
第7章:檔案和資料格式化
註明:本系列課程專為全國計算機等級考試二級 Python 語言程式設計考試服務
目錄
考綱考點
- 檔案的使用: 檔案開啟、關閉和讀寫
- 資料組織的維度:一維資料和二維資料
- 一維資料的處理:表示、儲存和處理
- 二維資料的處理:表示、儲存和處理
- 採用CSV格式對一二維資料檔案的讀寫
知識導圖

1、檔案的使用
檔案
- 檔案是儲存在輔助儲存器上的一組資料序列,可以包含任何資料內容。概念上,檔案是資料的集合和抽象。檔案包括兩種型別:文字檔案和二進位制檔案。
檔案的型別
- 文字檔案一般由單一特定編碼的字元組成,如UTF-8編碼,內容容易統一展示和閱讀。
- 二進位制檔案直接由位元0和位元1組成,檔案內部資料的組織格式與檔案用途有關。二進位制是資訊按照非字元但特定格式形成的檔案,例如,png格式的圖片檔案、avi格式的視訊檔案。
- 二進位制檔案和文字檔案最主要的區別在於是否有統一的字元編碼。
- 無論檔案建立為文字檔案或者二進位制檔案,都可以用“文字檔案方式”和“二進位制檔案方式”開啟,但開啟後的操作不同。
f = open("a.txt","rt") #t表示文字檔案方式
print(f.readline())
f.close()>>>
全國計算機等級考試注意:在這裡如果出現 UnicodeDecodeError 異常,如下:
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
print(f.readline())
UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 22: illegal multibyte sequence
請查閱另一篇部落格:Python3解決問題:讀取檔案時,出現亂碼或者“UnicodeDecodeError 'gbk' codec can't decode” 錯誤
- 文字檔案a.txt,採用二進位制方式開啟
f = open(“a.txt”,“rb”) #b表示二進位制檔案方式
print(f.readline())
f.close()>>>
b'\xc8\xab\xb9\xfa\xbc\xc6\xcb\xe3\xbb\xfa\xb5\xc8\xbc\xb6
\xbf\xbc\xca\xd4'- 採用文字方式讀入檔案,檔案經過編碼形成字串,打印出有含義的字元;採用二進位制方式開啟檔案,檔案被解析為位元組流。
檔案的開啟和關閉
- Python對文字檔案和二進位制檔案採用統一的操作步驟,即“開啟-操作-關閉”

- Python通過open()函式開啟一個檔案,並返回一個操作這個檔案的變數,語法形式如下:
<變數名> = open(<檔案路徑及檔名>, <開啟模式>)
| 開啟模式 | 含義 |
| 'r' | 只讀模式,如果檔案不存在,返回異常FileNotFoundError,預設值 |
| 'w' | 覆蓋寫模式,檔案不存在則建立,存在則完全覆蓋原始檔 |
| 'x' | 建立寫模式,檔案不存在則建立,存在則返回異常FileExistsError |
| 'a' | 追加寫模式,檔案不存在則建立,存在則在原檔案最後追加內容 |
| 'b' | 二進位制檔案模式 |
| 't' | 文字檔案模式,預設值 |
| '+' | 與r/w/x/a一同使用,在原功能基礎上增加同時讀寫功能 |
- 開啟模式使用字串方式表示,根據字串定義,單引號或者雙引號均可。上述開啟模式中,'r'、'w'、'x'、'b'可以和'b'、't'、'+'組合使用,形成既表達讀寫又表達檔案模式的方式。
- 檔案使用結束後要用close()方法關閉,釋放檔案的使用授權,語法形式如下:
<變數名>.close()
- 新建一個文字檔案a.txt,其內容為“全國計算機等級考試”,儲存在目錄PATH中,假設此時路徑PATH是Windows系統的D盤根目錄。開啟並關閉該檔案的操作過程如下。
>>>PATH = "D:\\"
>>>f = open(PATH + "a.txt", "rt")
>>>print(f.readline())
國家計算機等級考試
>>>f.close()
>>>print(f.readline())
Traceback (most recent call last):
File "<pyshell#81>", line 1, in <module>
print(f.readline())
