
Objective-C runtime機制(7)——SideTables, SideTable, weak_table, weak_entry_t
在runtime中,有四個資料結構非常重要,分別是SideTables,SideTable,weak_table_t和weak_entry_t。它們和物件的引用計數,以及weak引用相關。
關係
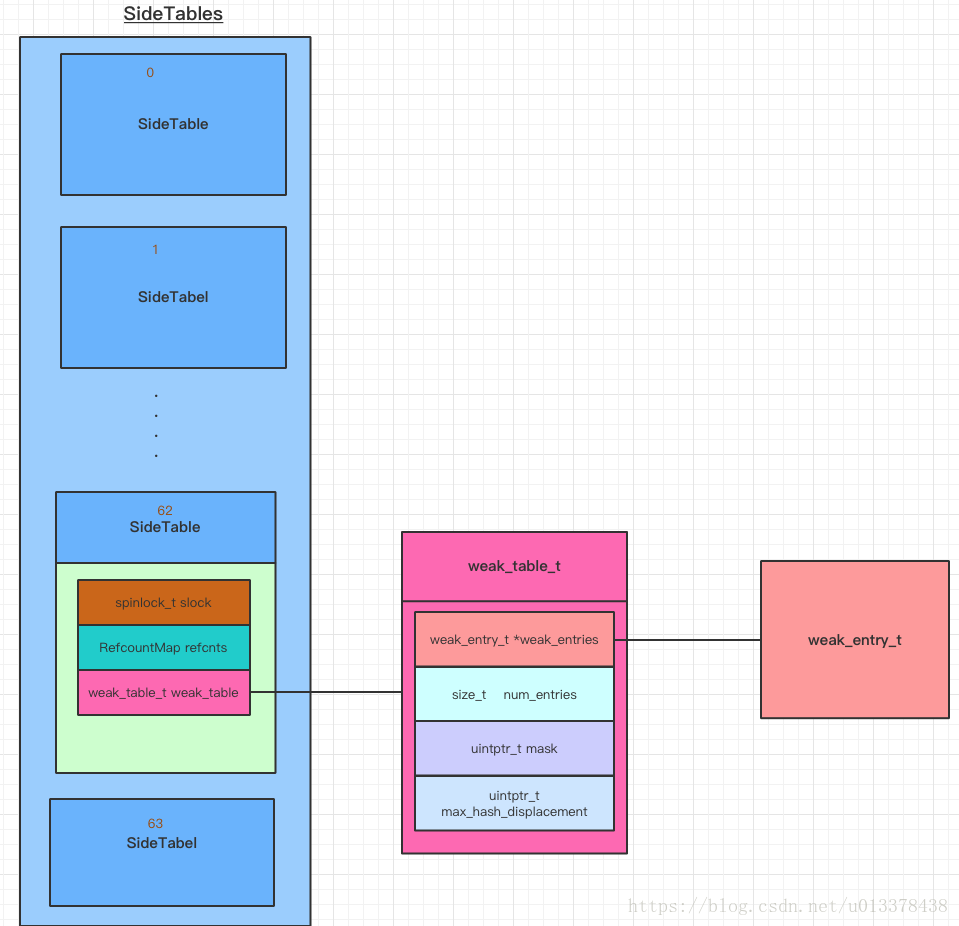
先說一下這四個資料結構的關係。 在runtime記憶體空間中,SideTables是一個64個元素長度的hash陣列,裡面儲存了SideTable。SideTables的hash鍵值就是一個物件obj的address。
因此可以說,一個obj,對應了一個SideTable。但是一個SideTable,會對應多個obj。因為SideTable的數量只有64個,所以會有很多obj共用同一個SideTable
而在一個SideTable中,又有兩個成員,分別是
RefcountMap refcnts; // 物件引用計數相關 map
weak_table_t weak_table; // 物件弱引用相關 table
其中,refcents是一個hash map,其key是obj的地址,而value,則是obj物件的引用計數。
而weak_table則儲存了弱引用obj的指標的地址,其本質是一個以obj地址為key,弱引用obj的指標的地址作為value的hash表。hash表的節點型別是weak_entry_t。
這四個資料結構的關係如下圖:
SideTables
先來說一下最外層的SideTables。SideTables可以理解為一個全域性的hash陣列,裡面儲存了SideTable型別的資料,其長度為64。
SideTabls可以通過全域性的靜態函式獲取:
static StripedMap<SideTable>& SideTables() {
return *reinterpret_cast<StripedMap<SideTable>*>(SideTableBuf);
}
可以看到,SideTabls 實質型別為模板型別StripedMap 。StripedMap直譯過來是“有條紋的Map”,不知道為什麼叫做這個鳥名字。
StripedMap
我們繼續來看StripedMap模板的定義:
// StripedMap<T> is a map of void* -> T, sized appropriately
// for cache-friendly lock striping.
