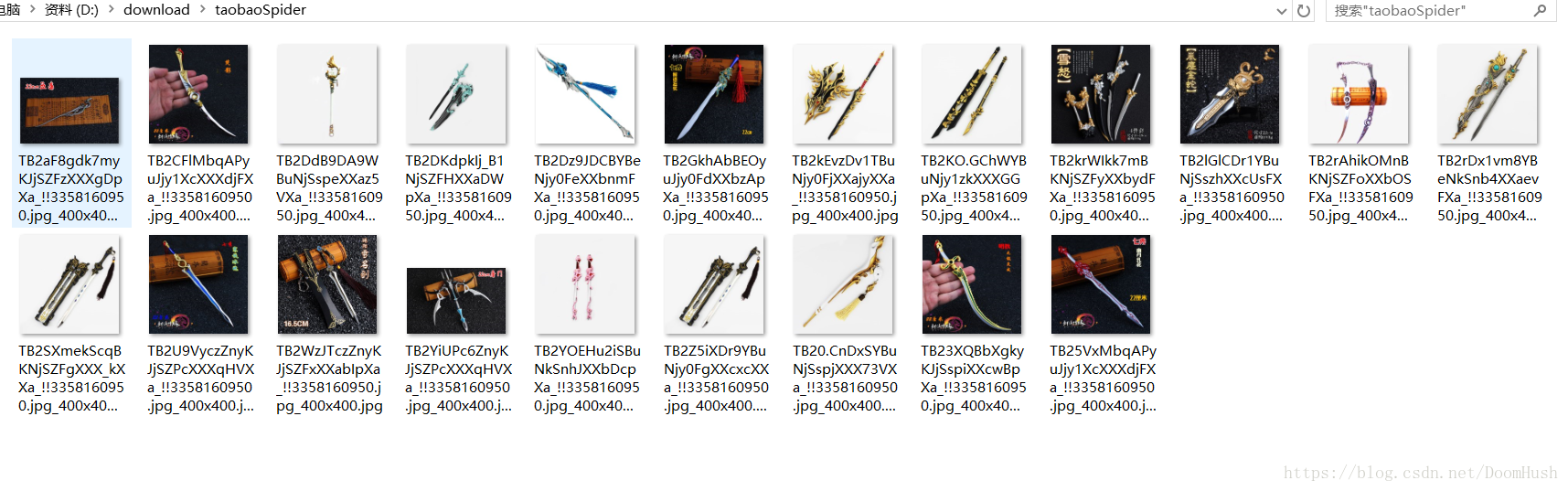
python從零學——scrapy初體驗
python從零學——scrapy初體驗
近日因為一些事情,需要從網上爬取一些東西,故而想通過使用爬蟲來順便學習下強大的python。現將一些學習中遇到的問題記錄下來,以便日後查詢
1. 開發環境的準備(本人windows10 x64)
python的爬蟲框架應該說是有挺多的了,使用scrapy也是因為它名氣比較大啦。首先是安裝使用,因為我也是從零開始,從開始安裝python開始的,所以我也就從安裝python開始的。
1.1 python安裝
一開始,我安裝的是python3.7,但是在安裝scrapy的時候,發現一直出現依賴錯誤“Microsoft Visual C++ 14.0 is required”這個蛋疼的錯誤,死活調不好,直到我在scrapy的
$(python的安裝路徑)
$(python的安裝路徑)\Scripts
我的路徑是
D:\softwares\Python27 D:\softwares\Python27\Scripts
安裝完成以後,win+R執行cmd,輸入python看下有反應不,如果有就說明已經安裝好了。
1.2 安裝python IDE,PyCharm
PyCharm好像用的比較多,我就安裝這個了,看起來是用visual studio那一套做的,很像。PyCharm有分專業版和社群版的,作為一個窮逼當然是下載社群版本的啦。國內使用者好像無法直接開啟連結,但是好像下載連結是可以用的,那我就像上面的pyhon一樣貼一個下載地址吧:pycharm2018.1.4。
1.3 scrapy安裝
python有一個很好的地方,就是有一個包管理系統(pip)來管理python的包,咱們想要使用的scrapy包就能很方便的下載下來,而不必去網上到處找。之前我們安裝的python2.7.15已經預設安裝了pip,所以現在我們就使用pip來安裝一下scrapy好了。在cmd裡面輸入一下命令:
pip install scrapy
然後如果沒有意外的話,一般會出現以下包缺失的提示:
building 'twisted.test.raiser' extension error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
不要慌,到這個網站上下載對應沒有編譯的包就行了,我們就不用在自己電腦上編譯了。這裡是twisted缺失,所以我根據我的系統和python的版本,選擇了這個Twisted‑18.7.0‑cp27‑cp27m‑win_amd64.whl下載。下載好了以後,用cmd來安裝,輸入以下的命令
pip install d:\Twisted-18.7.0-cp27-cp27m-win_amd64.whl
然後安裝 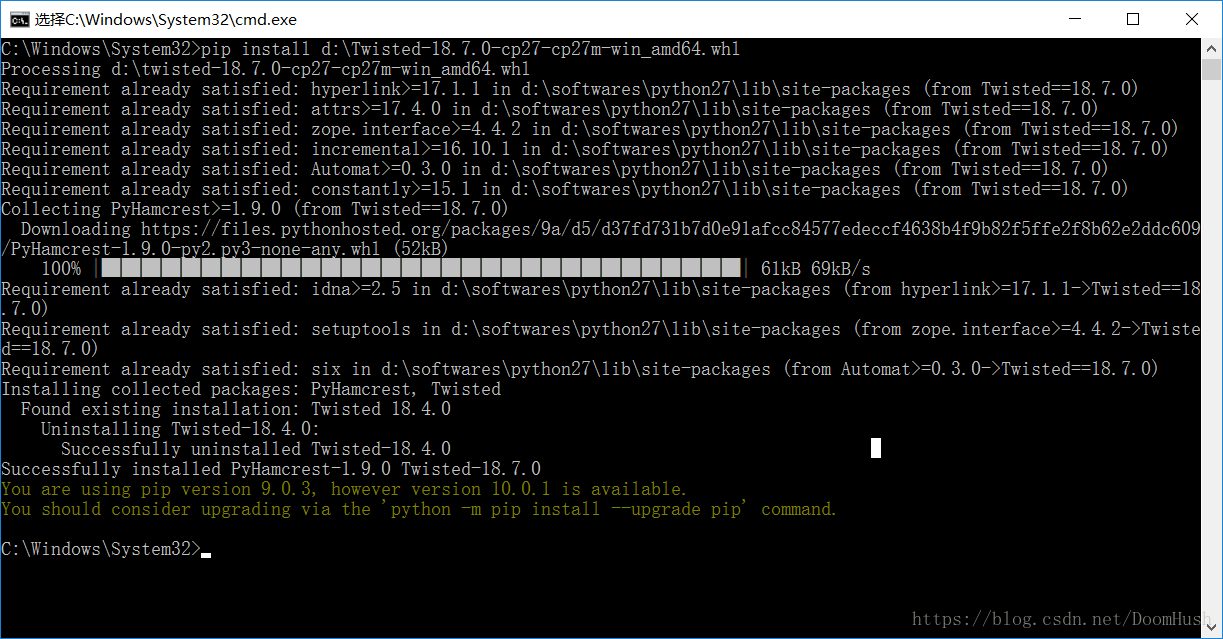
pip install scrapy然後看有沒有其他的依賴錯誤,如果有的話就跟剛才一樣處理就行了。 到此為止,scrapy需要的環境都安裝完畢了,接下來就是使用scrapy來爬取東西了
2. 爬取靜態圖片
用某寶的寶貝頁面來爬取是最好的了,因為某寶的寶貝頁面不僅有靜態的資料還有動態的資料,很適合學習。我們先來爬取這部分的圖片:
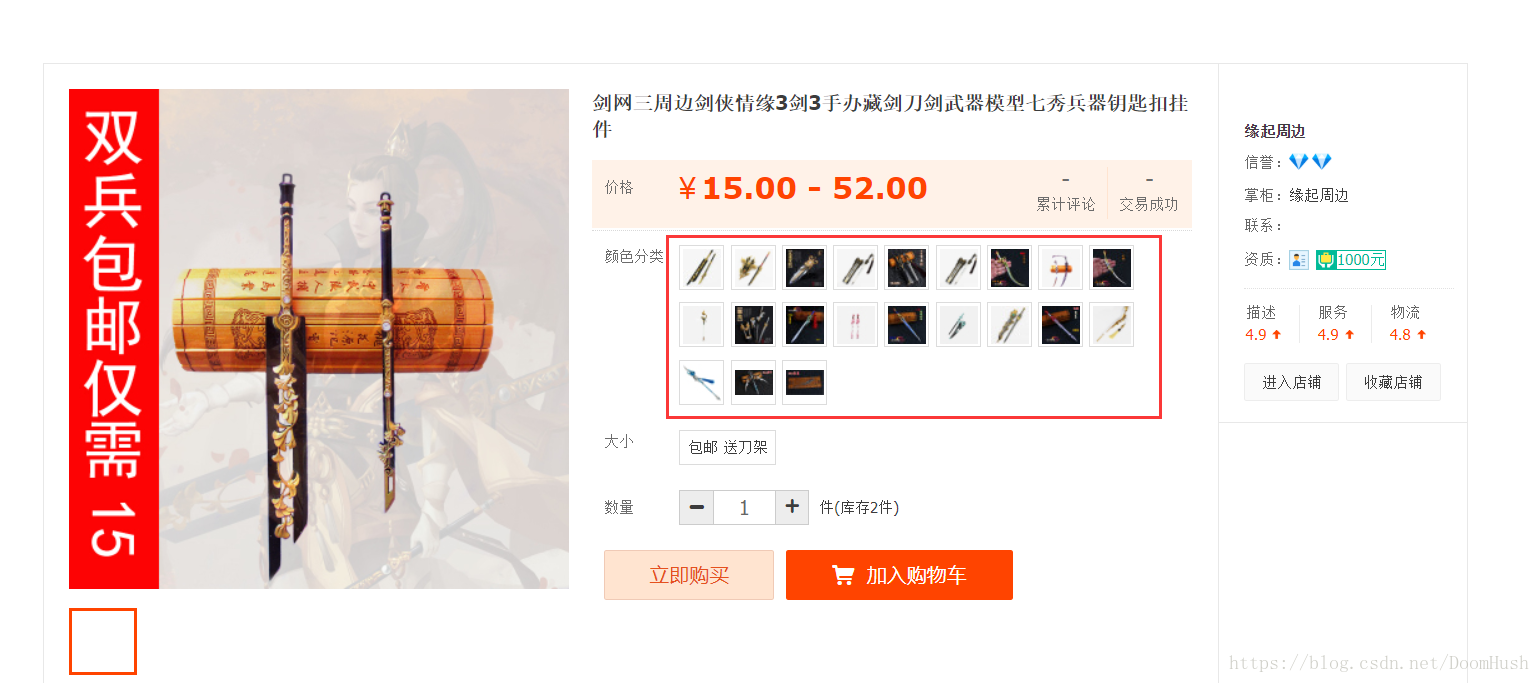
2.1 建立scrapy專案
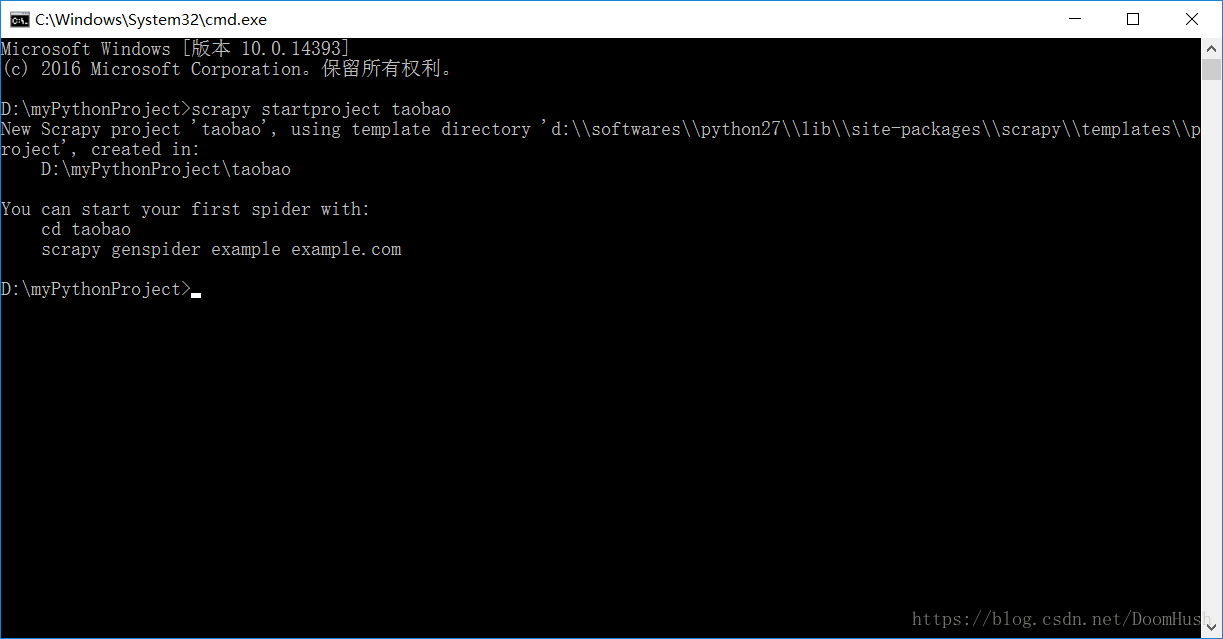
首先,使用以下命令來建立一個空的scrapy專案。
scrapy startproject taobao
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class taobaoItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
image_urls = scrapy.Field()
這裡,我們要存的就是寶貝的地址,名字和圖片的地址。 然後我們新建一個spider,叫taobaoSpider好了。spider是用來請求網頁和獲取爬取目標的地址的。說白了做一些處理連結的工作。
# -*- coding: utf-8 -*-
import scrapy
