
Spark Executor記憶體管理
堆內和堆外記憶體規劃
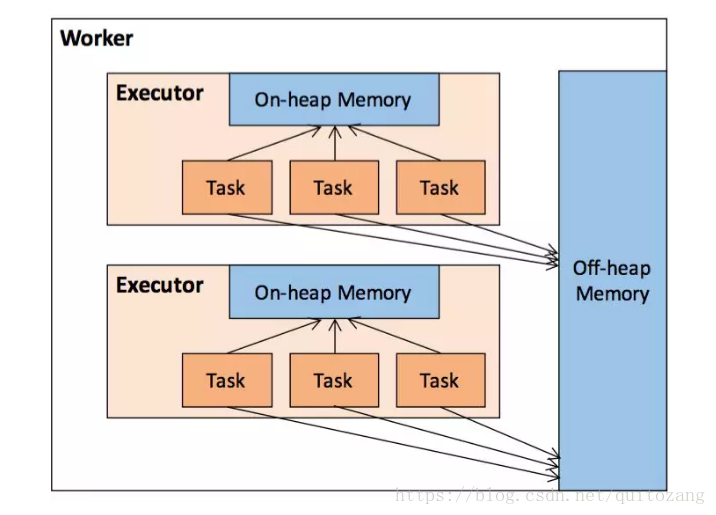
1.堆內記憶體:由-executor-memory配置,executor內所有併發任務共享
序列化:將物件轉換為二進位制位元組流,本質上可以理解為將非連續空間的鏈式儲存轉化為連續空間或塊儲存
2.堆外記憶體:由spark.memory.offHeap.size配置,優化記憶體的使用,提高shuffle時排序效率,儲存經過序列化的二進位制資料,預設關閉
3.記憶體管理介面:MemoryManager(靜態記憶體管理(1.6)—>統一記憶體管理)
記憶體空間分配
1.靜態記憶體管理

storage:快取RDD資料和broadcast資料
可用儲存記憶體 = systemMaxMemory * spark.storage.memoryFraction * spark.storage.safety
execution:快取shuffle過程中中間資料
可用執行記憶體 = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safety
other:使用者程式碼執行區域

2.統一記憶體管理
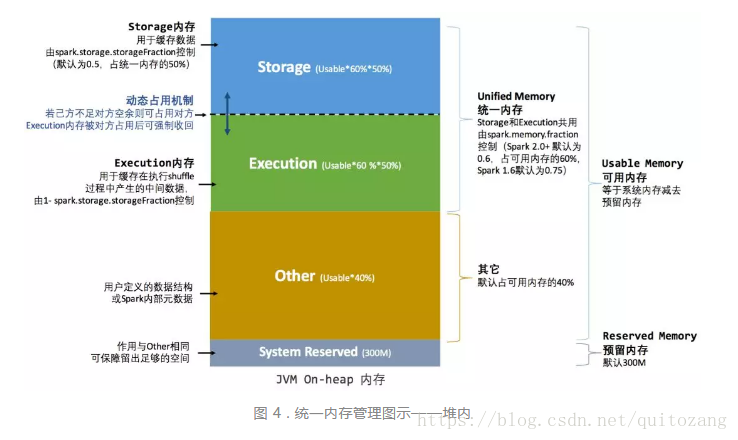

Storage和Execution共享同一塊空間,動態佔用對方空閒區域
規則:
- storage和execution大小由spark.storage.storageFraction配置(0.6)
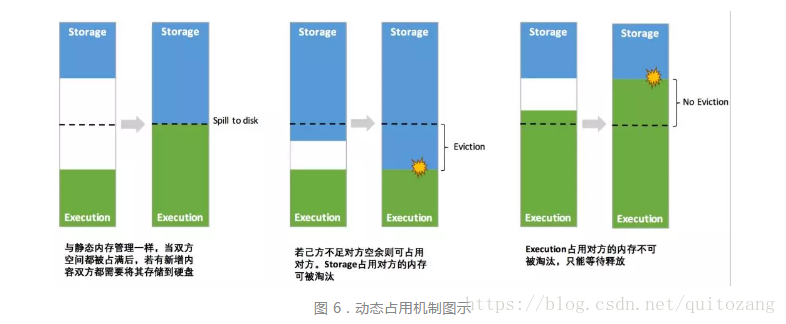
- 雙方空間都不足,儲存到磁碟;有一方空餘,借用對方空間
- execution被對方佔用,可讓對方歸還空間,將該部分轉存到硬碟
- storage被佔用,無法歸還,shuffle過程較為複雜
儲存記憶體管理
1.RDD的持久化機制
RDD:spark最基本的資料抽象,是隻讀的分割槽記錄的集合—從穩定物理儲存的資料集建立或已有的RDD轉換。
RDD之間的轉換會形成依賴關係,構成血統(Lineage),保證每個RDD可被恢復。
task啟動之初讀取某一分割槽,先判斷是否持久化,無則檢查checkpoint或按lineage重新計算。
持久化:persist或cache,cache預設為MEMORY_ONLY,由storage模組負責
checkpoint:持久化不能保證資料完全不丟失,可以將DAG中重要的資料儲存到高可用的地方(HDFS)
2.RDD快取的過程
RDD在快取到storage記憶體之前,通過iterator獲取分割槽中的資料項(record),record邏輯上佔用JVM堆內記憶體的other空間,同一 partition的不同record空間不連續
RDD快取到storage,partition轉block,儲存空間連續,該過程稱為“展開”(unroll)

3.淘汰和落盤
新的block需要快取到storage,但空間不足,對LinkedHashMap中舊block進行淘汰(Eviction)
淘汰的block如果可以儲存到磁碟,則進行落盤(drop),否則刪除
淘汰規則:
- 被淘汰的舊block要與新block的memorymode相同,同屬於堆內或堆外記憶體
- 新舊block不屬於同一個RDD
- 舊block所屬RDD不處於被讀狀態,避免一致性問題
- 遍歷LinkedHashMap中block,採用最近最少使用(LRU)順序淘汰