// For example, this may be used as StripedMap<spinlock_t>
// or as StripedMap<SomeStruct> where SomeStruct stores a spin lock.
template<typename T>
class StripedMap {
enum { CacheLineSize = 64 };
#if TARGET_OS_EMBEDDED
enum { StripeCount = 8 };
#else
enum { StripeCount = 64 }; // iOS 裝置的StripeCount = 64
#endif
struct PaddedT {
T value alignas(CacheLineSize); // T value 64位元組對齊
};
PaddedT array[StripeCount]; // 所有PaddedT struct 型別資料被儲存在array陣列中。iOS 裝置 StripeCount == 64
static unsigned int indexForPointer(const void *p) { // 該方法以void *作為key 來獲取void *對應在StripedMap 中的位置
uintptr_t addr = reinterpret_cast<uintptr_t>(p);
return ((addr >> 4) ^ (addr >> 9)) % StripeCount; // % StripeCount 防止index越界
}
public:
// 取值方法 [p],
T& operator[] (const void *p) {
return array[indexForPointer(p)].value;
}
const T& operator[] (const void *p) const {
return const_cast<StripedMap<T>>(this)[p];
}
// Shortcuts for StripedMaps of locks.
void lockAll() {
for (unsigned int i = 0; i < StripeCount; i++) {
array[i].value.lock();
}
}
void unlockAll() {
for (unsigned int i = 0; i < StripeCount; i++) {
array[i].value.unlock();
}
}
void forceResetAll() {
for (unsigned int i = 0; i < StripeCount; i++) {
array[i].value.forceReset();
}
}
void defineLockOrder() {
for (unsigned int i = 1; i < StripeCount; i++) {
lockdebug_lock_precedes_lock(&array[i-1].value, &array[i].value);
}
}
void precedeLock(const void *newlock) {
// assumes defineLockOrder is also called
lockdebug_lock_precedes_lock(&array[StripeCount-1].value, newlock);
}
void succeedLock(const void *oldlock) {
// assumes defineLockOrder is also called
lockdebug_lock_precedes_lock(oldlock, &array[0].value);
}
const void *getLock(int i) {
if (i < StripeCount) return &array[i].value;
else return nil;
}
};
通過開頭的英文註釋,
// StripedMap is a map of void* -> T, sized appropriately
可以知道, StripedMap 是一個以void *為hash key, T為vaule的hash 表。
hash定位的演算法如下:
static unsigned int indexForPointer(const void *p) { // 該方法以void *作為key 來獲取void *對應在StripedMap 中的位置
uintptr_t addr = reinterpret_cast<uintptr_t>(p);
return ((addr >> 4) ^ (addr >> 9)) % StripeCount; // % StripeCount 防止index越界
}
把地址指標右移4位異或地址指標右移9位,為什麼這麼做,也不用關心。我們只要關心重點是最後的值要取餘StripeCount,來防止index越界就好。
StripedMap的所有T型別資料都被封裝到PaddedT中:
struct PaddedT {
T value alignas(CacheLineSize); // T value 64位元組對齊
};
之所以再次封裝到PaddedT (有填充的T)中,是為了位元組對齊,估計是存取hash值時的效率考慮。
接下來,這些PaddedT被放到陣列array中:
PaddedT array[StripeCount]; // 所有PaddedT struct 型別資料被儲存在array陣列中。iOS 裝置 StripeCount == 64
然後,蘋果為array陣列寫了一些公共的存取資料的方法,主要是呼叫indexForPointer方法,使得外部傳入的物件地址指標直接hash到對應的array節點:
// 取值方法 [p],
T& operator[] (const void *p) {
return array[indexForPointer(p)].value;
}
const T& operator[] (const void *p) const {
return const_cast<StripedMap<T>>(this)[p];
}
接下來是一堆鎖的操作,由於SideTabls是一個全域性的hash表,因此當然必須要帶鎖訪問。StripedMap提供了一些便捷的鎖操作方法:
// Shortcuts for StripedMaps of locks.