from scrapy.selector import Selector
from taobao.items import taobaoItem
from scrapy_splash import SplashRequest
class taobaoSpider(scrapy.Spider):
name = "taobao"
allowed_domains = ["taobao.com"]
start_urls = []
def start_requests(self):
input_url = 'https://item.taobao.com/item.htm?spm=a1z10.1-c.w4023-18381915794.4.44d14551es5Ex7&id=556114290901'
self.start_urls.append(input_url)
for url in self.start_urls:
yield SplashRequest(url=url, callback=self.parse)
def parse(self, response):
# sel是頁面原始碼,載入scrapy.selector
sel = Selector(response)
for link in sel.xpath('//*[@id="J_isku"]/div/dl[1]/dd/ul/li/a'):
url = link.xpath('@style').extract()[0]
image_url = "http://" + url[17:-28] + "400x400.jpg"
image_urls = []
image_urls.append(image_url)
name = link.xpath('span/text()').extract()
item = taobaoItem()
item['url'] = url
item['name'] = name
item['image_urls'] = image_urls
yield item # 返回請求
接下來修改settings.py,這個檔案是配置檔案,配置一些引數:
# -*- coding: utf-8 -*-
# Scrapy settings for taobao project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'taobao'
SPIDER_MODULES = ['taobao.spiders']
NEWSPIDER_MODULE = 'taobao.spiders'
ITEM_PIPELINES = {
'taobao.pipelines.taobaoPipeline': 1,
}
#設定圖片下載路徑
IMAGES_STORE = 'd:/download'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
注意:這裡ROBOTSTXT_OBEY 預設是True,這是scrapy預設遵守爬取協議。如果這裡為Ture,則無法爬取淘寶的資料,會出現一下的提示。所以需要改為False 
ROBOTSTXT_OBEY = False
最後設定piplines,用於持久化爬取的資料,也就是儲存到硬碟或者資料庫裡面的東西:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import requests
from taobao import settings
import os
class taobaoPipeline(object):
def process_item(self, item, spider):
if 'image_urls' in item: # 如何‘圖片地址’在專案中
images = [] # 定義圖片空集
dir_path = '%s/%s' % (settings.IMAGES_STORE, spider.name)
if not os.path.exists(dir_path):
os.makedirs(dir_path)
for image_url in item['image_urls']:
us = image_url.split('/')[-1:]
