
Python處理excel檔案
阿新 • • 發佈:2018-11-27
Python處理excel檔案
這裡只介紹幾種常用的庫。對於2003以前的excel版本,即.xls檔案,只能用xlrd和xlwt庫來處理;對於2003及以後的excel檔案,即.xlsx檔案,需要使用openpyxl庫來處理,這裡著重介紹這三個第三方庫。
注:Workbook是對工作簿(excel)的抽象,Worksheet是對錶格(sheet)的抽象,Cell是對單元格的抽象
Python處理.xlsx檔案
-
匯入模組
import openpyxl -
讀入一個已有的excel
# 當前路徑下 r_wb = openpyxl.load_workbook('test-openpyxl.xlsx') # 指定路徑下 r_wb = openpyxl.load_workbook(r'C:\Users\y84107470\PycharmProjects\excel-fun\test-openpyxl.xlsx') -
新建一個excel
# 無論是匯入的還是新建的excel,後面對Wb(Workbook),ws(worksheet)和cell的操作是一樣的 w_wb = openpyxl.Workbook() -
sheet的屬性與操作
-
獲取所有sheet的名稱
r_sheetnames = r_wb.get_sheet_names()# 目前已棄用,不會報錯,但是又警告,建議用下面的方法 r_sheetnames = r_wb.sheetnames -
獲取某個sheet的三種方法
# 按索引,獲取第一個sheet r_ws = r_wb.get_sheet_by_name(r_sheetnames[0]) # 按名稱,獲取指定名稱的sheet r_ws = r_wb.get_sheet_by_name('Sheet1') # 目前已棄用,不會報錯,但是又警告,建議用下面的方法 r_ws = r_wb['Sheet1'] # 呼叫正在執行的sheet r_ws = r_wb.active -
新建刪除sheet
# 新建sheet,不加index引數預設插在最後 ws1 = r_wb.create_sheet(title = "page1", index = 0) # 刪除sheet r_wb.remove_sheet(ws1) -
常用sheet屬性
- title:表格的標題
- dimensions:表格的大小,這裡的大小是指含有資料的表格的大小,即:左上角的座標:右下角的座標
- max_row:表格的最大行
- min_row:表格的最小行
- max_column:表格的最大列
- min_column:表格的最小列
- rows:按行獲取單元格(Cell物件) - 生成器
- columns:按列獲取單元格(Cell物件) - 生成器
- freeze_panes:凍結窗格
- values:按行獲取表格的內容(資料) - 生成器
-
獲取或修改屬性
# 修改標題 ws1.title = "Changed" # 打印表格大小 print('dimensions:', r_ws.dimensions) #輸出:A1:C4 # 獲取表格的最小行(最大行,最大最小列同理) min_r = r_ws.min_row #凍結第一行標題行 ws.freeze_panes = 'A2'
-
-
cell的屬性與操作
-
獲取cell
# 直接根據單元格的索引獲取,座標從(1, 1)開始 d = ws.cell(row = 4, column = 2) #通過行列讀 -
cell常用屬性
- row:單元格所在的行
- column:單元格坐在的列
- coordinate:單元格的座標
- value:單元格的值
-
獲取或修改屬性
# 列印 print('row:', r_ws.cell(row=2, column=2).row) print('column:', r_ws.cell(row=2, column=2).column) print('coordinate:', r_ws.cell(row=2, column=2).coordinate) print('value:', r_ws.cell(row=2, column=2).value) # 修改 r_ws.cell(row=2, column=2).value = '連海平' r_ws.cell(row=2, column=2, value = '共潮生')
-
-
遍歷表格資料
-
使用迭代器
# 按行操作 for row in r_ws.iter_rows('A1:C3'): # 兩種方式作用是一樣的 for cell in row: print('cell-value:', cell.value) for i in range(len(row)): print('row[i]:', row[i].value) -
按行列操作
# 用行數列數 for row in range(1, 4): for col in range(1, 4): w_ws.cell(row= row, column= col, value= 'test') print('row:', row, 'col:', col, 'value:', w_ws.cell(row= row, column= col).value)
-
-
利用公式
-
求和
r_ws['C5'] = "=SUM(C2:C4)" -
除法
r_ws['C6'] = "=SUM(C2:C3)/C4"
-
-
例項
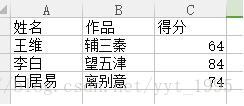
例子說明:讀入一個excel,內容如下:
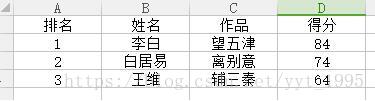
將其按得分排序後,在第一列插入一列排名,結果如下:
程式碼如下:#!/usr/bin/env python # -*- coding:utf-8 -*- import openpyxl # 讀入已有的excel(修改為自己檔案的路徑) r_wb = openpyxl.load_workbook(r'C:\Users\69540\Desktop\test-openpyxl.xlsx') # 獲取r_wb的sheet1 r_ws = r_wb.get_sheet_by_name('Sheet1') # 獲取讀入的資料 title = [] data = [] data_line = [] for n_row in range(r_ws.min_row, r_ws.max_row + 1): for n_col in range(r_ws.min_column, r_ws.max_column + 1): # 獲取標題行 if n_row == r_ws.min_row: title.append(r_ws.cell(row= n_row, column= n_col).value) # 獲取一行資料 else: data_line.append(r_ws.cell(row= n_row, column= n_col).value) # 