void lockAll() {
for (unsigned int i = 0; i < StripeCount; i++) {
array[i].value.lock();
}
}
void unlockAll() {
for (unsigned int i = 0; i < StripeCount; i++) {
array[i].value.unlock();
}
}
void forceResetAll() {
for (unsigned int i = 0; i < StripeCount; i++) {
array[i].value.forceReset();
}
}
void defineLockOrder() {
for (unsigned int i = 1; i < StripeCount; i++) {
lockdebug_lock_precedes_lock(&array[i-1].value, &array[i].value);
}
}
void precedeLock(const void *newlock) {
// assumes defineLockOrder is also called
lockdebug_lock_precedes_lock(&array[StripeCount-1].value, newlock);
}
void succeedLock(const void *oldlock) {
// assumes defineLockOrder is also called
lockdebug_lock_precedes_lock(oldlock, &array[0].value);
}
const void *getLock(int i) {
if (i < StripeCount) return &array[i].value;
else return nil;
}
可以看到,所有的StripedMap鎖操作,最終是呼叫的array[i].value的相關操作。因此,對於模板的抽象資料T型別,必須具備相關的lock操作介面。
因此,要用StripedMap作為模板hash表,對於T型別還是有所要求的。而在SideTables中,T即為SideTable型別,我們稍後會看到SideTable是如何符合StripedMap的資料型別要求的。
分析完了StripedMap, 也就分析完了SideTables這個全域性的大hash表。現在就來繼續分析SideTables中儲存的資料,SideTable吧。
SideTable
SideTable 翻譯過來的意思是“邊桌”,可以放一下小東西。這裡,主要存放了OC物件的引用計數和弱引用相關資訊。定義如下:
struct SideTable {
spinlock_t slock; // 自旋鎖,防止多執行緒訪問衝突
RefcountMap refcnts; // 物件引用計數map
weak_table_t weak_table; // 物件弱引用map
SideTable() {
memset(&weak_table, 0, sizeof(weak_table));
}
~SideTable() {
_objc_fatal("Do not delete SideTable.");
}
// 鎖操作 符合StripedMap對T的定義
void lock() { slock.lock(); }
void unlock() { slock.unlock(); }
void forceReset() { slock.forceReset(); }
// Address-ordered lock discipline for a pair of side tables.
template<HaveOld, HaveNew>
static void lockTwo(SideTable *lock1, SideTable *lock2);
template<HaveOld, HaveNew>
static void unlockTwo(SideTable *lock1, SideTable *lock2);
};
SideTable的定義很清晰,有三個成員:
spinlock_t slock: 自旋鎖,用於上鎖/解鎖 SideTable。RefcountMap refcnts:以DisguisedPtr<objc_object>為key的hash表,用來儲存OC物件的引用計數(僅在未開啟isa優化 或 在isa優化情況下isa_t的引用計數溢位時才會用到)。weak_table_t weak_table: 儲存物件弱引用指標的hash表。是OC weak功能實現的核心資料結構。
除了三個成員外,蘋果為SideTable還寫了構造和解構函式:
// 建構函式
SideTable() {
memset(&weak_table, 0, sizeof(weak_table));
}
//解構函式(看看函式體,蘋果設計的SideTable其實不希望被析構,不然會引起fatal 錯誤)
~SideTable() {
_objc_fatal("Do not delete SideTable.");
}
通過解構函式可以知道,SideTable是不能被析構的。
最後是一堆鎖的操作,用於多執行緒訪問SideTable, 同時,也符合我們上面提到的StripedMap中關於value的lock介面定義:
// 鎖操作 符合StripedMap對T的定義
void lock() { slock.lock(); }
void unlock() { slock.unlock(); }
void forceReset() { slock.forceReset(); }
// Address-ordered lock discipline for a pair of side tables.
