
python資料分析新手入門課程學習——(二)探索分析與視覺化(來源:慕課網)
一,單因子與對比分析視覺化
資料
import pandas as pd
df = pd.read_csv('./HR.csv')
#檢視前十條資料
df.head(10) 以下為顯示的結果
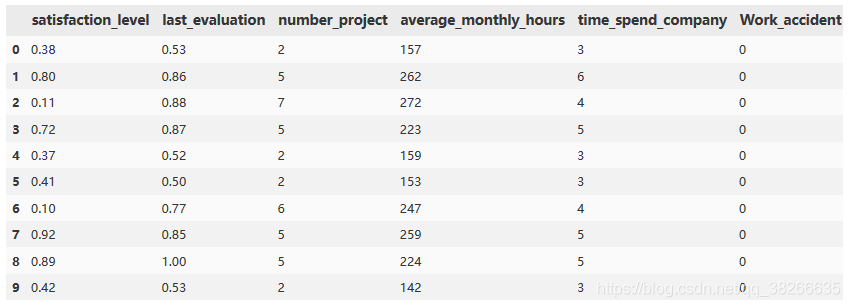
我們可以看出:
第一個屬性satisfaction_level(滿意度)的取值應該是在0-1之間;
last_evaluation(最近一次的評價)也是在0-1之間;
number_project(每個員工做的專案數);
average_monthly_hours(平均每個月的工作時長),這裡取整了;
time_spend_company(在公司呆了多長時間),單位是年;
Work_accident(是否有工作事故),0表示沒有,1表示有;
左(最近是否離職),1表示離職,0表示沒有離職;
promotion_last_5years(最近五年是否晉升),1表示晉升,0表示沒有晉升;
部門(每個員工所在的部門);
工資(工資),分三等級:低,中,高。
2.理論鋪墊
(1)集中趨勢:資料聚攏程度的一種衡量,表示資料聚攏在哪個位置。
++ 均值:經常用來衡量一些分佈比較規律的連續值的集中趨勢。
++
++ 眾數:用在離散值的集中趨勢衡量。
++ 分位數:跟其他幾個值共同作用,產生不錯的效果常用的是四分位數。
(補)四分位數計算:

(2)離中趨勢:資料離散程度的衡量
++ 標準差(如下),方差(標準差的平方):越大表示資料越離散,越小表示資料越聚。
注:關於正態分佈的離中趨勢的一個重要概念 - 對於正態分佈的資料來說,資料落在-1倍標準差和+1倍標準差內的概率為69%,落在-1.96倍標準差和1.96倍標準差內的概率為95%,落在-2.58倍標準差和2.58倍標準差內的概率為99%,也就是這部分面積可以達到99%。
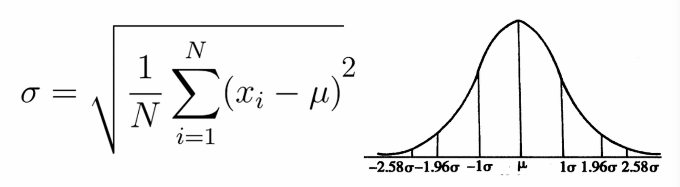
(3)資料分佈:偏態與峰度
++偏態係數S: 。資料平均值偏離狀態的一種衡量中位數與均值相差得多,就說這是有偏態的,分佈值為正,正偏,它的均值比較大;負值,負偏,它的均值較小。
++峰態係數K: 資料分佈集中強度的衡量值越大,頂越尖;值越小,分佈越平緩正態分佈的峰態係數一般是3,經常有演算法將這個值直接減3再把正態分佈的峰值係數定為0也是可以的。如果有個分佈峰態係數<3或> 5,則此分佈不是正態分佈。
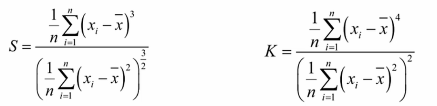
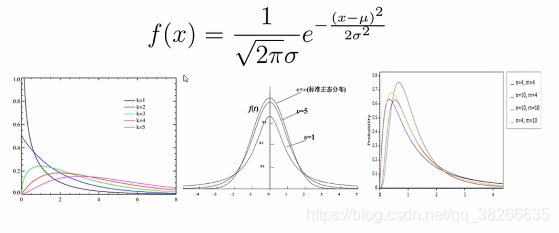
++正態分佈(公式如下)與三大分佈(卡方分佈,T分佈和F分佈):其應用詳見下節。
卡方分佈(χ2分佈):幾個標準正態分佈(均值為0,方差為1)的平方和滿足於分佈,這個分佈就是卡方分佈。
T分佈:正態分佈的一個隨機變數除以一個服從卡方分佈的變數,就是噸分佈經常用來根據小樣本來估計呈正態分佈且方差未知的總體的均值。
F分佈:是由構成兩個服從卡方分佈的隨機變數的比構成的。
(4)抽樣理論
抽樣分類:重複抽樣與非重複抽樣
抽樣方式:完全隨機抽樣,等差距抽樣,分類和分層抽樣
++抽樣誤差(公式如下):

N——表示抽樣的數量,N——總體的數量
當N = 1時,重複抽樣與不重複抽樣公式一樣
當N = n時,沒有誤差,抽樣可代表整體。
某些情況下,我們需要根據控制在誤差水平之內確定抽樣的數量,使用以下公式:

3. 資料分類
定類(類別):根據事務離散,無差別屬性進行的分類例如:性別,民族
定序(順序):可以界定資料的大小,但不能測定差值例:收入的低中高
定距(間隔):可以界定資料大小的同時,可測定差值,但無絕對零點(乘法,除法無意義)例如:攝氏度
定比(比率):可以界定資料大小,可測定差值,有絕對零點例如:身高,體重,長度,體積
4. 單屬性分析
異常值分析:離散異常值,連續異常值,常識異常值。
++連續異常值(可以直接捨棄或取邊界值代替異常值):
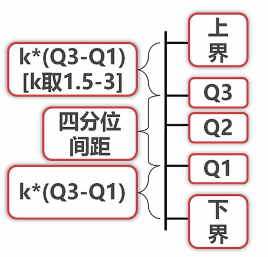
上下界之間的為正常值,其餘為異常值。K = 1.5時,鄰近邊界算是中等異常; K = 3時,是非常異常。異常值的出現很有可能讓大部分代表資料屬性的值失去意義(如,人均收入又被超高收入平均了,這個時候均值不如中位數更有說服力)。
Q1——下四分位數;
Q2——中位數;
Q3——上四分位數;
四分位間距——Q1與Q3之間的間距;
上四分位數向上取ķ倍,K一般取1.5〜3,可以確定個上界;同理,得下界。
++離散異常值(直接捨棄,也可把所有異常值當成一個單獨的值來處理(用個特殊標記標記,以區分其與正常值)):
離散屬性定義範圍外的所有值均為異常值(如:空值;收入離散化有中高低三類,其他值就為異常值)。
++知(常)識異常值:在限定知識與常識範圍外的所有值均為異常值。(如:身高超過10米,就不符合常理)。
對比分析:絕對數與相對數,(怎麼比)時間,空間,理論維度比較
++絕對數比較:比較收入,身高,評分之類的
++相對數比較:
1)結構相對數:像用產品合格率來評價產品質量;或用考試通過率來評價學生的整體水平或考題難度之類的;
2)比例相對數:總體內用不同部分的數值進行比較比如說,傳統意義上的,三大產業,農業,重工業和服務業的比例來相互比較,如哪個產業相對於哪個產業的比例發生什麼樣的變化。
3)比較相對數:同一時空下的,相似或同質的指標進行對比。如不同時期下的同一樣商品的價格;不同網際網路公司的待遇水平。
4)動態相對數:有時間的概念在裡面。如:物理上的速度,使用者數量的增速。
5)強度相對數:性質不同但又相互聯絡的屬性進行聯合如:人均(GDP),糧食畝產,密度。
++時間:現在跟過去比,過去跟未來比,由此未來推斷走勢。我們常會聽到兩個詞——同比(和去年同期進行比較),環比(比上個月)。
++空間:可以指現實方位上的空間,如不同城市,國家,地區等;也可以指邏輯上的空間,如一家公司的不同部門或者不同公司間進行比較。
++經驗與計劃:經驗的比較,如歷史上失業率達到百分之幾就很可能發生暴亂,各國之間失業率進行比較;計劃的比較,我們做工作需要排期,一個實施進度需要和計劃的排期進行比較。
結構分析(可看作對比分析中比例相對數的比較):各組成部分的分佈與規律
++靜態結構分析:直接分析系統的組成,如十一五期間三大產業的組成,第一產業13%,第二產業46%,第三產業41%,由此可確定我國的產業結構;同時,我們還可以把它跟美國,印度等國家進行比較,來衡量產業結構是否均衡,下一步該怎麼決策等等。
++動態結構分析:以時間為軸,分析結構變化的趨勢。我們知道十一五期間三大產業的佔比,那麼此期間三大產業是如何變化的,就能反應我們國家性質上的變化方向(第一產業大幅降低,第二產業小幅升高,而第三產業大幅升高,這就說明我們國家產業在轉型)。
分佈分析:資料分佈頻率的顯式分析
++直接獲得概率分佈:得到的數進行排列或將各個離散值的數量數出來進行排列就可得到它的分佈。(可能沒什麼意義,此時或進行比較或進行復合分析,得到的分佈才會有意義。)
++判斷一個分佈是不是正態分佈:
意義:如果一個分佈為正態分佈,那我們可輕易地用已有的性質 - 均值,方差等來快速定位某具體值相對於整體的位置如:如果得到一組數是正態分佈的結論,我們分析其中一個具體的數比較接近均值減去一倍標準差的位置,那麼我們基本就可以推斷大概有84.5%的樣本要比這個值大。那麼,84.5%是怎麼來到呢?像我們講過,正態分佈正負一倍標準差的值佔全部值的69%,那麼兩個邊緣以外的地方就各佔到了15.5%,所以比這個值大的樣本就佔到了84.5%。
快速判斷一個分佈不是正態分佈的方法:
1)如果一個分佈偏態絕對值比較大,那就不是正態分佈。這個值一般取到零點幾,具體的值要依據資料質量和業務場景而定。
2)如果正態分佈的峰態係數定為3,那麼<1和> 5的肯定不是正態分佈。同樣,若正態分佈峰值定為0,那麼<-2和> 2的不是正態分佈。
++極大似然(相似程度的衡量):可以表示一連串的數和分佈到底有多像。給出一串數字,我們知道它是屬於正態分佈的,就一定可以確定一個均值,一個方差,使該均值和方差確定的正態分佈下。這串數字的這幾個點在這個確定的分佈的取值就是他們的概率。這幾個值的和或積,在剛剛確定的均值和方差下是最大的。那麼對這幾個和或積取對數,就叫極大似然。還是那串數,怎麼判斷它更接近正態分佈,而不接近牛逼分佈呢?可以對比它在不同分佈下的極大似然。哪個極大似然越大,它就更接近哪個分佈。當然最大的極大似然是我們直接獲得的分佈,但這個分佈可能沒有意義,和已有的分佈建立聯絡,可能它的作用會更大。