
Elasticsearch筆記(三)—— Elasticsearch的基本操作
1.索引庫
Elasticsearch採用Rest風格API。
語法:
- 請求方式:PUT/GET/DELETE
- 請求路徑:/索引庫名
- 請求引數:json格式:
建立
PUT /test
{
"settings": {
"number_of_shards": 5, // 分片數量
"number_of_replicas": 1 // 副本數量
}
}
檢視
GET /test
刪除
DELETE /test
2.對映欄位
對映是定義文件的過程,文件包含哪些欄位,這些欄位是否儲存,是否索引,是否分詞等。
語法:
PUT /索引庫名/_mapping/型別名稱
{
"properties": {
"欄位名": {
"type": "型別",
"index": true,
"store": true,
"analyzer": "分詞器"
}
}
}
- 型別名稱:相當於type的概念,類似於資料庫中的不同表
欄位名:任意填寫 ,可以指定許多屬性,例如: - type:型別,可以是text、long、short、date、integer、object等
- index:是否索引,預設為true
- store:是否儲存,預設為false
- analyzer:分詞器,這裡的ik_max_word即使用ik分詞器
新增:
PUT /orcas/_mapping/products { "properties": { "title": { "type": "text", // text 可分詞 "analyzer": "ik_max_word" }, "images": { "type": "keyword", // keyword 不可分詞 "index": "false" }, "price": { "type": "float" } } }
查詢對映:
GET /orcas/_mapping
2.1.type
- String型別,又分兩種:
- text:可分詞,不可參與聚合
- keyword:不可分詞,資料會作為完整欄位進行匹配,可以參與聚合
- Numerical:數值型別,分兩類
- 基本資料型別:long、interger、short、byte、double、float、half_float
- 浮點數的高精度型別:scaled_float
- 需要指定一個精度因子,比如10或100。elasticsearch會把真實值乘以這個因子後儲存,取出時再還原。
- Date:日期型別
elasticsearch可以對日期格式化為字串儲存,但是建議我們儲存為毫秒值,儲存為long,節省空間。
2.2.index
- true:欄位會被索引,則可以用來進行搜尋。預設值就是true
- false:欄位不會被索引,不能用來搜尋
2.3.store
是否將資料進行額外儲存。預設值是false。
Elasticsearch在建立文件索引時,會將文件中的原始資料備份,儲存到_source的屬性中。可以通過過濾_source來選擇哪些要顯示,哪些不顯示。所以即便store設定為false,也可以搜尋到結果。
2.3.boost
激勵因子,影響權重
3.資料
語法:
POST /索引庫名/型別名
{
"key":"value"
}
新增資料:
POST /orcas/products/1
{
"title":"iPhone XS Max 256G",
"images":"bbbb.jpg",
"price":10999
}
響應:
{
"_index": "orcas",
"_type": "products",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 3,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
查詢所有:
GET /orcas/_search
{
"query": {"match_all": {}}
}
根據id查詢:
GET /orcas/products/1
修改資料:
- id對應文件存在,則修改
- id對應文件不存在,則新增
PUT /orcas/products/1
{
"title":"iPhone XS Max 256G",
"images":"bbbb.jpg",
"price":10999,
"stock": 999,
"desc": "貴得一比"
}
這裡在修改的時候新增了兩個欄位,Elasticsearch可以智慧地根據輸入的資料來判斷型別,自動新增資料對映。
響應:
{
"orcas": {
"mappings": {
"products": {
"properties": {
"desc": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"images": {
"type": "keyword",
"index": false
},
"price": {
"type": "float"
},
"stock": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
}
可以看到,stock和desc欄位成功映射了。
但如果儲存的是String類的資料,因為無法判斷是否分詞,我們可以看到,它實際是形成了兩種型別欄位:
- name: text型別
- name.keyword: keyword型別
PS:可以配置動態模板制定動態對映的規則,詳情見:
https://www.elastic.co/guide/en/elasticsearch/reference/current/dynamic-templates.html
刪除:
DELETE /索引庫名/型別名/id值
4.查詢
4.1基本查詢
語法:
GET /索引庫名/_search
{
"query":{
"查詢型別":{
"查詢條件":"查詢條件值"
}
}
}
4.1.1.查詢所有(match_all)
GET /orcas/_search
{
"query":{
"match_all": {}
}
}
- query:代表查詢物件
- match_all:代表查詢所有
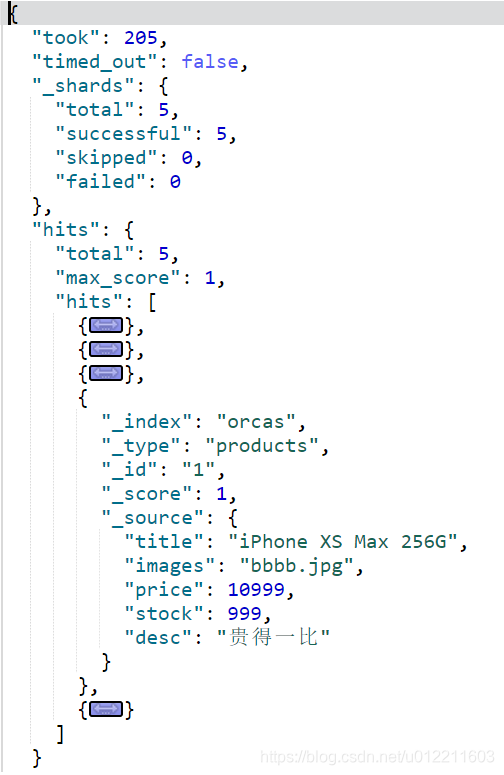
- took:查詢花費時間,單位是毫秒
- time_out:是否超時
- _shards:分片資訊
- hits:搜尋結果總覽物件
- total:搜尋到的總條數
- max_score:所有結果中文件得分的最高分
- hits:搜尋結果的文件物件陣列,每個元素是一條搜尋到的文件資訊
- _index:索引庫
- _type:文件型別
- _id:文件id
- _score:文件得分
- _source:文件的源資料
4.1.2.匹配查詢(match)
GET /orcas/_search
{
"query":{
"match":{
"title":"保溫杯"
}
}
}
- or關係
match型別查詢,會把查詢條件進行分詞,然後進行查詢,多個詞條之間是or的關係
GET /orcas/_search
{
"query":{
"match": {
"title": {
"query": "保溫杯",
"operator": "and"
}
}
}
}
- and關係
可以更精確查詢
match 查詢支援 minimum_should_match 最小匹配引數, 這讓我們可以指定必須匹配的詞項數用來表示一個文件是否相關。
4.1.3.多欄位查詢(multi_match)
GET /orcas/_search
{
"query":{
"multi_match": {
"query": "保溫杯",
"fields": [ "title", "subTitle" ]
}
}
}
4.1.4.詞條匹配(term)
term 查詢被用於精確值匹配,這些精確值可能是數字、時間、布林或者未分詞的字串。
GET /orcas/_search
{
"query":{
"term":{
"price":648.00
}
}
}
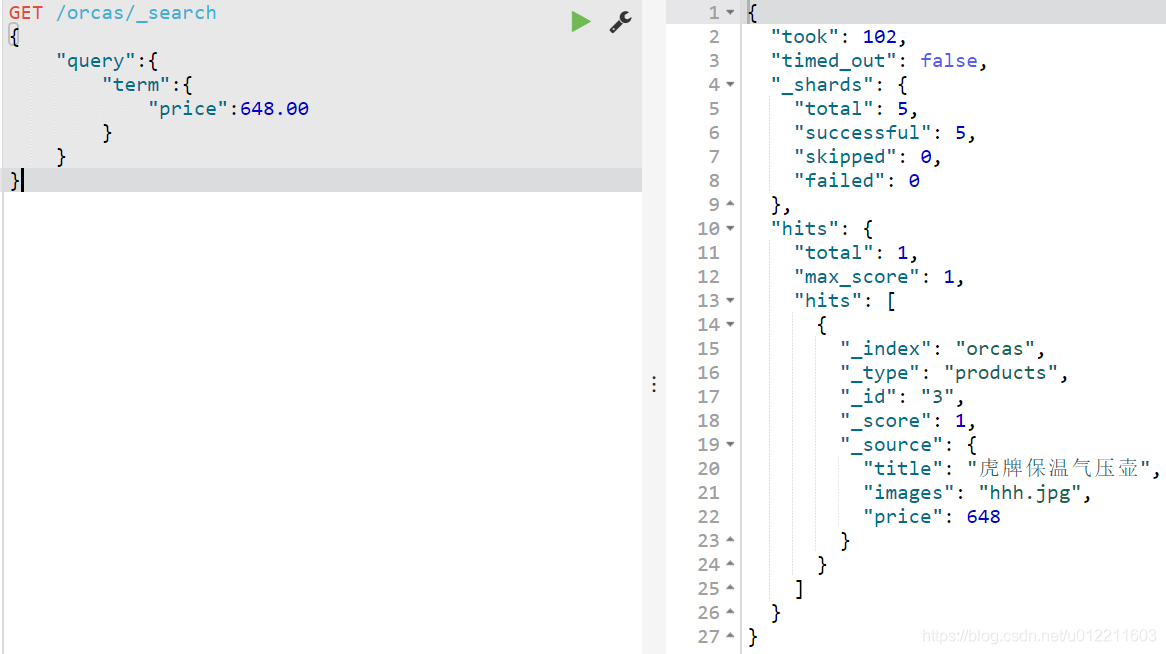
4.1.5.多詞條精確匹配(terms)