template<HaveOld, HaveNew>
static void lockTwo(SideTable *lock1, SideTable *lock2);
template<HaveOld, HaveNew>
static void unlockTwo(SideTable *lock1, SideTable *lock2);
spinlock_t slock
spinlock_t的最終定義實際上是一個uint32_t型別的非公平的自旋鎖。所謂非公平,就是說獲得鎖的順序和申請鎖的順序無關,也就是說,第一個申請鎖的執行緒有可能會是最後一個獲得到該鎖,或者是剛獲得鎖的執行緒會再次立刻獲得到該鎖,造成飢餓等待。 同時,在OC中,_os_unfair_lock_opaque也記錄了獲取它的執行緒資訊,只有獲得該鎖的執行緒才能夠解開這把鎖。
typedef struct os_unfair_lock_s {
uint32_t _os_unfair_lock_opaque;
} os_unfair_lock, *os_unfair_lock_t;
關於自旋鎖的實現,蘋果並未公佈,但是大體上應該是通過操作_os_unfair_lock_opaque 這個uint32_t的值,當大於0時,鎖可用,當等於或小於0時,需要鎖等待。
RefcountMap refcnts
RefcountMap refcnts 用來儲存OC物件的引用計數。它實質上是一個以objc_object為key的hash表,其vaule就是OC物件的引用計數。同時,當OC物件的引用計數變為0時,會自動將相關的資訊從hash表中剔除。RefcountMap的定義如下:
// RefcountMap disguises its pointers because we
// don't want the table to act as a root for `leaks`.
typedef objc::DenseMap<DisguisedPtr<objc_object>,size_t,true> RefcountMap;
實質上是模板型別objc::DenseMap。模板的三個型別引數DisguisedPtr<objc_object>,size_t, true 分別表示DenseMap的hash key型別,value型別,是否需要在value==0的時候自動釋放掉響應的hash節點,這裡是true。
而DenseMap這個模板型別又繼承與另一個Base 模板型別DenseMapBase :
template<typename KeyT, typename ValueT,
bool ZeroValuesArePurgeable = false,
typename KeyInfoT = DenseMapInfo<KeyT> >
class DenseMap
: public DenseMapBase<DenseMap<KeyT, ValueT, ZeroValuesArePurgeable, KeyInfoT>,
KeyT, ValueT, KeyInfoT, ZeroValuesArePurgeable>
關於DenseMap的定義,蘋果寫了一大坨,有些複雜,這裡就不去深究了,有興趣的同學可以自己去看下相關的原始碼部分。
weak_table_t weak_table
重點來了,weak_table_t weak_table 用來儲存OC物件弱引用的相關資訊。我們知道,SideTables一共只有64個節點,而在我們的APP中,一般都會不只有64個物件,因此,多個物件一定會重用同一個SideTable節點,也就是說,一個weak_table會儲存多個物件的弱引用資訊。因此在一個SideTable中,又會通過weak_table作為hash表再次分散儲存每一個物件的弱引用資訊。
weak_table_t的定義如下:
/**
* The global weak references table. Stores object ids as keys,
* and weak_entry_t structs as their values.
*/
struct weak_table_t {
weak_entry_t *weak_entries; // hash陣列,用來儲存弱引用物件的相關資訊weak_entry_t
size_t num_entries; // hash陣列中的元素個數
uintptr_t mask; // hash陣列長度-1,會參與hash計算。(注意,這裡是hash陣列的長度,而不是元素個數。比如,陣列長度可能是64,而元素個數僅存了2個)
uintptr_t max_hash_displacement; // 可能會發生的hash衝突的最大次數,用於判斷是否出現了邏輯錯誤(hash表中的衝突次數絕不會超過改值)
};
weak_table_t是一個典型的hash結構。其中 weak_entry_t *weak_entries是一個動態陣列,用來儲存weak_table_t的資料元素weak_entry_t。
剩下的三個元素將會用於hash表的相關操作。weak_table的hash定位操作如下所示:
static weak_entry_t *
weak_entry_for_referent(weak_table_t *weak_table, objc_object *referent)
{
assert(referent);
weak_entry_t *weak_entries = weak_table->weak_entries;
if (!weak_entries) return nil;
size_t begin = hash_pointer(referent) & weak_table->mask; // 這裡通過 & weak_table->mask的位操作,來確保index不會越界
size_t index = begin;
size_t hash_displacement = 0;
while (weak_table->weak_entries[index].referent != referent) {
