
MapReduce內部shuffle過程詳解(Combiner的使用)
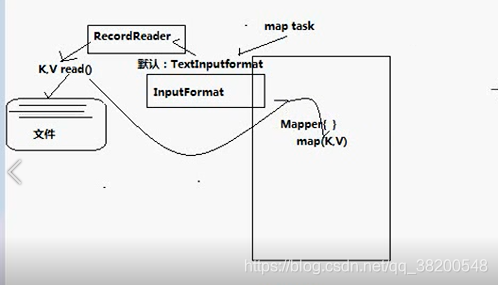
Maptask呼叫一個元件FileInputFormat
FileInputFormat有一個最高層的介面 --> InputFormat
我們不需要去寫自己的實現類,使用的就是內部預設的元件:TextInputFormat
maptask先呼叫TextInputFormat, 但是實質讀資料是TextInputFormat呼叫RecordReader。 RecordReader 是一個介面,這個介面的實現類呼叫read方法去讀取資料。
InputFormat和RecordReader:
org.apache.hadoop.mapreduce包裡的InputFormat抽象類提供瞭如下列程式碼所示的兩個方法:
public abstract class InputFormat<K, V> {
public abstract List<InputSplit> getSplits(JobContext context);
RecordReader<K, V> createRecordReader(InputSplit split, TaskAttemptContext context);
}
這兩個方法展示了InputFormat類的兩個功能:
- 將輸入檔案切分為map處理所需的split
- 建立RecordReader類,它將從一個split生成鍵值對序列
RecordReader類同樣也是org.apache.hadoop.mapreduce包裡的抽象類
public abstract class RecordReader<KEYIN, VALUEIN> implements Closeable { /* * 初始化RecordReader,只能被呼叫一次。 */ public abstract void initialize(InputSplit split, TaskAttemptContext context ) throws IOException, InterruptedException; /** * 獲取下一個資料的鍵值對 */ public abstract boolean nextKeyValue() throws IOException, InterruptedException; /** * 獲取當前資料的 key */ public abstract KEYIN getCurrentKey() throws IOException, InterruptedException; /** * 獲取當前資料的value */ public abstract VALUEIN getCurrentValue() throws IOException, InterruptedException; /** * 進度 */ public abstract float getProgress() throws IOException, InterruptedException; /** * 關閉RecordReader */ public abstract void close() throws IOException; }
