
JVM Throughput和CMS垃圾回收器
垃圾收集器
Throughtput 垃圾收集器
簡介
Throughtput收集器是一款關注吞吐量的收集器。這個收集器也是唯一一個實現了UseAdaptiveSizePolicy策略的垃圾收集器。允許使用者通過指定最大的暫停時間和垃圾收集器所佔用的時間百分比,然後動態調整JVM的引數來達到配置的目標。
垃圾收集器
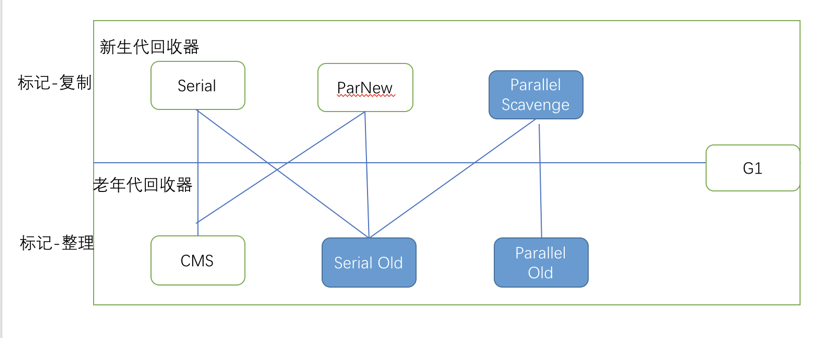
上圖是一個經典的垃圾收集器的圖,圖中有顏色的就是 throughput垃圾回收器 ,各個線代表的是各個垃圾回收器之間哪兩個可以配合使用。
從上圖可以看出 Parralel Scanvenge垃圾回收器不能和CMS配合使用。
ParallelScavenge收集器
ParallelScavenge收集器是新生代收集器,使用的是Scavenge GC。是一個並行收集器。在copping階段可以多個執行緒一起執行,在多執行緒的場景下可一儘量的提高Minor GC的效率。目的是可以達到一個可控的吞吐量。
| 吞吐量 = 執行使用者程式碼的時間/(執行使用者程式碼時間+垃圾收集時間) |
虛擬機器執行總時間100分鐘,其中垃圾收集器運行了1分鐘,則吞吐量就是99%
ParallelScavenge收集器的來歷為,在HotSpot VM開發的時候都是在分代式框架下開發,並且希望第三方開發者也能在這個框架下開發自定義的收集器,這樣就能和其他收集器配合使用。但是有個開發者不願意使用這個框架,並且憑藉自己的能力開發了並行收集器,這時候JVM中的並行收集器是不存在的。經過測試,這個收集器的效能還是非常不錯的,於是就被放入到了HotSopt中成為了ParallelScavenge收集器。這就是為什麼這個收集器不能和CMS配合使用,因為它就不是在分代式框架下開發的。
ParallelScavenge是在jdk1.7之前的預設垃圾回收器。使用ParallelScavence收集器需要需要關注以下兩個引數:
- MaxGCPauseMills
這個引數控制GC最大的停頓時間。設定以後通過動態調整新生代的大小來達到暫停時間是可以控制的。但是這個值不是越小越好。因為這個如果這個值設定的比較小,那必定會導致新生代的比較小,新生代空間比較小的話,會導致更加頻繁的minor GC,這樣總間隔時間就會變大。
- GCTimeRatio
收集器執行時間所佔時間的比率,介於0到100的整數。
通過調整這兩個引數的大小能起到動態調整吞吐量和暫停時間的目的,這樣使用者不用關心新老年代應該各自設定多大,只需要設定好這兩個值,剩下的交給虛擬機器動態調整。
Parallel Old
Parallel Old是ParallelScavenge的老年代版本,之前如果新生代使用ParallelScavenge,老年代只能使用Serial Old,為了彌補這個缺失,所以在jdk 1.6的時候開發了Parallel Old 老年代並行垃圾回收器,配合ParallelScavenge使用。此時兩者雙劍合璧,才更能顯現出來Throughtput的強悍之處
Serial Old收集器
單執行緒老年代收集器,主要用在client模式下,不過也作為CMS垃圾收集器併發模式失效以後備用收集器。
Throughtput收集器配置
Throughtput收集器通過第一節的圖中可以看出有兩種配置
- ParallelScavenge+Parallel Old
-XX:+UseParallelGC 或者
-XX:+UseParallelOldGC,這兩個配置任選一個,就會選中ParallelScavenge+Parallel Old組合作為收集器。
列印的GC日誌如下