ValueError: I/O operation on closed file.檔案的讀寫
- 根據開啟方式不同,檔案讀寫也會根據文字檔案或二進位制開啟方式有所不同。
| 方法 | 含義 |
| f.read(size=-1) |
從檔案中讀入整個檔案內容。引數可選,如果給出,讀入前size長度的字串或位元組流 |
| f.readline(size = -1) | 從檔案中讀入一行內容。引數可選,如果給出,讀入該行前size長度的字串或位元組流 |
| f.readlines(hint=-1) | 從檔案中讀入所有行,以每行為元素形成一個列表。引數可選,如果給出,讀入hint行 |
| f.seek(offset) | 改變當前檔案操作指標的位置,offset的值: 0:檔案開頭; 2: 檔案結尾 |
- 如果檔案不大,可以一次性將檔案內容讀入,儲存到程式內部變數中。f.read()是最常用的一次性讀入檔案的函式,其結果是一個字串。
>>>f = open("D://b.txt", "r")
>>>s = f.read()
>>>print(s)
新年都未有芳華,二月初驚見草芽。
白雪卻嫌春色晚,故穿庭樹作飛花。
>>>f.close()- f.readlines()也是一次性讀入檔案的函式,其結果是一個列表,每個元素是檔案的一行。
>>>f = open("D://b.txt", "r")
>>>ls = f.readlines()
>>>print(ls)
['新年都未有芳華,二月初驚見草芽。\n', '白雪卻嫌春色晚,故穿
庭樹作飛花。\n']
>>>f.close()- 檔案開啟後,對檔案的讀寫有一個讀取指標,當從檔案中讀入內容後,讀取指標將向前進,再次讀取的內容將從指標的新位置開始。
>>>f = open("D://b.txt", "r")
>>>s = f.read()
>>>print(s)
新年都未有芳華,二月初驚見草芽。
白雪卻嫌春色晚,故穿庭樹作飛花。
>>>ls = f.readlines()
>>>print(ls)
[]
>>>f.close()- 結合讀取指標理解,上述程式碼中ls返回值為空,因為之前f.read()方法已經讀取了檔案全部內容,讀取指標在檔案末尾,再次呼叫f.readlines()方法已經無法從當前讀取指標讀入內容,因此返回結果為空。
- f.seek()方法能夠移動讀取指標的位置,f.seek(0)將讀取指標移動到檔案開頭,f.seek(2)將讀取指標移動到檔案結尾。
>>>f = open("D://b.txt", "r")
>>>s = f.read()
>>>print(s)
新年都未有芳華,二月初驚見草芽。
白雪卻嫌春色晚,故穿庭樹作飛花。
>>>f.seek(0) # 將讀取指標重置到檔案開頭
>>>ls = f.readlines()
>>>print(ls)
['新年都未有芳華,二月初驚見草芽。\n', '白雪卻嫌春色晚,故穿庭樹作飛花。\n']
>>>f.close()- 從文字檔案中逐行讀入內容並進行處理是一個基本的檔案操作需求。文字檔案可以看成是由行組成的組合型別,因此,可以使用遍歷迴圈逐行遍歷檔案,使用方法如下:
f = open(<檔案路徑及名稱>, "r")
for line in f:
# 處理一行資料
f.close()
f = open("D://b.txt", "r")
for line in f:
print(line)
f.close()>>
新年都未有芳華,二月初驚見草芽。
白雪卻嫌春色晚,故穿庭樹作飛花。| 方法 | 含義 |
| f.write(s) | 向檔案寫入一個字串或位元組流 |
| f.writelines(lines) | 將一個元素為字串的列表寫入檔案 |
- f.write(s)向檔案寫入字串s,每次寫入後,將會記錄一個寫入指標。該方法可以反覆呼叫,將在寫入指標後分批寫入內容,直至檔案被關閉。
>>>f = open("D://c.txt", "w")
>>>f.write('新年都未有芳華\n')
>>>f.write('二月初驚見草芽\n')
>>>f.write('白雪卻嫌春色晚\n')
>>>f.write('故穿庭樹作飛花\n')
>>>f.close()- 上述語句執行後將在D盤目錄下生成一個檔案c.txt,內容如下。
新年都未有芳華
二月初驚見草芽
白雪卻嫌春色晚
故穿庭樹作飛花
- 使用f.write(s)時,要顯式的使用'\n'對寫入文字進行分行,如果不進行分行,每次寫入的字串會被連線起來。
