
決戰Python之巔(五)
前言
Oh~yeah,昨天把作業交上去了。90分,賺了40塊錢哈哈哈。
透露一下,我是在路飛學城學的Python全棧開發(不是打廣告!!不是打廣告!!不是打廣告!!我沒收廣告費!!!!),然後他是有獎學金的,作業寫的好或者學得快是會給你提供獎學金,獎學金到最後是可以提現滴~~
好了,講重點。
知識回顧
第二模組一開始學的是最最最基本的二進位制,稍微接觸過程式碼或者學過一點的計算機知識的應該都知道,就不多說,介紹下:
二進位制及二進位制轉換
眾所周知,計算機最底層只能識別簡單的0和1,所以你輸進去的資料到最後都會轉換成0和1,這是前提。
十進位制大家都知道吧,十進位制的數“逢十進一”,二進位制則是“逢二進一”。例如:
十進位制的“1”在二進位制中就是“1”,- -這個一樣的,但是十進位制中的“2”,在二進位制中是什麼呢?因為“逢二進一”,所以在二進位制中則是“10”,十進位制0~10在二進位制中的對應為:
十進位制 : 二進位制: 0 = 00000000 1 = 00000001 2 = 00000010 3 = 00000011 4 = 00000100 5 = 00000101 6 = 00000110 7 = 00000111 8 = 00001000 9 = 00001001 10 = 00001010
挺簡單吧…其實就是 二進位制的第n位代表的十進位制就是2n 。
字元編碼演化
ASCII碼與二進位制
好了,既然知道了二進位制(- -不會的寄幾學去),那麼現在有一個問題:我們輸入的是A,計算機存的是01010(假設是這個),我們又輸入B,計算機存的又是另一串二進位制,它是怎麼知道我輸入的是什麼,或者說A為什麼是這串二進位制,B又是另一串呢?
…其實,這都是人為規定的。那麼現在又有一個問題:你可以規定0101代表某個字元,我也可以規定0101代表另一個啊?為了解決這種“亂象”,ASCII碼橫空出世,它最初是美國國家標準,供不同計算機在相互通訊時用作共同遵守的西文字元編碼標準,它已被國際標準化組織(International Organization for Standardization, ISO)定為國際標準,稱為ISO 646標準。適用於所有拉丁文字字母。
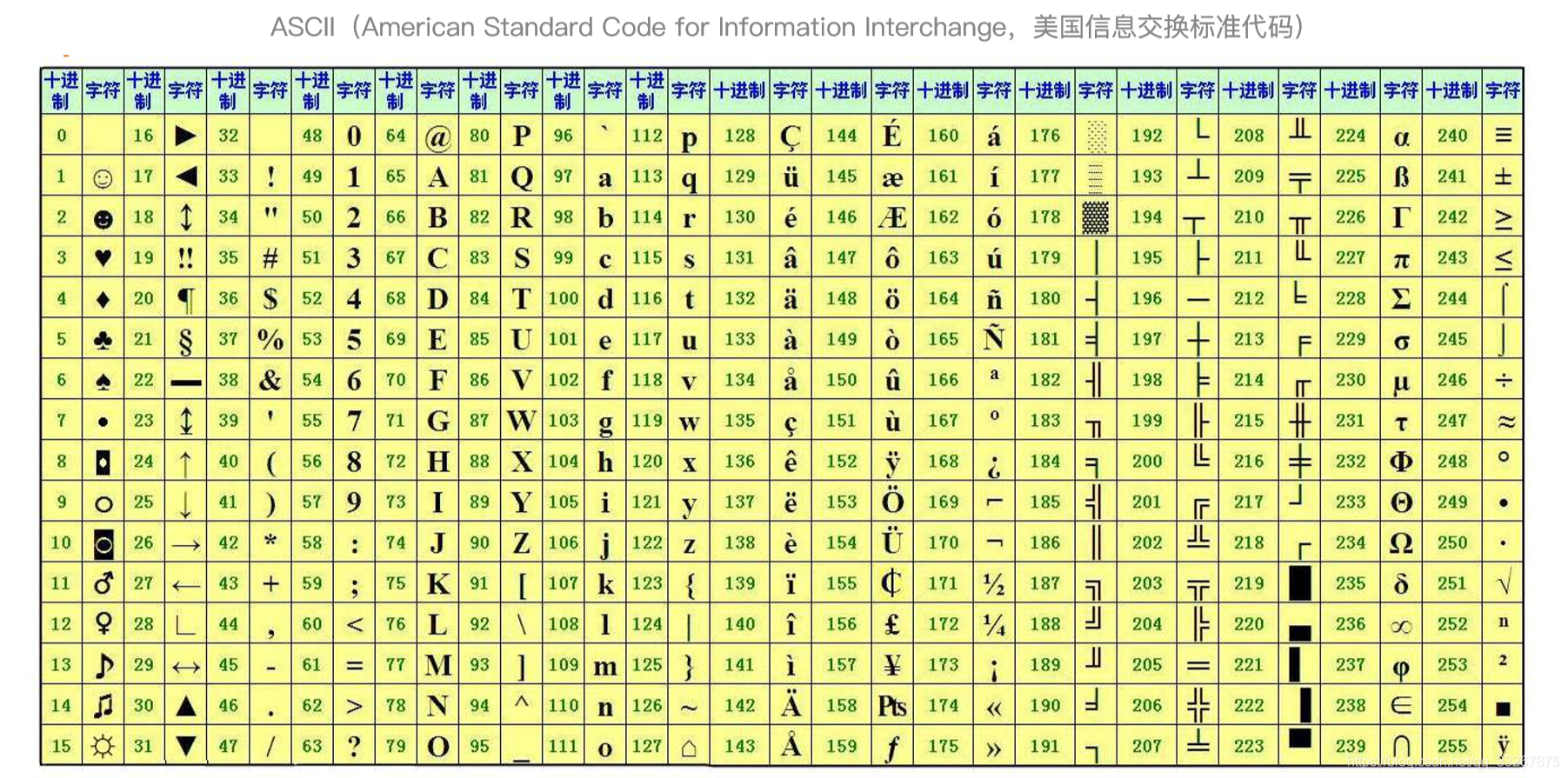
