
論文筆記5:How to Discount Deep Reinforcement Learning:Towards New Dynamic Strategies
參考資料:How to Discount Deep Reinforcement Learning: ...
為幫助跟我一樣的小白,如果有大神看到錯誤,還請您指出,謝謝~
知乎同名:uuummmmiiii
創新點:相比於原始DQN不固定折扣因子(discount factor,γ),學習率(learning rate,α)
改進:變化discount factor 和 learning rate
改進原因:原始的DQN,即用NN代替Q表“儲存”Q值,會出現系統不穩定的情況(應該是涉及到強化學習中狀態之間有相關性,而NN中假設的輸入都是獨立同分布的問題)
帶來益處:加快學習演算法收斂,提高系統穩定性
Abstract
在強化學習中採用深度網路做函式估計已經取得了很大的進展(DQN),在DQN這個基準之上進行改進,本文闡述了discount factor在DQN的學習過程中起到的作用,當diacount factor在訓練過程中逐漸增長到它的最終值,我們實力驗證了這樣可以減少learning step,即加快收斂。如果再伴隨著learning rate的變化(減少),可以增加系統穩定性,表現在後面驗證中,可以降低過擬合。我們的演算法容易陷入區域性最優,採用actor-critic演算法增加exploration,防止陷入僵局和無法發現some parts of the state space.
Introduction
在強化學習中,深度神經網路可以代替Q表,解決狀態空間大使得記憶體不足的問題,但缺點是用NN會產生不穩定(Q值震盪或者發散)。
本文的研究動機取決於:棉花糖實驗(marshmallow),孩子們更傾向於等待更長時間換取更多的獎勵。
本文結構:首先回顧DQN中的一些equation;探索discount factor的作用;再加入learning rate進行實驗。
Instabilities of the online neural fitted Q-learning
discount factor作用與在機器學習中權衡bias-variance相似,discount factor 控制了策略複雜性的程度
Experiments
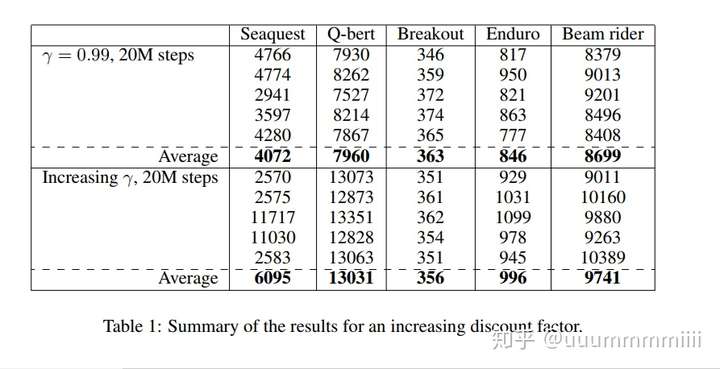
discount factor變化: =1-0.98(1-
)
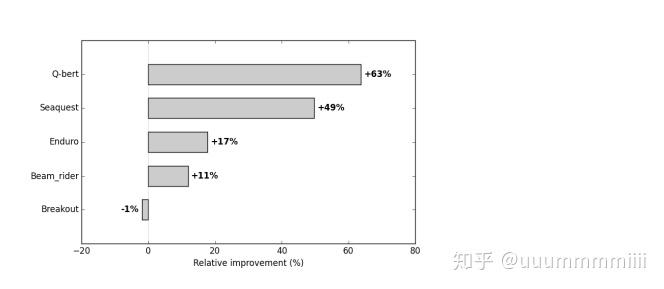 γ增加,有四個遊戲演算法學習更快
γ增加,有四個遊戲演算法學習更快
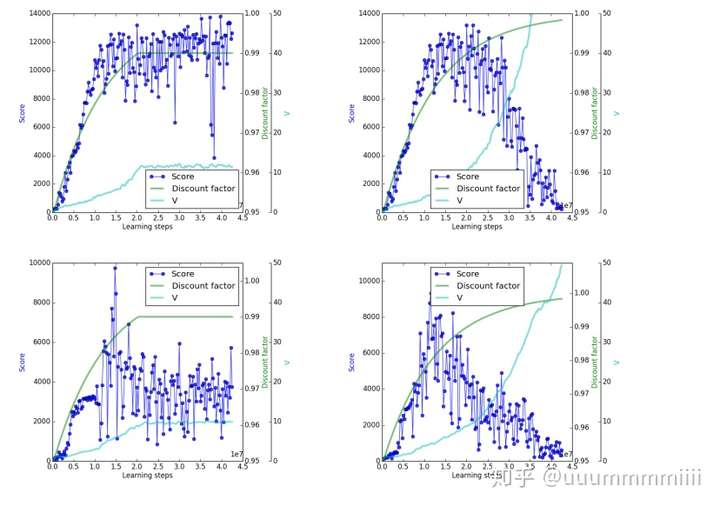 上面兩圖為第一個遊戲,下面兩圖第二個遊戲;左邊兩圖γ都逐漸增加到0.99後不變,右邊兩圖逐漸增加到接近1,可發現實際的scores較V值高很多,嚴重過擬合
上面兩圖為第一個遊戲,下面兩圖第二個遊戲;左邊兩圖γ都逐漸增加到0.99後不變,右邊兩圖逐漸增加到接近1,可發現實際的scores較V值高很多,嚴重過擬合
加入learning rate變化: =0.98
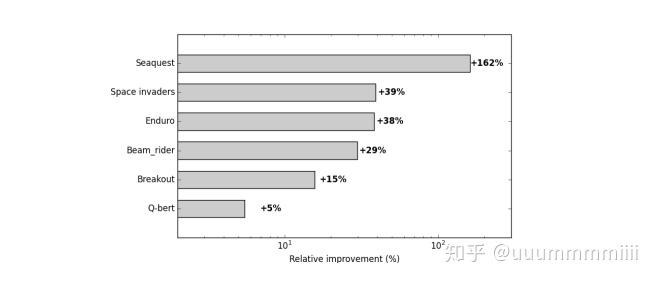
發現五個遊戲均減少了learning step
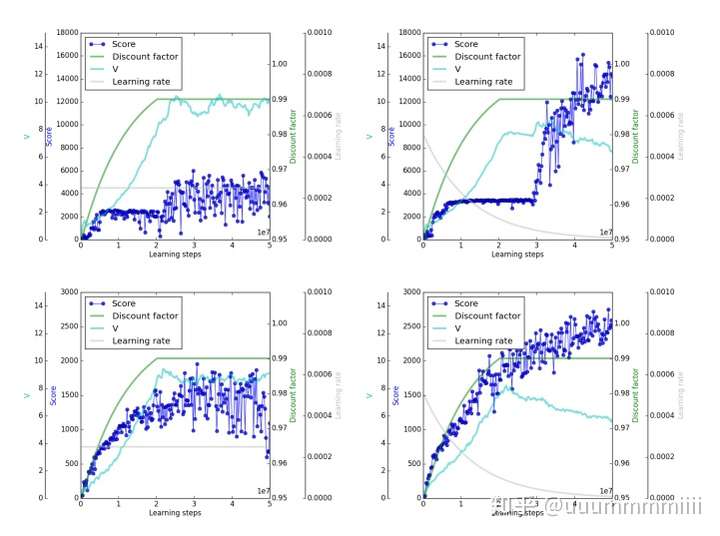 上面兩個圖表示第一個遊戲,下面兩圖表示第二個遊戲;γ均保持逐漸增加到0.99後不變,左邊表示learning rate不變,右邊兩圖表示learning rate逐漸減少
上面兩個圖表示第一個遊戲,下面兩圖表示第二個遊戲;γ均保持逐漸增加到0.99後不變,左邊表示learning rate不變,右邊兩圖表示learning rate逐漸減少
表示當discount factor保持逐漸增加到0.99後不變,逐漸減少learning rate,使得V值會降低,減少過擬合
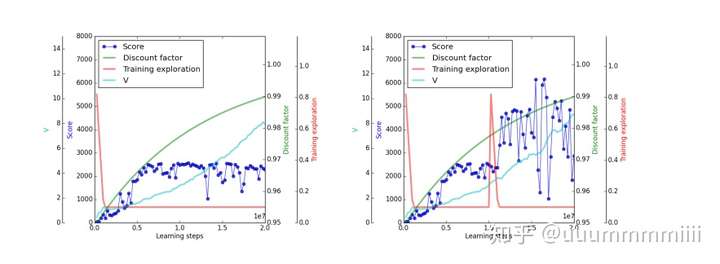 對於遊戲seaquest,actor-critic演算法可以跳出區域性最優
對於遊戲seaquest,actor-critic演算法可以跳出區域性最優