組合使用InputFormat和RecordReader可以將任何型別的輸入資料轉換為MapReduce所需的鍵值對。
下面有一篇文章可以參考:
https://www.cnblogs.com/xuepei/p/3664698.html
InputFormat:
通過使用InputFormat,MapReduce框架可以做到:
-
1、驗證作業的輸入的正確性
-
2、將輸入檔案切分成邏輯的InputSplits,一個InputSplit將被分配給一個單獨的Mapper task
-
3、提供RecordReader的實現,這個RecordReader會從InputSplit中正確讀出一條一條的K-V對供Mapper使用。
maptask會將返回的 key - value 交給自定義的Mapper。如果沒有自定義的Mapper就是使用預設的Mapper。這個預設的Mapper的map處理方法,就是進來什麼就輸出什麼。
map方法的引數有 key - value ,所以maptask會將InputFormat返回的key - value交給Mapper的map方法去使用。
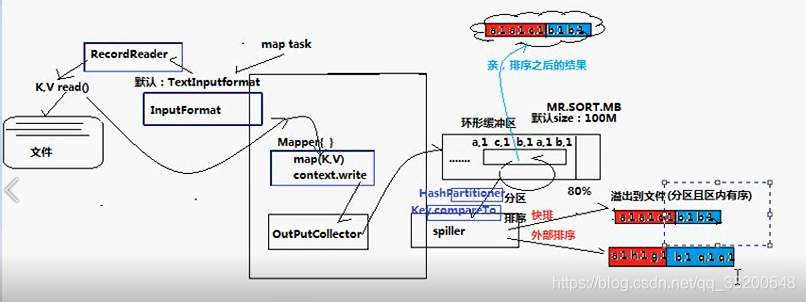
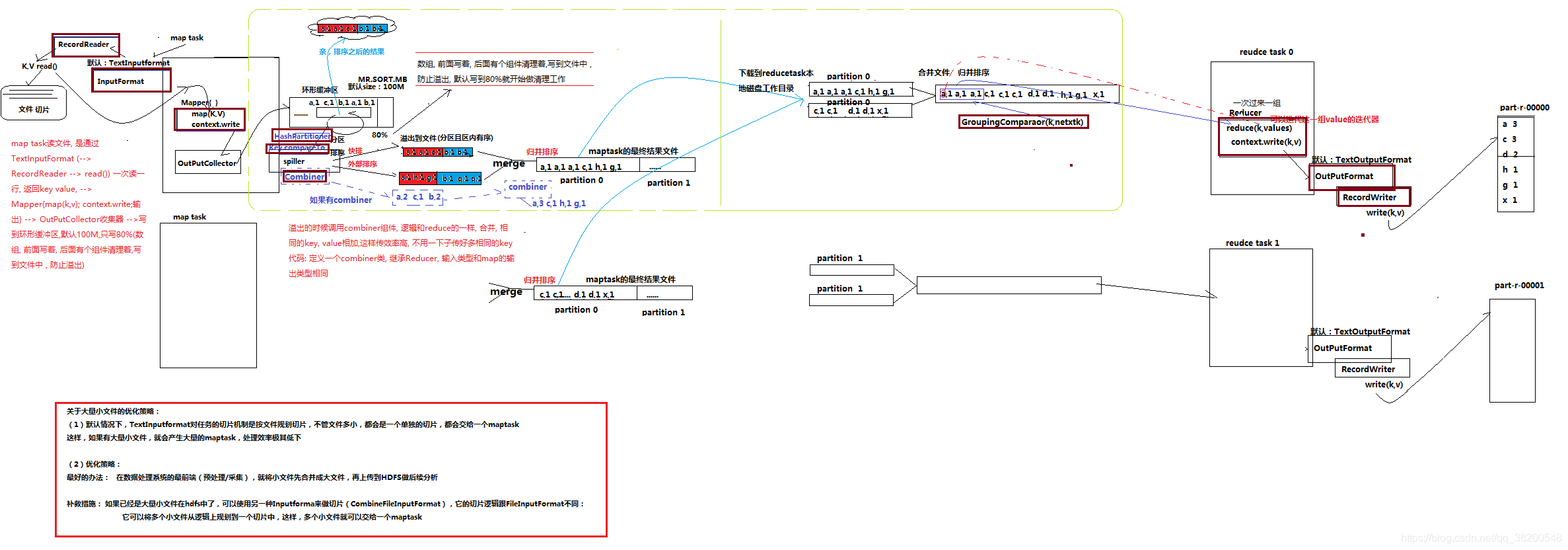
內部還有一個元件 OutputCollector:
OutputCollector 由hadoop框架提供,複製收集Mapper和Reducer的輸出資料,實現map或者reduce函式時,只需要簡單地將其輸出的<key,value>對往OutputCollector中一丟即可,剩餘的框架會幫你做好。
這個收集器會將資料輸出到一個環形緩衝區,其實就是一個數組,(一邊寫資料,一邊會對資料進行回收,通過索引來控制,相當於一個環一樣)
環形緩衝區其實就是一個數組,後端不斷接收資料的同時,前端資料不斷溢位,長度用完之後讀取的新資料再從前端開始覆蓋。這個緩衝區的預設大小是100M – 這個環形緩衝區是記憶體裡面的,速度很快,但是容量有限。-- 這個100M是不會全部被使用的,因為還需要記憶體進行排序等操作。 這裡面有一個保留區
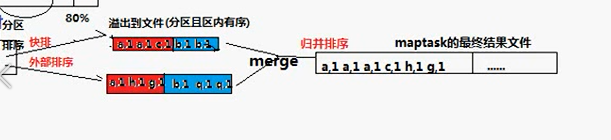
操作80%就會溢位
spiller元件會從環形緩衝區溢位檔案,這過程會按照定義的partitioner分割槽(預設是hashpartition),並且按照key.compareTo()進行排序(底層主要是快排和外部排序)
spiller會在環形緩衝區溢位的時候,對資料進行分割槽和排序, – (spiller會會環形緩衝區這段記憶體進行操作)
分割槽是根據key,這個分割槽需要呼叫一個元件 Partitioner - 預設的實現是 HashPartitioner.