- f.writelines(lines)直接將列表型別的各元素連線起來寫入檔案f。
>>>ls = ['新年都未有芳華\n', '二月初驚見草芽\n','白雪卻嫌春色晚
\n','故穿庭樹作飛花\n']
>>>f = open("D://c.txt", "w")
>>>f.writelines(ls)
>>>f.close()2、資料組織的維度
一組資料在被計算機處理前需要進行一定的組織,表明資料之間的基本關係和邏輯,進而形成“資料的維度”。根據資料的關係不同,資料組織可以分為:一維資料、二維資料和高維資料。
一維資料
- 一維資料由對等關係的有序或無序資料構成,採用線性方式組織,對應於數學中陣列的概念。例如:中國的直轄市列表即可表示為一維資料,一維資料具有線性特點。
北京、上海、天津、重慶二維資料
- 二維資料,也稱表格資料,由關聯關係資料構成,採用二維表格方式組織,對應於數學中的矩陣,常見的表格都屬於二維資料。
- 例如:國家統計局釋出的居民消費價格指數是二維資料
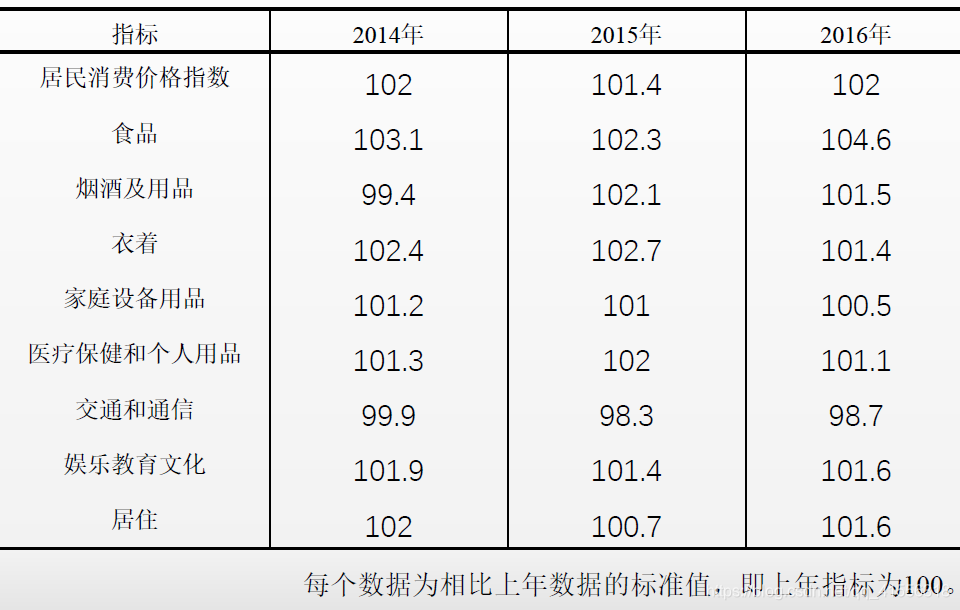
高維資料
- 高維資料由鍵值對型別的資料構成,採用物件方式組織,可以多層巢狀。
- 高維資料在Web系統中十分常用,作為當今Internet組織內容的主要方式,高位資料衍生出HTML、XML、JSON等具體資料組織的語法結構。
"本書" : [
"第1章" : "程式設計基本方法",
"第2章" : "Python語言基本語法元素",
"第3章" : "基本資料型別",
"第4章" : "程式的控制結構",
"第5章" : "函式和程式碼複用",
"第6章" : "組合資料型別",
"第7章" : "檔案和資料格式化",
"第8章" : "Python計算生態",
"第9章" : "Python標準庫概覽",
"第10章" : "Python第三方庫概覽",
"第11章" : "Python第三方庫縱覽",
"第12章" : "考試指導",
"附錄" : "附錄1234567"
]3、一維資料的處理
一維資料的表示
- 一維資料是最簡單的資料組織型別,由於是線性結構,在Python語言中主要採用列表形式表示。例如:中國的直轄市資料可以採用一個列表變量表示。
>>>ls = ['北京', '上海', '天津', '重慶']
>>>print(ls)
['北京', '上海', '天津', '重慶']一維資料的儲存
- 一維資料的檔案儲存有多種方式,總體思路是採用特殊字元分隔各資料。常用儲存方法包括4種。
(1)採用空格分隔元素,例如:
北京 上海 天津 重慶
(2)採用逗號分隔元素,例如:
北京,上海,天津,重慶
(3)採用換行分隔包括,例如:
北京
上海
天津
重慶
(4)其他特殊符號分隔,以分號分隔為例,例如:
北京;上海;天津;重慶
- 逗號分割的儲存格式叫做CSV格式(Comma-Separated Values,即逗號分隔值),它是一種通用的、相對簡單的檔案格式,在商業和科學上廣泛應用,大部分編輯器都支援直接讀入或儲存檔案為CSV格式
- 一維資料儲存成CSV格式後,各元素採用逗號分隔,形成一行。從Python表示到資料儲存,需要將列表物件輸出為CSV格式以及將CSV格式讀入成列表物件
- 列表物件輸出為CSV格式檔案方法如下,採用字串的join()方法最為方便。
ls = ['北京', '上海', '天津', '重慶']
f = open("city.csv", "w")
f.write(",".join(ls)+ "\n")
f.close()北京,上海,天津,重慶一維資料的處理
- 對一維資料進行處理首先需要從CSV格式檔案讀入一維資料,並將其表示為列表物件。
f = open("city.csv", "r")
ls = f.read().strip('\n').split(",")
f.close()
print(ls)>>>
['北京', '上海', '天津', '重慶']4、二維資料的處理
- 二維資料由多條一維資料構成,可以看成是一維資料的組合形式。因此,二維資料可以採用二維列表來表示,即列表的每個元素對應二維資料的一行,這個元素本身也是列表型別,其內部各元素對應這行中的各列值
ls = [
['指標', '2014年', '2015年', '2016年'],
['居民消費價格指數', '102', '101.4', '102'],
['食品', '103.1', '102.3', '104.6'],
['菸酒及用品', '994', '102.1', '101.5'],
['衣著', '102.4', '102.7', '101.4'],
['家庭裝置用品', '101.2', '101', '100.5'],
['醫療保健和個人用品', '101.3', '102', '101.1'],
['交通和通訊', '99.9', '98.3', '98.7'],
['娛樂教育文化', '101.9', '101.4', '101.6'],
['居住', '102', '100.7', '101.6'],
]二維資料的儲存
- 二維資料由一維資料組成,用CSV格式檔案儲存。CSV檔案的每一行是一維資料,整個CSV檔案是一個二維資料。
- 二維列表物件輸出為CSV格式檔案方法如下,採用遍歷迴圈和字串的join()方法相結合。
# ls代表二維列表,此處省略
f = open("cpi.csv", "w")
for row in ls:
f.write(",".join(row)+ "\n")
f.close()二維資料的處理
- 對二維資料進行處理首先需要從CSV格式檔案讀入二維資料,並將其表示為二維列表物件。借鑑一維資料讀取方法,從CSV檔案讀入資料的方法如下。
f = open("cpi.csv", "r")
ls = []
for line in f:
ls.append(line.strip('\n').split(","))
f.close()
print(ls)- 程式執行後二維列表物件ls的內容如下。
>>>
[['指標', '2014年', '2015年', '2016年'], ['居民消費價格指數
', '102', '101.4', '102'], ['食品', '103.1', '102.3',
'104.6'], ['菸酒及用品', '994', '102.1', '101.5'], ['衣著
', '102.4', '102.7', '101.4'], ['家庭裝置用品', '101.2',
'101', '100.5'], ['醫療保健和個人用品', '101.3', '102',
'101.1'], ['交通和通訊', '99.9', '98.3', '98.7'], ['娛樂教
育文化', '101.9', '101.4', '101.6'], ['居住', '102',
'100.7', '101.6']]- 二維資料處理等同於二維列表的操作,與一維列表不同,二維列表一般需要藉助迴圈遍歷實現對每個資料的處理,基本程式碼格式如下:
for row in ls:
for item in row:
<對第row行第item列元素進行處理>
- 對二維資料進行格式化輸出,列印成表格形狀
# 此處略去從CSV獲取資料到二維列表ls
for row in ls:
line = ""
for item in row:
line += "{:10}\t".format(item)
print(line)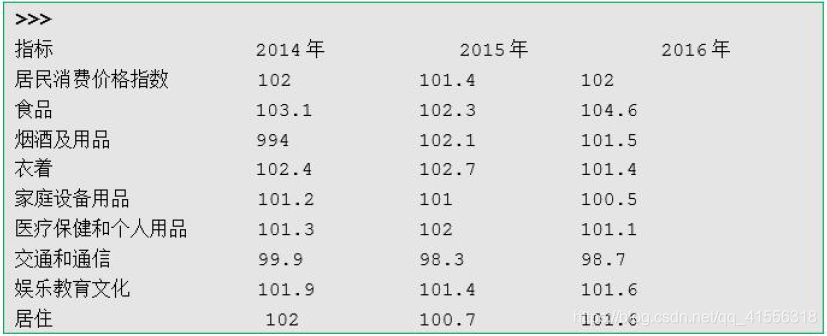
5、例項解析:國家財政資料趨勢演算
- 國家統計局每年會公開許多資料,比如國民經濟核算指標等。國家統計局公佈的大部分資料都以二維表格形式展現,然而,藏在這些資料背後的價值要比表格所展現的更多。
- 以國家財政收支的公開資料為例,這裡展示如何利用Python挖掘資料變化的規律。將從網上獲取的公開資訊存為finance.csv檔案
| 指標 | 2000年 | 2015年 | 2016年 |
| 全部收入 | 13395.2 | 152269.2 | 159605 |
| 中央收入 | 6989.2 | 69267.2 | 72365.6 |
| 地方收入 | 6406.1 | 83002 | 87239.4 |
| 全部支出 | 15886.5 | 175877.8 | 187755.2 |
| 中央支出 | 5519.9 | 25542.2 | 27403.9 |
| 地方支出 | 10366.7 | 150335.6 | 160351.4 |
- 由個別資料預測規律屬於數值分析的內容,可以通過線性迴歸方程建立簡單模型,線性迴歸方程的公式為:
- X代表年份,Y代表各年份對應的數值。Python實現的國家財政資料趨勢演算,根據上述三個數值計算出更多年份的可能資料。
# FinancePredict.py
def parseCSV(filename):