index = (index+1) & weak_table->mask;
if (index == begin) bad_weak_table(weak_table->weak_entries); // 觸發bad weak table crash
hash_displacement++;
if (hash_displacement > weak_table->max_hash_displacement) { // 當hash衝突超過了可能的max hash 衝突時,說明元素沒有在hash表中,返回nil
return nil;
}
}
return &weak_table->weak_entries[index];
}
上面的定位操作還是比較清晰的,首先通過
size_t begin = hash_pointer(referent) & weak_table->mask;
來嘗試確定hash的初始位置。注意,這裡做了& weak_table->mask 位操作來確保index不會越界,這同我們平時用到的取餘%操作是一樣的功能。只不過這裡改用了位操作,提升了效率。
然後,就開始對比hash表中的資料是否與目標資料相等while (weak_table->weak_entries[index].referent != referent),如果不相等,則index +1, 直到index == begin(繞了一圈)或超過了可能的hash衝突最大值。
這是weak_table_t如何進行hash定位的相關操作。
關於weak_table_t中如何新增/刪除元素,我們在上一章Objective-C runtime機制(6)——weak引用的底層實現原理中已有分析,在這裡我們不再展開。
weak_entry_t
weak_table_t中儲存的元素是weak_entry_t型別,每個weak_entry_t型別對應了一個OC物件的弱引用資訊。
weak_entry_t的結構和weak_table_t很像,同樣也是一個hash表,其儲存的元素是weak_referrer_t,實質上是弱引用該物件的指標的指標,即 objc_object **new_referrer , 通過操作指標的指標,就可以使得weak 引用的指標在物件析構後,指向nil。
// The address of a __weak variable.
// These pointers are stored disguised so memory analysis tools
// don't see lots of interior pointers from the weak table into objects.
typedef DisguisedPtr<objc_object *> weak_referrer_t;
weak_entry_t 的定義如下:
/**
* The internal structure stored in the weak references table.
* It maintains and stores
* a hash set of weak references pointing to an object.
* If out_of_line_ness != REFERRERS_OUT_OF_LINE then the set
* is instead a small inline array.
*/
#define WEAK_INLINE_COUNT 4
// out_of_line_ness field overlaps with the low two bits of inline_referrers[1].
// inline_referrers[1] is a DisguisedPtr of a pointer-aligned address.
// The low two bits of a pointer-aligned DisguisedPtr will always be 0b00
// (disguised nil or 0x80..00) or 0b11 (any other address).
// Therefore out_of_line_ness == 0b10 is used to mark the out-of-line state.
#define REFERRERS_OUT_OF_LINE 2
struct weak_entry_t {
DisguisedPtr<objc_object> referent; // 被弱引用的物件
// 引用該物件的物件列表,聯合。 引用個數小於4,用inline_referrers陣列。 用個數大於4,用動態陣列weak_referrer_t *referrers
union {
struct {
weak_referrer_t *referrers; // 弱引用該物件的物件指標地址的hash陣列
uintptr_t out_of_line_ness : 2; // 是否使用動態hash陣列標記位
uintptr_t num_refs : PTR_MINUS_2; // hash陣列中的元素個數
uintptr_t mask; // hash陣列長度-1,會參與hash計算。(注意,這裡是hash陣列的長度,而不是元素個數。比如,陣列長度可能是64,而元素個數僅存了2個)素個數)。
uintptr_t max_hash_displacement; // 可能會發生的hash衝突的最大次數,用於判斷是否出現了邏輯錯誤(hash表中的衝突次數絕不會超過改值)
};
struct {
// out_of_line_ness field is low bits of inline_referrers[1]
weak_referrer_t inline_referrers[WEAK_INLINE_COUNT];
};
};
bool out_of_line() {
return (out_of_line_ness == REFERRERS_OUT_OF_LINE);
}
weak_entry_t& operator=(const weak_entry_t& other) {
memcpy(this, &other, sizeof(other));
return *this;
}
weak_entry_t(objc_object *newReferent, objc_object **newReferrer)
: referent(newReferent) // 構造方法,裡面初始化了靜態陣列
{
inline_referrers[0] = newReferrer;
for (int i = 1; i < WEAK_INLINE_COUNT; i++) {
inline_referrers[i] = nil;
}
}
};
weak_entry_t的結構也比較清晰:
DisguisedPtr<objc_object> referent:弱引用物件指標摘要。其實可以理解為弱引用物件的指標,只不過這裡使用了摘要的形式儲存。(所謂摘要,其實是把地址取負)。union:接下來是一個聯合,union有兩種形式:定長陣列weak_referrer_t inline_referrers[WEAK_INLINE_COUNT]和動態陣列 weak_referrer_t *referrers。這兩個陣列是用來儲存弱引用該物件的指標的指標的,同樣也使用了指標摘要的形式儲存。當弱引用該物件的指標數目小於等於WEAK_INLINE_COUNT時,使用定長陣列。當超過WEAK_INLINE_COUNT時,會將定長陣列中的元素轉移到動態陣列中,並之後都是用動態陣列儲存。關於定長陣列/動態陣列 切換這部分,我們在稍後詳細分析。bool out_of_line(): 該方法用來判斷當前的weak_entry_t是使用的定長陣列還是動態陣列。當返回true,此時使用的動態陣列,當返回false,使用靜態陣列。weak_entry_t& operator=(const weak_entry_t& other):賦值方法weak_entry_t(objc_object *newReferent, objc_object **newReferrer):構造方法。
定長陣列 / 動態陣列
weak_entry_t會儲存所有弱引用該物件的指標的指標。儲存型別為weak_referrer_t ,其實就是弱引用指標的指標。但是是以指標摘要的形式儲存的:
typedef DisguisedPtr<objc_object *> weak_referrer_t;
weak_entry_t會將weak_referrer_t儲存到hash陣列中,而這個hash陣列會有兩種形態:定長陣列/動態陣列:
union {
// 動態陣列模式
struct {
weak_referrer_t *referrers; // 弱引用該物件的物件指標地址的hash陣列
uintptr_t out_of_line_ness : 2; // 是否使用動態hash陣列標記位
uintptr_t num_refs : PTR_MINUS_2; // hash陣列中的元素個數
uintptr_t mask; // hash陣列長度-1,會參與hash計算。(注意,這裡是hash陣列的長度,而不是元素個數。比如,陣列長度可能是64,而元素個數僅存了2個)素個數)。
uintptr_t max_hash_displacement; // 可能會發生的hash衝突的最大次數,用於判斷是否出現了邏輯錯誤(hash表中的衝突次數絕不會超過改值)
};
// 定長陣列模式
struct {
// out_of_line_ness field is low bits of inline_referrers[1]
weak_referrer_t inline_referrers[WEAK_INLINE_COUNT];
};
};
bool out_of_line() {
return (out_of_line_ness == REFERRERS_OUT_OF_LINE);
}
當弱引用指標個數少於等於WEAK_INLINE_COUNT時,會使用定長陣列inline_referrers。而當大於WEAK_INLINE_COUNT時,則會轉換到動態陣列模式 weak_referrer_t *referrers。
之所以做定長/動態陣列的切換,應該是蘋果考慮到弱引用的指標個數一般不會超過WEAK_INLINE_COUNT個。這時候使用定長陣列,不需要動態的申請記憶體空間,而是一次分配一塊連續的記憶體空間。這會得到執行效率上的提升。
至於weak_entry_t 是使用的定長/動態陣列,蘋果提供了方法:
#define REFERRERS_OUT_OF_LINE 2
bool out_of_line() {
return (out_of_line_ness == REFERRERS_OUT_OF_LINE);
}
該方法的實質是測試定長陣列第二個元素值的2進位制位第2位是否等於01。因為根據蘋果的註釋,inline_referrers[1] 中儲存的是pointer-aligned DisguisedPtr ,即指標對齊的指標摘要,其最低位一定是0b00或0b11,因此可以用0b10 表示使用了動態陣列。
下面我就來看一下weak_entry_t 中是如何插入元素的:
/**
* Add the given referrer to set of weak pointers in this entry.
* Does not perform duplicate checking (b/c weak pointers are never
* added to a set twice).
*
* @param entry The entry holding the set of weak pointers.
* @param new_referrer The new weak pointer to be added.
*/
static void append_referrer(weak_entry_t *entry, objc_object **new_referrer)
{
if (! entry->out_of_line()) { // 如果weak_entry 尚未使用動態陣列,走這裡
// Try to insert inline.