image_file_name = '_'.join(us)
file_path = '%s/%s' % (dir_path, image_file_name)
images.append(file_path)
if os.path.exists(file_path):
continue
with open(file_path, 'wb') as handle:
headers = {
'user-agent': "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0",
'cookie': "user_trace_token=20170502200739-07d687303c1e44fa9c7f0259097266d6;"
}
response = requests.get(image_url, stream=True, headers=headers)
for block in response.iter_content(1024):
if not block:
break
handle.write(block)
return item
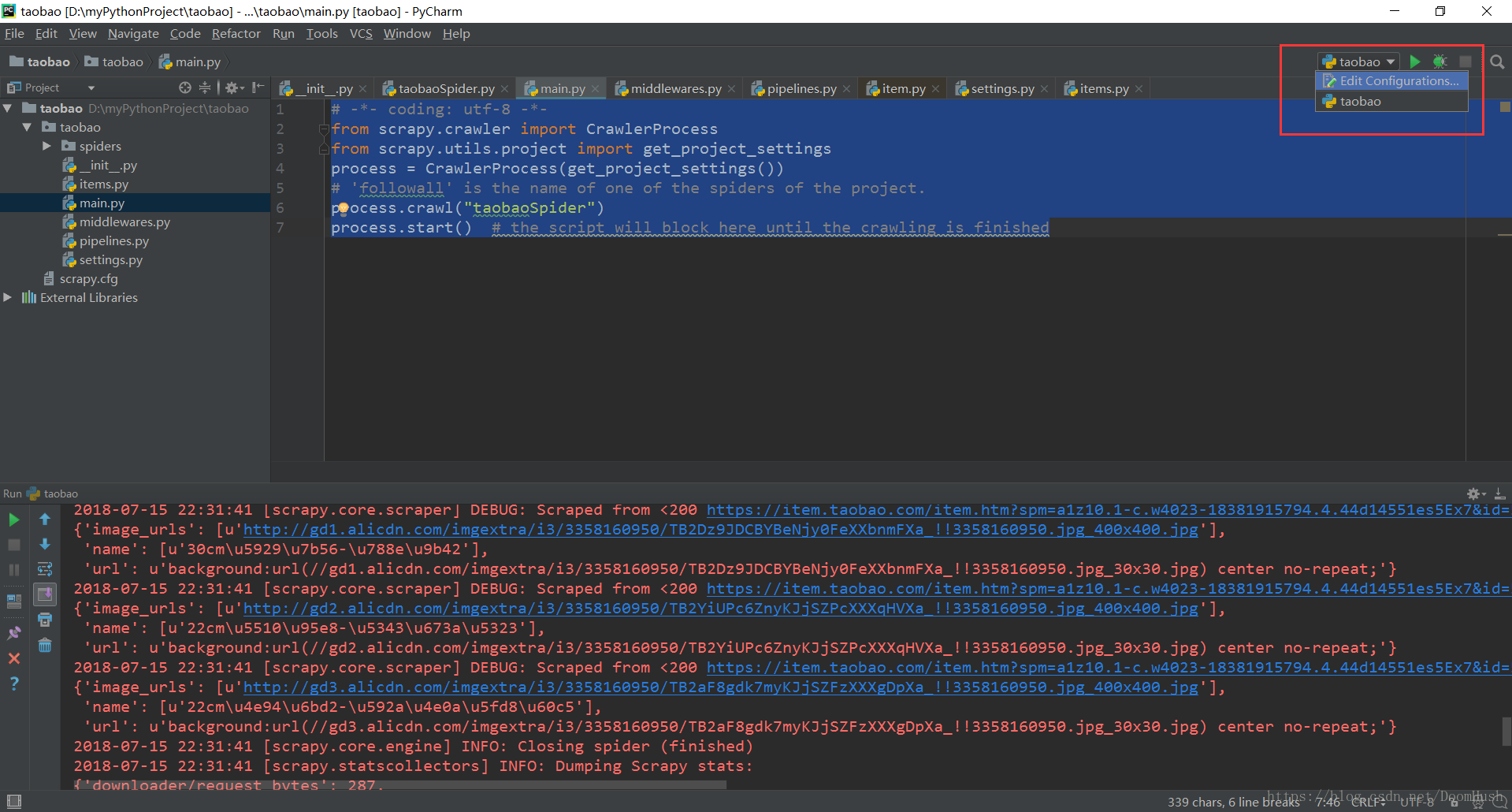
最後在taobao目錄下,新建一個main.py檔案,用於啟動這個爬蟲(crawl):
# -*- coding: utf-8 -*-
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
process = CrawlerProcess(get_project_settings())
# 'followall' is the name of one of the spiders of the project.
process.crawl("taobaoSpider")
process.start() # the script will block here until the crawling is finished
專案的目錄現在是這樣的:
D:\download\taobaoSpider目錄了。