將一行資料儲存至data列表,並清零data_line if data_line: data.append(data_line) data_line = [] # 處理資料 title_out = title data_out = data # 標題行第一列新增字串‘排名’ title_out.insert(0, '排名') # 資料部分按第三列的得分排序,降序排列 data_out.sort(key= lambda elem:elem[2], reverse= True) for i in range(len(data_out)): data_out[i].insert(0, i + 1) #將title的合併進data_out列表中 data_out.insert(0, title_out) # 新建excel及sheet,sheet命名為rank,將資料寫入 w_wb = openpyxl.Workbook() w_ws = w_wb.create_sheet(title = 'rank', index= 0) n_max_row = len(data_out) n_max_col = len(data_out[1]) for row in range(n_max_row): for col in range(n_max_col): # 寫入資料 w_ws.cell(row=row + 1, column=col + 1, value=data_out[row][col]) #將新建的excel以指定的名稱儲存在指定的路徑下(修改為自己檔案的路徑) w_wb.save(r'C:\Users\69540\Desktop\rank.xlsx')
Python處理.xls檔案
讀excel:使用xlrd庫
import xlrd
# 開啟一個已有的excel(當前路徑下,指定路徑下)
# workbook = xlrd.open_workbook('test-xlrd.xls')
workbook = xlrd.open_workbook(r'C:\Users\y84107470\PycharmProjects\excel-fun\test-xlrd.xls')
# sheet的操作
# 抓取所有sheet頁的名稱並列印
worksheets_name = workbook.sheet_names()
print('worksheets are:', worksheets_name)
# 定位到sheet: 1. 指定名稱獲取
#worksheet1 = workbook.sheet_by_name(u'Sheet1')
# 2.1 通過索引順序獲取
#worksheet1 = workbook.sheets()[0]
# 2.2 通過索引順序獲取
worksheet1 = workbook.sheet_by_index(0)
# 列印sheet的名稱,行數,列數
print('sheet_attr:', worksheet1.name, worksheet1.nrows, worksheet1.ncols)
# 讀取表值
# 遍歷sheet1中所有行row
num_rows = worksheet1.nrows
for curr_row in range(num_rows):
row_val = worksheet1.row_values(curr_row)
print('row%s is %s' % (curr_row, row_val))
# 遍歷sheet1中所有列col
num_cols = worksheet1.ncols
for curr_col in range(num_cols):
col_val = worksheet1.col_values(curr_col)
print('col%s is %s' % (curr_col, col_val))
# 遍歷sheet1中所有單元格cell
for rown in range(num_rows):
for coln in range(num_cols):
cell_val = worksheet1.cell_value(rown, coln)
print(cell_val)
#獲取單元格內容的資料型別(說明:ctype : 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error)
print('(1, 0)的型別為:', worksheet1.cell(1, 0).ctype) #第2行第1列:張三 為string型別
print('(1, 1)的型別為:', worksheet1.cell(1, 1).ctype) #第2行第2列:15 為number型別
寫excel:使用xlwt庫
#新建excel檔案並寫入資料,xlwt
import xlwt
#建立workbook和sheet物件
workbook = xlwt.Workbook() #注意Workbook的開頭W要大寫
sheet1 = workbook.add_sheet('sheet1', cell_overwrite_ok=True)
sheet2 = workbook.add_sheet('sheet2', cell_overwrite_ok=True)
#向sheet頁中寫入資料
name = ('李老栓', '張得帥', '曾牛逼')
score = ('22', '33', '44')
sheet1.write(0, 0, '姓名')
sheet1.write(0, 1, '得分')
for i in range(len(name)):
sheet1.write(i + 1, 0, name[i])
for i in range(len(score)):
sheet1.write(i + 1, 1, score[i])
#儲存該excel檔案,有同名檔案時直接覆蓋(儲存在當前資料夾下)
workbook.save('test-xlwt.xls')
#儲存該excel檔案,有同名檔案時直接覆蓋(儲存在指定資料夾下)
#workbook.save(r'C:\Users\y84107470\Desktop\test-xlwt.xls')
print('建立excel檔案完成!')
補充:寫excel的庫xlutils
import xlrd
import xlutils.copy
#開啟一個workbook
rb = xlrd.open_workbook('test.xls')
wb = xlutils.copy.copy(rb)
#獲取sheet物件,通過sheet_by_index()獲取的sheet物件沒有write()方法
ws = wb.get_sheet(0)
#寫入資料
ws.write(1, 1, 'changed!')
#新增sheet頁
wb.add_sheet('sheetnnn2', cell_overwrite_ok=True)
#利用儲存時同名覆蓋達到修改excel檔案的目的,注意未被修改的內容保持不變
wb.save('test.xls')
參考: