
指令跳轉與預測
branch指令只有進入decode階段,CPU才能知道是否跳轉。Branch進入到ALU階段,CPU才知道是否taken。

有什麼方式可以降低這種flush掉沒用的指令。CPU不知道會不會跳轉,以及不知道會跳轉到哪裡去。如果在TETCH有可以預測branch是否taken,或者知道taken之後的下一條指令,效率提高。怎麼去做到branch。
如何預測?
1.該指令是否是branch指令?
2.判斷是否taken。
3.如果taken,目標地址在哪裡?
對CPI的影響?
CPI = 1+(mis-predicted/instructions)*penalty
其中penalty就是要Flush掉的指令數量。
下面一個例子:

1+0.1×0.2×2=1.04是什麼意思?
90%的指令預測準確率,那麼有0.1的概率錯誤預測,0.2表示有20%的指令是Branch,2代表有2條指令被Flush掉。
可見在流水線級數很長的情況下,branch的精確度對效能影響非常大。
預測branch的思路?

一條指令執行的模式是由規律的,這裡用到branch的歷史執行方式。
Branch Target Buffer BTB概念,用來存放Branch目標的,當然,已經知道branch是被taken的。Branch目標地址就存放在BTB中,如果該次沒預測對,那麼就會更新BTB中的PCnext。如何設計BTB,就是越快越好,那麼這個buffer儘可能小。使用PC的低10bit作為BTB的entry。因為正常程式在執行的時候,地址每次加4,也就是隻有低bit在改變。
簡單的預測banch的方法。1bit 預測。解決branch是否taken。

也就是,現在有條branch指令,走到ALU階段,這條branch被執行了,然而上次branch沒被執行,BHT中存放的是0:Branch is not taken,這是就修改BHT中的值為1:Branch is taken。那麼下次在執行Branch的時候,我們預測他會被執行。
1bit預測的優劣。當一條branch總是taken或者taken遠大於不taken,或者正好相反,那麼1 bit預測就可以工作很好。但是如果taken 和not kaken次數差不多時候,這個1 bit預測就不管用了。
2bit 預測,和1bit預測原理差不多,只是多了2種情況。
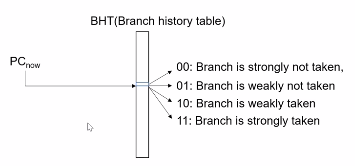

一條強烈不執行的branch被taken了,那麼就會進入weakly not taken狀態,下次就是直接進入可能不執行的狀態,但是下次真的沒執行,那麼就回到強烈不執行狀態;如果被taken了,那麼進入到可能執行的狀態。相比於1 bit預測,從not kaken到taken,需要兩次branch taken。
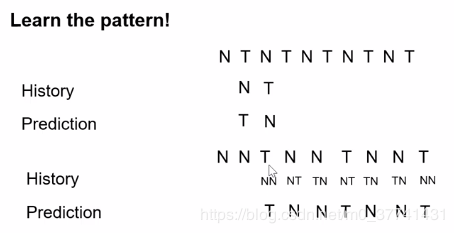
從圖中可以看出,當前兩條為NN的時候,那麼下一條CPU就預測為Taken;當前兩條為Not Taken和Taken的時候,那麼下一條預測為Not Taken。基於歷史來做預測,準確度會更高。
CPU一般是基於2-bits history predict來做的。
對於函式的返回值指令,如何預測呢?
0x1230: Call FUN
.
.
.
0x1250: Call FUN
FUN:
RET
PC到0x1230,呼叫FUN ,FUN執行完後執行RET,回到1230地址,在BTB中更新為1230地址;當程式執行到1250後,有呼叫FUN,再執行RET,之前BTB已經更新RET為1230,而不是1250,這樣子會導致mis-predict(本應該回到1250),這時BTB會更新到1250;如果程式LOOP到1230,那麼每一次branch按照BTB的預測都會失敗。解決這個問題,引入RAS(Return address stack),採用棧的方式解決。執行0x1230的時候,把0x1230push到棧中,RET的時候從棧中取0x1230,當從0x1250呼叫FUN的時候,把0x1250push到棧中,RET的時候,從棧中調取0x1250。