
python資料預處理 :資料標準化
何為標準化:
在資料分析之前,我們通常需要先將資料標準化(normalization),利用標準化後的資料進行資料分析。資料標準化也就是統計資料的指數化。資料標準化處理主要包括資料同趨化處理和無量綱化處理兩個方面。資料同趨化處理主要解決不同性質資料問題,對不同性質指標直接加總不能正確反映不同作用力的綜合結果,須先考慮改變逆指標資料性質,使所有指標對測評方案的作用力同趨化,再加總才能得出正確結果。資料無量綱化處理主要解決資料的可比性。
幾種標準化方法:
歸一化Max-Min
min-max標準化方法是對原始資料進行線性變換。設minA和maxA分別為屬性A的最小值和最大值,將A的一個原始值x通過min-max標準化對映成在區間[0,1]中的值x’,其公式為:
新資料=(原資料-最小值)/(最大值-最小值)
這種方法能使資料歸一化到一個區域內,同時不改變原來的資料結構。
實現中心化Z-Score
這種方法基於原始資料的均值(mean)和標準差(standard deviation)進行資料的標準化。將A的原始值x使用z-score標準化到x’。
z-score標準化方法適用於屬性A的最大值和最小值未知的情況,或有超出取值範圍的離群資料的情況。
新資料=(原資料-均值)/標準差
這種方法適合大多數型別資料,也是很多工具的預設標準化方法。標準化之後的資料是以0為均值,方差為以的正太分佈。但是Z-Score方法是一種中心化方法,會改變原有資料的分佈結構,不適合用於對稀疏資料做處理。
很多時候資料集會存在稀疏特徵,表現為標準差小,很多元素值為0,最常見的稀疏資料集是用來做協同過濾的資料集,絕大部分資料都是0。對稀疏資料做標準化,不能採用中心化的方式,否則會破壞稀疏資料的結構。
用於稀疏資料的MaxAbs
最大值絕對值標準化(MaxAbs)即根據最大值的絕對值進行標準化,假設原轉換的資料為x,新資料為x’,那麼x’=x/|max|,其中max為x鎖在列的最大值。
該方法的資料區間為[-1, 1],也不破壞原資料結構的特點,因此也可以用於稀疏資料,一些稀疏矩陣。
針對離群點的RobustScaler
有些時候,資料集中存在離群點,用Z-Score進行標準化,但是結果不理想,因為離群點在標準化後喪失了利群特性。RobustScaler針對離群點做標準化處理,該方法對資料中心化的資料的縮放健壯性有更強的引數控制能力。
python實現
import numpy as 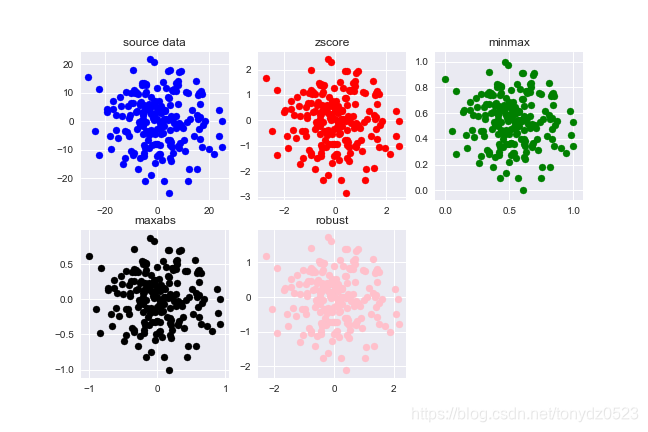
參考:
《python資料分析與資料化運營》 宋天龍