
【Python】搭建你的第一個簡單的神經網路_實踐篇_NN&DL學習筆記(三)
前言
本文為《Neural Network and Deep Learning》學習筆記(三),可以轉載但請標明原文地址。
本人剛剛入門、筆記簡陋不足、多有謬誤,而原書精妙易懂、不長篇幅常有柳暗花明之處,故推薦閱讀原書。
《Neural Network and Deep Learning》下載地址(中文版):Neural Network and Deep Learning(中文版)
注:這本書網上有很多免費版,隨便搜一下就有了,不用非得花積分下載我上傳的資料。
第三部分:實踐篇(識別手寫數字程式碼)
一、程式碼下載、環境準備、執行!
1、程式碼下載
本文所需程式碼及資料集下載地址:
本文所需下載資料檔名為NeuralNetworks,內容如下所示:

其中,mnist.pkl.gz為資料集檔案(也就是50000張手寫圖片的訓練集);
mnist_loader.py實現從資料集中載入並預處理資料(將圖片重設大小之類的操作);
network.py實現了我們在
run.py先進行資料載入,再建立一個神經網路並向其傳遞引數,使這個神經網路開始學習。
2、環境準備
本人使用的是Anaconda3,IDE為自帶的Spyder,所需python版本為2.7
首先我們需要新建一個環境,【開啟Anaconda Navigator】—【選擇左側Environments】—【選擇中間底部的Create】
環境名字Name隨便起一個,假設我起的名字是py27(圖中起名叫NN只是為了做演示),python版本選擇2.7,然後點選Create。

之後我們需要下載所需包,在中間一列點選剛剛建立好的環境,在右側選擇Not Installed,分別搜尋spyder和numpy點選下載,所需時間可能稍長,請耐心等待。


之後我們就可以擁有一個python版本為2.7的Spyder了,它的快捷方式應該是這樣的,白框內的是我的環境名字py27:

3、執行!
雙擊開啟這個Spyder,點選Projects——New Project——Existing directory,在Location中選擇你下載的NeuralNetworks檔案位置,點選選擇資料夾——返回點選Create。

然後左側會出現下載好的資料夾中的各檔案:

雙擊mnist_loader.py檔案,找到第44行,將選中部分改成自己的資料夾下載後放置的路徑,然後點選左上角儲存。

雙擊run.py檔案,點選左上角執行。

然後,就可以靜靜等待右下角輸出結果了。
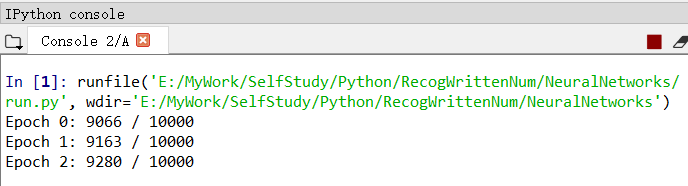
輸出結果格式為:迭代期 0-29:正確測例個數/總測例個數。
上圖可見,準確率達到了百分之九十以上,而且隨著迭代期的增長而不斷增加,當迭代期達到第30個時,準確率達到了百分之九十五以上。