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
if (entry->inline_referrers[i] == nil) {
entry->inline_referrers[i] = new_referrer;
return;
}
}
// 如果inline_referrers的位置已經存滿了,則要轉型為referrers,做動態陣列。
// Couldn't insert inline. Allocate out of line.
weak_referrer_t *new_referrers = (weak_referrer_t *)
calloc(WEAK_INLINE_COUNT, sizeof(weak_referrer_t));
// This constructed table is invalid, but grow_refs_and_insert
// will fix it and rehash it.
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
new_referrers[i] = entry->inline_referrers[i];
}
entry->referrers = new_referrers;
entry->num_refs = WEAK_INLINE_COUNT;
entry->out_of_line_ness = REFERRERS_OUT_OF_LINE;
entry->mask = WEAK_INLINE_COUNT-1;
entry->max_hash_displacement = 0;
}
// 對於動態陣列的附加處理:
assert(entry->out_of_line()); // 斷言: 此時一定使用的動態陣列
if (entry->num_refs >= TABLE_SIZE(entry) * 3/4) { // 如果動態陣列中元素個數大於或等於陣列位置總空間的3/4,則擴充套件陣列空間為當前長度的一倍
return grow_refs_and_insert(entry, new_referrer); // 擴容,並插入
}
// 如果不需要擴容,直接插入到weak_entry中
// 注意,weak_entry是一個雜湊表,key:w_hash_pointer(new_referrer) value: new_referrer
// 細心的人可能注意到了,這裡weak_entry_t 的hash演算法和 weak_table_t的hash演算法是一樣的,同時擴容/減容的演算法也是一樣的
size_t begin = w_hash_pointer(new_referrer) & (entry->mask); // '& (entry->mask)' 確保了 begin的位置只能大於或等於 陣列的長度
size_t index = begin; // 初始的hash index
size_t hash_displacement = 0; // 用於記錄hash衝突的次數,也就是hash再位移的次數
while (entry->referrers[index] != nil) {
hash_displacement++;
index = (index+1) & entry->mask; // index + 1, 移到下一個位置,再試一次能否插入。(這裡要考慮到entry->mask取值,一定是:0x111, 0x1111, 0x11111, ... ,因為陣列每次都是*2增長,即8, 16, 32,對應動態陣列空間長度-1的mask,也就是前面的取值。)
if (index == begin) bad_weak_table(entry); // index == begin 意味著陣列繞了一圈都沒有找到合適位置,這時候一定是出了什麼問題。
}
if (hash_displacement > entry->max_hash_displacement) { // 記錄最大的hash衝突次數, max_hash_displacement意味著: 我們嘗試至多max_hash_displacement次,肯定能夠找到object對應的hash位置
entry->max_hash_displacement = hash_displacement;
}
// 將ref存入hash陣列,同時,更新元素個數num_refs
weak_referrer_t &ref = entry->referrers[index];
ref = new_referrer;
entry->num_refs++;
}
程式碼可以分成兩部分理解,一部分是使用定長陣列的情況:
if (! entry->out_of_line()) { // 如果weak_entry 尚未使用動態陣列,走這裡
// Try to insert inline.
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
if (entry->inline_referrers[i] == nil) {
entry->inline_referrers[i] = new_referrer;
return;
}
}
// 如果inline_referrers的位置已經存滿了,則要轉型為referrers,做動態陣列。
// Couldn't insert inline. Allocate out of line.
weak_referrer_t *new_referrers = (weak_referrer_t *)
calloc(WEAK_INLINE_COUNT, sizeof(weak_referrer_t));
// This constructed table is invalid, but grow_refs_and_insert
// will fix it and rehash it.
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
new_referrers[i] = entry->inline_referrers[i];
}
entry->referrers = new_referrers;
entry->num_refs = WEAK_INLINE_COUNT;
entry->out_of_line_ness = REFERRERS_OUT_OF_LINE;
entry->mask = WEAK_INLINE_COUNT-1;
entry->max_hash_displacement = 0;
}
定長陣列的邏輯很簡單,直接安裝陣列順序,將new_referrer插入即可。如果定長陣列已經用盡,則將定長陣列轉型為動態陣列:
weak_referrer_t *new_referrers = (weak_referrer_t *)
calloc(WEAK_INLINE_COUNT, sizeof(weak_referrer_t));
...
entry->referrers = new_referrers; // hash陣列由 entry->inline_referrers轉換為 entry->referrers
要注意,定長陣列轉換為動態陣列後,新的元素並沒有插入到陣列中,而僅是將原來定長陣列中的內容轉移到了動態陣列中。新元素的插入邏輯,在下面動態陣列部分:
...