[Full GC (System.gc()) [PSYoungGen: 992K->0K(29696K)] [ParOldGen: 8K->761K(68608K)] 1000K->761K(98304K), [Metaspace: 3152K->3152K(1056768K)], 0.0060131 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]- ParallelScavenge+Serial Old
如果非得強制使用單執行緒老年代收集器(Serial Old)可以如下配置:
-XX:+UseParallelGC -XX:-UserParallelOldGC發生GC時,列印的日誌如下
[Full GC (System.gc()) [PSYoungGen: 928K->0K(29696K)] [PSOldGen: 8K->767K(68608K)] 936K->767K(98304K), [Metaspace: 3167K->3167K(1056768K)], 0.0023446 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]ParallelScavenge和ParNew
在收集器的圖中,我們看到還有一個ParNew的新生代收集器,由於CMS收集器不能配合ParallelScavenge使用,所以只剩下一個單執行緒的Serial收集器,為了能夠有所匹配,所以出來了並行的新生代收集器,它和ParallelScavenge相比有如下不同:
- 演算法不同,ParNew採用的是廣度優先遍歷物件,而ParallelScavenge採用的是深度優先。
- 沒有UseAdaptiveSizePolicy策略
總結
如果是關注吞吐量的應用,採用Throughput收集器是個不錯的選擇。並且可以通過設定
-XX:ParallelGCThreads=N 來設定並行GC執行緒數。在使用的過程中最好不要手工的指定新生代和老年代的大小,而是指定MaxGCPauseMills 和GCTimeRatio讓其自動調整,以達到最優值。同時設定我們堆大小即可。
CMS收集器
CMS收集器設計的初衷是了消除Throughtput收集器和Serial收集器FullGC週期的長時間停頓。CMD收集器在Minor GC時會暫停所有應用執行緒,並且以多執行緒的方式進行垃圾回收。
CMS收集器在FullGC時不再暫停應用執行緒,而是使用若干個後臺執行緒定期的對老年代空間進行掃描,及時會後其中不再使用的物件。這種做法使得CMS成為一個低延遲的收集器。應用執行緒只在Minor GC以及後臺執行緒騷烤老年代時發生極其短暫的停頓。應用程式執行緒停頓的總時長與使用Throughtput收集器比起來短的多。
但是會付出額外的代價,那就是更高的CPU使用:必須有足夠的CPU資源用於後臺執行垃圾收集執行緒。除此之外,後臺不再進行壓縮整理工作,也就是說堆回逐漸的碎片化。如果CMS的後臺執行緒無法獲得完成他們任務所需要的CPU資源,或者如果堆變的過度碎片化以至於無法找到連續記憶體分配先物件,CMS就會蛻化為Serial收集器的行為,暫停所有應用執行緒,使用單執行緒進行回收,整理老年代空間,之後又恢復到併發執行,再次啟動後臺執行緒,直到堆變的再次過度碎片化。
開啟標誌:
-XX:+UseConcMarkSweepGC ,-XX:+UseParNewGC這兩個標誌可以開啟CMS垃圾回收器。
Throughput和CMS的選擇
- 衡量標準時相應時間或吞吐量,在Throughput收集器和CMS收集器之間做選擇的依據主要是有多少空閒CPU資源能用於執行後臺的併發執行緒。
- 通常情況下,Throughtput收集器的平均響應時間比Concurrent收集器要差,但是在90%影響時間或者99%響應時間的這幾個指標上,Throughput收集器要比Concurrent要好些
- 使用Throughput收集器會超負荷進行大量的Full GC時,切換到CMS收集器通常能獲得更低的響應時間