排序的時候需要呼叫被排序物件的compareTo()方法。
這個過程就是將資料分好區,每個區都是排好序的。
分割槽排序之後,就可以將檔案往外寫。一個區一個區往外寫。 記憶體中的資料寫到檔案中。這個檔案就在maptask的工作目錄裡面。就在本地。
每一次溢位就會產生一個檔案。
如果記憶體裡面還剩下最後的一點點資料,那也需要溢位。
這些溢位的檔案不會一個一個地交給reduce去處理,還會先進行一次合併。合併完之後會形成一個大檔案。這個merge使用的是歸併排序。
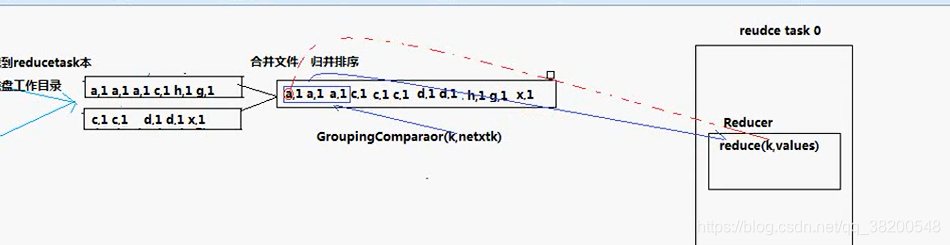
merge之後就會將資料全部交給reduce來進行處理:
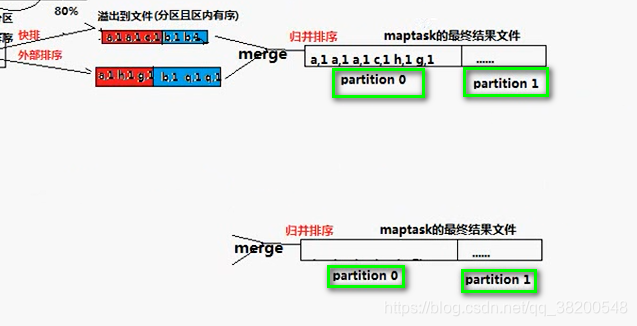
reduce task會去下載資料(通過網路從傳輸)
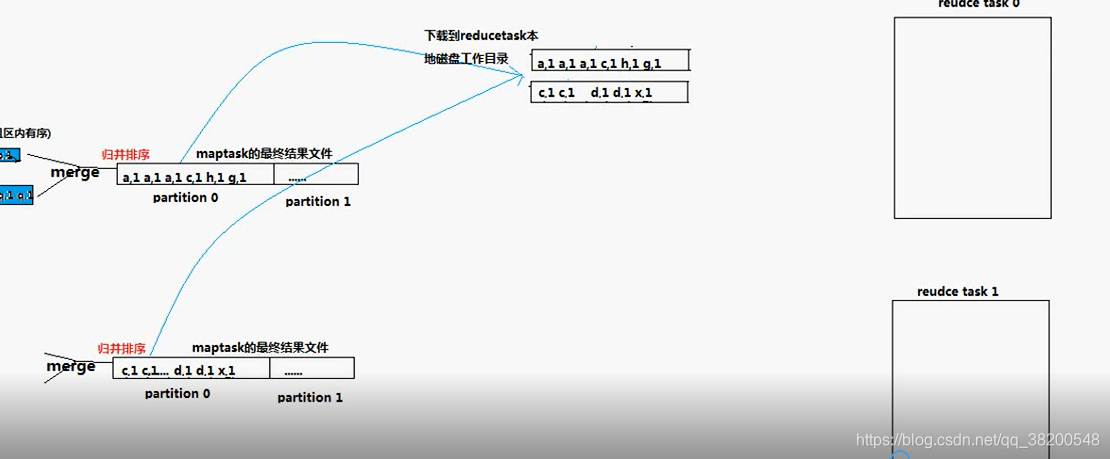
reduce task 從 map task 機器上下載下來的資料是沒有排序的,還需要進行再一次地合併。
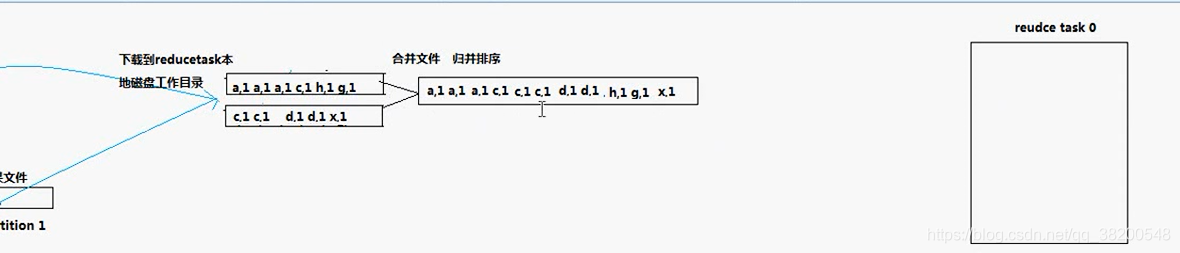
問題: reduce task 拿到這個檔案是怎麼處理的?