這樣,對於“Kris”,存的時候就有一串規定的二進位制資料,“K”是1001011,“r”就是1110010,“i”就是1101001,“s”就是01110011。這裡舉得例子不太好,但是大家可以發現,這些二進位制資料又長又短,比如說換行符就是1010,而“K”是1001011,他們存在記憶體裡是這樣的10101001011,那麼計算機怎麼知道哪一段代表什麼字元呢? ASCII中有這樣一個規定,每一個字元都用8位二進位制表示,不足8位的前面用0補足。什麼意思呢?還是那個換行符,十進位制轉換成二進位制是1010,只有4位,所以前面4位需要用0補上,也就是0000 1010,這樣就夠8位,而且本身的值也沒有改變。這樣,計算機就知道每8位就代表一個字元。
這裡擴充套件一個小知識:
8bit = 1bytes ,bit:位元,一個二進位制位,最小的表示單位
bytes:位元組,最小的儲存單位,1bytes縮寫為1B
1KB = 1024B
1MB = 1024KB
1GB = 1024MB
....
Unicode編碼
細心的同學可能發現了,ASCII碼中只有拉丁字母那些西方的語言,沒有我大中華的漢字啊!!這是萬萬不行的,所以呢在1981年5月1日,國家標準總局釋出了GB2312,又稱國標碼,收錄漢字6763個。而後又對其進行擴充套件。
但是呢,問題又來了:我們國家可以有我們國家的國標碼,俄羅斯也有他們自己的國標碼,那萬一中俄友好交流時,我們計算機上裝了俄羅斯的軟體,那豈不是會亂碼?(為什麼會亂碼呢?假設0101在我們國標碼中代表的是“中”這個字,在俄羅斯的國標碼中表示的不知道是什麼,但計算機只存0101,它不知道我們用的是哪套標準)所以呢,就有了Unicode編碼,又稱萬國碼,將世界上的每種語言的每個字元都定義了唯一的一個編碼。這樣就解決了問題。
UTF-8
然而,正當Unicode編碼“風靡全球”時,美國人他們不幹了,為什麼呢?在原先的ASCII碼中,一個英文字元只佔1個位元組,但用了Unicode編碼後,一個英文字元要用2個位元組(Unicode編碼規定每個字元佔2個位元組),這就意味著1部1個G的美國小電影,現在就要變成2個G,容量直接翻一番。
所以,後來又推出了一套壓縮後的Unicode編碼,稱為UTF-8,這套編碼裡,ASCII碼中的佔一個位元組,歐洲字元佔2個,東亞的用3個位元組…
Python 2.x 中要顯示中文字元,需要在檔案頭寫:
# -*- coding: utf-8 -*-
浮點數
這裡補充一個知識點:浮點型。你也可以理解為小數…我就是這麼理解的,其實也不怎麼用。
Python中計算高精度的浮點數方法:
# 藉助decimal模組的“getcontext”和“Decimal”方法
from decimal import *
getcontext().prec = 50 # 精度為50,就是小數點後面幾個數字
a = '3.141592653513651054608317828332'
Decimal(a)