執行成功之後,我們來看看程式碼吧。
二、程式碼解釋:network.py
對於mnist_loader.py,因為不涉及到神經網路的架構,且邏輯簡單,只是處理資料的過程,所以不做解釋(其實是懶吧喂!)
對於run.py,也很簡單,不做解釋。
所以這部分中,只解釋network.py中的程式碼,但如果看註釋就ok的話,就完全可以不用看下面的內容了。
原文程式碼中註釋是英文的,我刪除了一些、翻譯了一些、又增添了一些,有信仰的話可以直接閱讀原始碼。
下面我們分塊介紹:
1、初始化一個network物件
# 構造一個三層神經網路
# 輸入層、隱藏層、輸出層
class Network(object):
# 初始化神經網路
def __init__(self, sizes):
# size包含各層神經元的數量
# net = Network([2, 3, 1])表示建立一個三層神經網路
# 第一層有2個神經元,第二層有3個,第三層有1個
# 第一層為輸入層,故不設定偏置biases
# 偏置biases僅在後面的層中用於計算輸出
self.num_layers = len(sizes)
self.sizes = sizes
# 偏置biases和權重weights被隨機初始化
# 使用np.random.randn函式來生成均值為0,標準差為1的高斯分佈
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in list(zip(sizes[:-1], sizes[1:]))]在初始化network物件時,我們應該輸入一個向量sizes,代表各層神經元的數量。
例如在run.py中,我們輸入的向量為[784, 30, 10]
故層數num_layers=sizes的維數,即3層;
接下來我們需要呼叫np.random.randn函式給我們的引數【權重weights】和【偏置biases】初始化一個隨機量,好接下來進行迭代。
(np.random.randn函式會生成均值為0,標準差為1的高斯分佈。)
randn(y,1)的意思是:初始化y*1的矩陣,其中y的取值從sizes[1]開始到sizes陣列的末尾,在本題中也就是30和10.
之所以不從sizes[0]開始,是因為第0層為輸入層,不需要設定偏置。
同理,randn(y,x)的意思是:初始化y*x的矩陣,其中x的取值從sizes[0]開始到sizes陣列的倒數第二個,sizes[:-1]的意思就是把倒數第一層去掉,本題中也就是784和30,y的取值依舊是30和10.
為什麼要把倒數第一層去掉呢?因為我們的神經網路是這樣的:
第一層input layer→第二層的輸入:此時需要權重(一個30*784的矩陣)來表示第一層784個神經元的不同重要性;
第二層的輸出→第三層的輸入:此時需要權重(一個10*30的矩陣)來表示第二層30個神經元的不同重要性;
第三層的輸出output:結果。
倒數第一層就是輸出層了,當然不需要權重了啊。
2、啟用函式:S型函式
# 對於網路給定一個輸入a,對其啟用後返回對應的輸出a
def feedforward(self, a):
# 啟用函式
for b, w in list(zip(self.biases, self.weights)):
a = sigmoid(np.dot(w, a)+b)
return a
# 中間程式碼省略
def sigmoid(z):
# 啟用函式:S函式
return 1.0/(1.0+np.exp(-z))啟用函式的計算過程:輸入a→計算w*a+b→計算sigmoid(w*a+b)→將計算結果作為輸出
3、學習過程:SGD
# 學習演算法
def SGD(self,
training_data, # 一個(x,y)元組列表,
# 表示訓練輸入及對應的期望輸出
epochs, # 迭代期數量
mini_batch_size, # 取樣時的小批量資料的大小
eta, # 學習速率
test_data=None): # 若選中該引數,則程式會在每個訓練器後評估網路,
# 打印出部分進展,會拖慢執行速度
if test_data: n_test = len(list(test_data))
n = len(list(training_data))
# 程式碼工作流程:
# 在每個迭代期epochs,
for j in range(epochs):
# 首先隨機的將訓練資料打亂
random.shuffle(training_data)
# 然後將它分成多個適當大小的小批量資料mini_batch
# 每個mini_batch都是一個(x,y)元組列表
mini_batches = [
training_data[k:k+mini_batch_size]
for k in range(0, n, mini_batch_size)]
# 對於每一個mini_batch,我們應用一次梯度下降
for mini_batch in mini_batches:
# 該方法使用mini_batch中的訓練資料,根據單次梯度下降的迭代
# 更新網路的權重和偏置
self.update_mini_batch(mini_batch, eta)
# 若test_data為真,輸出每個迭代期Epoch:正確測試數/總測試數
if test_data:
print("Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test))
else:
print("Epoch {0} complete".format(j))SGD方法所需引數:訓練集資料(輸入與期望輸出),迭代期數量,小批量資料大小,學習速率eta,測試集資料
SGD方法工作流程:
在每個迭代期中:
① 將訓練資料trainging_data打亂,亂序
② 將訓練資料分成k份小批量資料mini_batch,每份大小為傳入的引數mini_batch_size
③ 對於每一個mini_batch,呼叫update_mini_batch方法,應用梯度下降,更新一次權重w和偏置b
④ 呼叫evaluate方法,用test_data測試集資料進行測試(也叫評估網路),列印網路準確率
⑤ 本迭代期結束,進入下一個迭代期,直到達到迭代期數量epochs停止
4、更新權重和偏置:update_mini_batch
# 該方法使用mini_batch中的訓練資料,根據單次梯度下降的迭代更新網路的權重和偏置
# 具體方法:對mini_batch中的每一個訓練樣本計算梯度,然後更新權重和偏置
def update_mini_batch(self, mini_batch, eta):
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
# 下面這行程式碼呼叫了反向傳播演算法,一種快速計算代價函式loss的梯度的方法
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in list(zip(nabla_b, delta_nabla_b))]
nabla_w = [nw+dnw for nw, dnw in list(zip(nabla_w, delta_nabla_w))]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in list(zip(self.weights, nabla_w))]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in list(zip(self.biases, nabla_b))]可以看到:核心程式碼為呼叫backprop方法,即反向傳播演算法,來快速計算代價函式(C)的梯度。
而可以看到,最後兩行正是我們在準備篇最後推匯出來的公式:
5、反向傳播演算法:backprop
我們將在下章下個系列的學習筆記中展示反向傳播演算法的工作,現在只需知道其返回與訓練樣本x相關代價的適當梯度,以便於我們更新權重和偏置就好。
三、嘗試調參
在run.py中,我們傳遞了許多引數,比如隱藏層神經元為30個,還有許多超引數,比如迭代期為30次,小批量資料大小為10,學習速率為3.0,那麼調整這些引數,對準確率有何影響呢?
注:權重w和偏置b的初始化也很重要,但本文用的是隨機初始化,因此打印出的準確率可能每次差異略大。
1、將隱藏層神經元改到100
顯而易見,執行時間變…長…了,但準確率提高了。
ps:如果你的準確率沒有提高,不要懷疑我,更不要懷疑作者。拜隨機初始化w和b所賜,每一次的執行結果都是玄學。

2、將學習速率分別改到0.001和100.0
令人傷心的是,學習速率過小、過大都會使準確率大幅度下降。
(凌晨一點了,原諒我懶得測試全部迭代期orz,領會精神就好,引數很重要!)


調參是一門玄學嗎?
作者:調參是一門藝術。
我們需要啟發式方法來選擇好的超引數和好的結構,我們會在接下來的學習中討論這些。
四、
【2018/11/20後記】
1、又肝到凌晨一點,終於把本書第1章的學習筆記整理完了……沒想到一共寫了3篇這麼多orz,一開始就想寫個提綱式的東西,沒想到寫著寫著就動了情(呸),寫著寫著就投入感情了,就像每次凌晨為自己深愛的專案、親自動手一點一點寫報告、做各種測試分析……一樣的真情實感。
2、接下來還有
第2章:反向傳播演算法如何工作;
第3章:改進神經網路的學習方法;
第4章:神經網路可以計算任何函式;
第5章:深度神經網路為何很難訓練;
以及最後一章:深度學習。
然而最近真的要準備考試了,再不準備就要被掛科勸退了orz,所以,等有時間再更吧。
再次推薦閱讀原書,真的對新手超級友好。
3、下週二考完試之前不再上CSDN了,qwq。考完試之後大概會把三個大作業的原始碼整理好發上來。