dataNames, data = [], []
f = open(filename, 'r', encoding='utf-8')
for line in f:
splitedLine = line.strip().split(',')
if '指標' in splitedLine[0]:
years = [int(x[:-1]) for x in splitedLine[1:]]
else:
dataNames.append('{:10}'.format(splitedLine[0]))
data.append([float(x) for x in splitedLine[1:]])
f.close()
return years, dataNames, data
def means(data):
return sum(data) / len(data)
def linearRegression(xlist, ylist):
xmeans, ymeans = means(xlist), means(ylist)
bNumerator = - len(xlist) * xmeans * ymeans
bDenominator = - len(xlist) * xmeans ** 2
for x, y in zip(xlist, ylist):
bNumerator += x * y
bDenominator += x ** 2
b = bNumerator / bDenominator
a = ymeans - b * xmeans
return a, b
def calNewData(newyears, a, b):
return [(a + b * x) for x in newyears]
def showResults(years, dataNames, newDatas):
print('{:^60}'.format('國家財政收支線性估計'))
header = '指標 '
for year in years:
header += '{:10}'.format(year)
print(header)
for name, lineData in zip(dataNames, newDatas):
line = name
for data in lineData:
line += '{:>10.1f}'.format(data)
print(line)
def main():
newyears = [x+2010 for x in range(7)]
newDatas = []
years, dataNames, datas = parseCSV('finance.csv')
for data in datas:
a, b = linearRegression(years, data)
newDatas.append(calNewData(newyears, a, b))
showResults(newyears, dataNames, newDatas)
main()
>>>
國家財政收支線性估計
指標 2010 2011 2012 2013 2014 2015 2016
全部收入 105359.6 114550.1 123740.6 132931.0 142121.5 151312.0 160502.4
中央收入 48169.1 52283.8 56398.5 60513.2 64627.9 68742.7 72857.4
地方收入 57190.6 62266.3 67342.1 72417.8 77493.6 82569.3 87645.1
全部支出 122936.9 133645.7 144354.5 155063.3 165772.1 176480.9 187189.8
中央支出 19037.5 20390.9 21744.3 23097.7 24451.1 25804.5 27157.9
地方支出 103899.4 113254.8 122610.2 131965.6 141321.0 150676.4 160031.9本章小結
本章講解了檔案的基本使用方法,包括檔案的開啟、關閉、讀取和寫入。進一步圍繞資料的維度,講解了一維資料、二維資料和高維資料的概念,以及一二維資料的表示、儲存和處理方法。通過國家財政資料趨勢演算的例項幫助讀者理解資料處理的基本方法。
一二維資料是社會生活中資料運用的絕對大多數,請思考一下,方圓十米範圍內有哪些一二維資料亟待程式的處理?!