
資料科學家需要了解的5大聚類演算法
阿新 • • 發佈:2018-11-30
聚類是一種涉及資料點分組的機器學習技術。給定一個數據點集,則可利用聚類演算法將每個資料點分類到一個特定的組中。理論上,同一組資料點具有相似的性質或(和)特徵,不同組資料點具有高度不同的性質或(和)特徵。聚類屬於無監督學習,也是在很多領域中使用的統計資料分析的一種常用技術。本文將介紹常見的5大聚類演算法。
K-Means演算法
K-Means演算法可能是最知名的聚類演算法,該演算法在程式碼中很容易理解和實現。
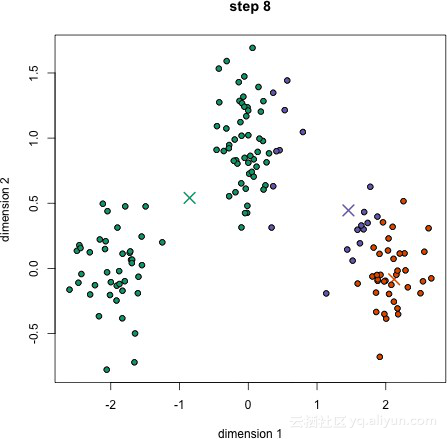
K-Means聚類
1.首先我們選擇一些類或組,並隨機初始化它們各自的中心點。為了計算所使用類的數量,最好快速檢視資料並嘗試識別任何一個不同的分組。中心點是和每個資料點向量長度相同的向量,上圖示記為“X”。
2.每個資料點是通過計算該點與每個組中心的距離進行分類的,然後再將該點分類到和中心最接近的分組中。
3.根據這些分類點,通過計算群組中所有向量的均值重新計算分組中心。
4.重複以上步驟進行數次迭代,或者直到迭代之間的組中心變化不大。選擇結果最好的迭代方式。
因為我們只是計算點和組中心之間的距離,計算量很少,所以K-Means演算法的速度非常快,具有線性複雜度O(n)。
K-Means演算法的缺點是必須選擇有多少個組或類,因為該演算法的目的是從不同的資料中獲得資訊。另外,K-means演算法從隨機的選擇聚類中心開始,因此不同的演算法執行可能產生不同的聚類結果。其結果缺乏一致性,而其他聚類方法結果更一致。