reducer 的 reduce方法是處理業務邏輯的,會根據key來處理,相同的key就呼叫一次reduce() 方法。呼叫 GroupingComparator()方法
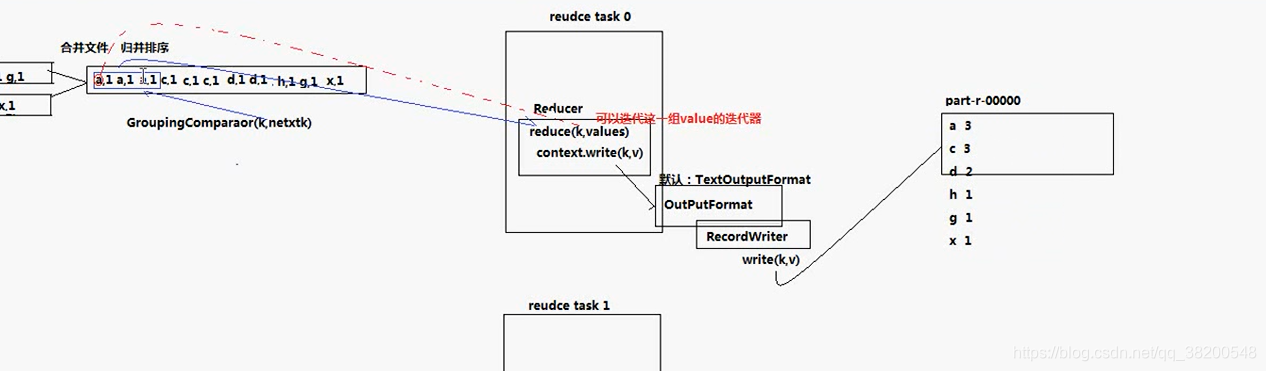
完整的圖:
Combainer
Hadoop礦建使用Mapper將資料處理成一個個<key,value>鍵值對,在網路節點間對其進行整理(shuffle),然後使用Reduce處理資料並進行最後的輸出。
這時會出現效能上的瓶頸:
(1)如果我們有10億個資料,Mapper會產生10億個鍵值對在網路間進行傳輸,但是如果我們對資料求最大值,那麼很明顯的Mapper值需要輸出它所知道的最大值即可。這樣不僅可以減少輕網路壓力,同樣也可以大幅度提高程式效率。
總結:網路頻寬嚴重被佔降低效率。
(2)有時候資料遠遠不是一致性的或者說是平衡分佈的,這樣不僅Mapper中的鍵值對,中間階段(shuffle)的鍵值對等,大多數的鍵值對最終會聚集於單一的Reducer上,壓倒這個Reducer,從而大大降低程式的效能。
總結:單一節點承載過重降低程式效能。
在MapperReducer程式設計模型中,在Mapper和Reducer之間有一個非常重要的元件,它解決了上述的效能瓶頸問題,它就是Combiner.
注意點:
(1)與mapper和reducer不同的是,combiner沒有預設的實現,需要顯式設定早conf中才有作用,
(2)並不是所有的job都適用combiner,只有操作滿足結合律的才可設定combiner。combine操作類似於:
opt(opt(1, 2, 3), opt(4, 5, 6))。如果opt為求和、求最大值的話,可以使用,但是如果是求中值的話,不適用。
每一個mapper都可能產生大量的本地輸出,Combiner額作用就是對map端的輸出先做一次合併,減少在map和reduce節點之間的資料傳輸,以提高網路IO效能,是MapReduce的一種優化手段之一,其具體作用如下所述:
自定義的Combiner其實就是跟Reducer一樣的程式碼:
package com.thp.bigdata.wcdemo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* 自定義的Combiner
* @author tommy
*
*/
public class MyCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
//
System.out.println("Combiner輸入分組<" + key.toString() + ",N(N>=1)>");
int count = 0;
for(IntWritable value : values) {
count += value.get(); // 這個count 最後就是某一個單詞的彙總的值
// 顯示次數表示輸入的k2,v2的鍵值對數量
System.out.println("Combiner輸入鍵值對<" + key.toString() + "," + value.get() + ">");
}
context.write(key, new IntWritable(count));
System.out.println("Combiner輸出鍵值對<" + key.toString() + "," + count+ ">");
}
}
還需要將這個自定義的Combiner新增進去:
// 設定Map規約Combiner
job.setCombinerClass(MyCombiner.class);
我每一個檔案中就有8個hello,這個8個hello如果使用了combiner會先進行一次合併:
沒使用之前:
Reducer輸入分組<hello,N(N>=1)>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
Reducer輸入鍵值對<hello,1>
reduce會有56次輸入,但是如果使用了combiner的話,每一次map之後,就會進行換一次合併:
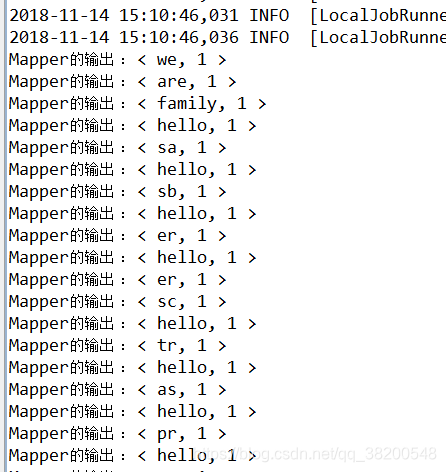
接下來會有一個combiner進行一次合併:
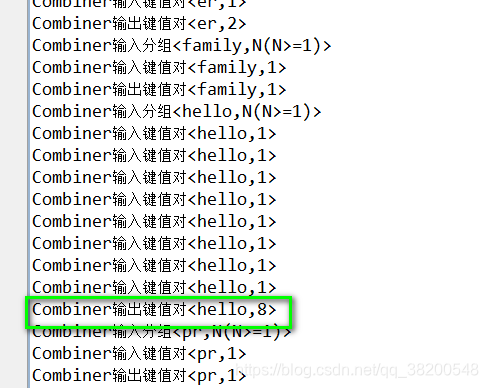
第一個檔案中的8個hello就進行了一次合併:
每一個檔案都會有這個combiner的過程,最後會有reduce的過程進行彙總:
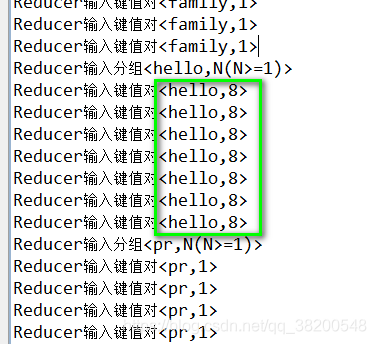
這個reduce過程對hello進行統計只有7次輸入,每一次輸入的資料都是8次,是combiner先進行了一次合併。
總結:
從控制檯的資訊我們可以發現,其實combiner只是把相同的hello進行規約,由此輸入給reduce的就變成<hello,8>。在實際的Hadoop叢集操作中,我們是由多臺主機一起進行MapReduce的,如果加入規約操作,每一臺主機在reduce之前先進行一次對本機資料的規約,然後再通過叢集進行reduce操作,這樣就大大節省reduce時間,從而加快了MapReduce的處理速度。
但是:特別值得注意的一點是,一個combiner只是處理一個節點中的輸出,而不能享受向reduce一樣的輸入(經過了shuffle階段的資料),這點非常關鍵
combiner:
前面展示的流水線忽略了一個可以優化MapReduce作業所使用的頻寬的步驟,這個過程叫Combiner,它在Mapper之後,Reducer之前執行。combienr是可選的,如果這個過程適合於你的作業,Combiner例項會在每一個執行map任務的節點上執行。Combiner會接收特定節點上的Mapper例項的輸出作為輸入,接著Combiner的輸出會被送到Reducer那裡,而不是傳送Mapper的輸出。Combiner是一個“迷你reduce過程”,他只處理單臺機器生成的資料。
參考別的大神的部落格:
https://blog.csdn.net/guoery/article/details/8529004