// 對於動態陣列的附加處理:
assert(entry->out_of_line()); // 斷言: 此時一定使用的動態陣列
if (entry->num_refs >= TABLE_SIZE(entry) * 3/4) { // 如果動態陣列中元素個數大於或等於陣列位置總空間的3/4,則擴充套件陣列空間為當前長度的一倍
return grow_refs_and_insert(entry, new_referrer); // 擴容,並插入
}
// 如果不需要擴容,直接插入到weak_entry中
// 注意,weak_entry是一個雜湊表,key:w_hash_pointer(new_referrer) value: new_referrer
// 細心的人可能注意到了,這裡weak_entry_t 的hash演算法和 weak_table_t的hash演算法是一樣的,同時擴容/減容的演算法也是一樣的
size_t begin = w_hash_pointer(new_referrer) & (entry->mask); // '& (entry->mask)' 確保了 begin的位置只能大於或等於 陣列的長度
size_t index = begin; // 初始的hash index
size_t hash_displacement = 0; // 用於記錄hash衝突的次數,也就是hash再位移的次數
while (entry->referrers[index] != nil) {
hash_displacement++;
index = (index+1) & entry->mask; // index + 1, 移到下一個位置,再試一次能否插入。(這裡要考慮到entry->mask取值,一定是:0x111, 0x1111, 0x11111, ... ,因為陣列每次都是*2增長,即8, 16, 32,對應動態陣列空間長度-1的mask,也就是前面的取值。)
if (index == begin) bad_weak_table(entry); // index == begin 意味著陣列繞了一圈都沒有找到合適位置,這時候一定是出了什麼問題。
}
if (hash_displacement > entry->max_hash_displacement) { // 記錄最大的hash衝突次數, max_hash_displacement意味著: 我們嘗試至多max_hash_displacement次,肯定能夠找到object對應的hash位置
entry->max_hash_displacement = hash_displacement;
}
// 將ref存入hash陣列,同時,更新元素個數num_refs
weak_referrer_t &ref = entry->referrers[index];
ref = new_referrer;
entry->num_refs++;
}
其實這部分的邏輯和weak_table_t中插入weak_entry_t是非常類似的。都使用了mask取餘來解決hash衝突。
我們可以再細看一下動態陣列是如何動態擴容的:
if (entry->num_refs >= TABLE_SIZE(entry) * 3/4) { // 如果動態陣列中元素個數大於或等於陣列位置總空間的3/4,則擴充套件陣列空間為當前長度的一倍
return grow_refs_and_insert(entry, new_referrer); // 擴容,並插入
}
/**
* Grow the entry's hash table of referrers. Rehashes each
* of the referrers.
*
* @param entry Weak pointer hash set for a particular object.
*/
__attribute__((noinline, used))
static void grow_refs_and_insert(weak_entry_t *entry,
objc_object **new_referrer)
{
assert(entry->out_of_line());
size_t old_size = TABLE_SIZE(entry);
size_t new_size = old_size ? old_size * 2 : 8; // 每次擴容為上一次容量的2倍
size_t num_refs = entry->num_refs;
weak_referrer_t *old_refs = entry->referrers;
entry->mask = new_size - 1;
entry->referrers = (weak_referrer_t *)
calloc(TABLE_SIZE(entry), sizeof(weak_referrer_t));
entry->num_refs = 0;
entry->max_hash_displacement = 0;
// 這裡可以看到,舊的資料需要依次轉移到新的記憶體中
for (size_t i = 0; i < old_size && num_refs > 0; i++) {
if (old_refs[i] != nil) {
append_referrer(entry, old_refs[i]); // 將舊的資料轉移到新的動態陣列中
num_refs--;
}
}
// Insert
append_referrer(entry, new_referrer);
if (old_refs) free(old_refs); // 釋放舊的記憶體
}
通過程式碼可以看出,每一次動態陣列的擴容,都需要將舊的資料重新插入到新的陣列中。
總結
OK,上面就是在runtime中,關於物件引用計數和weak引用相關的資料結構。搞清楚了它們之間的關係以及各自的實現細節,相信大家會對runtime有更深的理解。