory, img_path)
with tf.gfile.GFile(full_path, 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = PIL.Image.open(encoded_jpg_io)
if image.format != 'JPEG':
raise ValueError('Image format not JPEG')
key = hashlib.sha256(encoded_jpg).hexdigest()
width = int(data['size']['width'])
height = int(data['size']['height'])
xmin = []
ymin = []
xmax = []
ymax = []
classes = []
classes_text = []
truncated = []
poses = []
difficult_obj = []
for obj in data['object']:
difficult = bool(int(obj['difficult']))
if ignore_difficult_instances and difficult:
continue
difficult_obj.append(int(difficult))
xmin.append(float(obj['bndbox']['xmin']) / width)
ymin.append(float(obj['bndbox']['ymin']) / height)
xmax.append(float(obj['bndbox']['xmax']) / width)
ymax.append(float(obj['bndbox']['ymax']) / height)
classes_text.append(obj['name'].encode('utf8'))
classes.append(label_map_dict[obj['name']])
truncated.append(int(obj['truncated']))
poses.append(obj['pose'].encode('utf8'))
example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/source_id': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/key/sha256': dataset_util.bytes_feature(key.encode('utf8')),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmin),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmax),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymin),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymax),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
'image/object/difficult': dataset_util.int64_list_feature(difficult_obj),
'image/object/truncated': dataset_util.int64_list_feature(truncated),
'image/object/view': dataset_util.bytes_list_feature(poses),
}))
return example
def main(_):
if FLAGS.set not in SETS:
raise ValueError('set must be in : {}'.format(SETS))
if FLAGS.year not in YEARS:
raise ValueError('year must be in : {}'.format(YEARS))
data_dir = FLAGS.data_dir
years = ['VOC2007', 'VOC2012']
if FLAGS.year != 'merged':
years = [FLAGS.year]
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
label_map_dict = label_map_util.get_label_map_dict(FLAGS.label_map_path)
for year in years:
logging.info('Reading from PASCAL %s dataset.', year)
examples_path = os.path.join(data_dir, year, 'ImageSets', 'Main','aeroplane_' + FLAGS.set + '.txt')
annotations_dir = os.path.join(data_dir, year, FLAGS.annotations_dir)
examples_list = dataset_util.read_examples_list(examples_path)
for idx, example in enumerate(examples_list):
if idx % 100 == 0:
logging.info('On image %d of %d', idx, len(examples_list))
path = os.path.join(annotations_dir, example + '.xml')
with tf.gfile.GFile(path, 'r') as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = dataset_util.recursive_parse_xml_to_dict(xml)['annotation']
tf_example = dict_to_tf_example(data, FLAGS.data_dir, label_map_dict,
FLAGS.ignore_difficult_instances)
writer.write(tf_example.SerializeToString())
writer.close()
if __name__ == '__main__':
tf.app.run()