如果這個欄位包含了指定值中的任何一個值,那麼這個文件滿足條件。
GET /orcas/_search
{
"query":{
"terms":{
"price":[648.00,333.00,555.00]
}
}
}
4.2.結果過濾
4.2.1.指定欄位過濾
預設情況下,elasticsearch在搜尋的結果中,會把文件中儲存在_source的所有欄位都返回。
如果只想獲取其中的部分欄位,可以新增_source的過濾。
GET /orcas/_search
{
"_source": ["title","price"],
"query": {
"term": {
"price": 648
}
}
}
4.2.2.指定includes和excludes
- includes:來指定想要顯示的欄位
- excludes:來指定不想要顯示的欄位
GET /orcas/_search
{
"_source": {
"includes":["title","price"] // 或者 "excludes": ["images"]
},
"query": {
"term": {
"price": 648
}
}
}
4.3 高階查詢
4.3.1.範圍查詢(range)
查詢指定區間內的數字或者時間。
GET /orcas/_search
{
"query":{
"range": {
"price": {
"gte": 500.0,
"lt": 5000.00
}
}
}
}
4.3.2.布林組合(bool)
把各種其它查詢通過must(與)、must_not(非)、**should(或)**的方式進行組合。
GET /orcas/_search
{
"query":{
"bool":{
"must": [
{"match": {
"title": "保溫杯"
}}
],
"must_not": [
{"range": {
"price": {
"gte": 600
}
}}
]
}}
}
要查詢title為保溫杯(保溫杯分詞的),price不超過600元。

4.3.3.模糊查詢(fuzzy)
允許使用者搜尋詞條與實際詞條的拼寫出現偏差,但是偏差的編輯距離不得超過2。
GET /orcas/_search
{
"query": {
"fuzzy": {
"title": "aphonx" // 可以匹配到iphone
}
}
}
通過fuzziness來指定允許的編輯距離:
GET /orcas/_search
{
"query": {
"fuzzy": {
"title": {
"value":"aphone",
"fuzziness":1
}
}
}
}
這裡設定了1,因此上面例子中偏差的2個編輯距離的"aphonx"就查詢不到了。
4.4.過濾(filter)
4.4.1.有查詢條件的過濾
所有的查詢都會影響到文件的評分及排名。
如果需要在查詢結果中進行過濾,並且不希望過濾條件影響評分,就不要把過濾條件作為查詢條件來用。而是使用filter方式:
GET /orcas/_search
{
"query":{
"bool":{
"must": [
{"match": {
"title": "保溫杯"
}}
],
"filter": {
"bool": {
"must_not": [
{"range": {
"price": {
"gte": 600
}
}}
]
}
}
}
}
}
然而我實際沒使用filter時的_score和使用filter的相同的???
4.4.2.無查詢條件的過濾
如果一次查詢只有過濾,沒有查詢條件,不希望進行評分,可以使用constant_score取代只有 filter 語句的 bool 查詢。在效能上是完全相同的,但對於提高查詢簡潔性和清晰度有很大幫助。
GET /orcas/_search
{
"query":{
"constant_score": {
"filter": {
"range":{"price": {"lt":600.00 }}
}
}
}
}
4.5 排序
4.5.1. 單欄位排序
按照不同的欄位進行排序,並且通過order指定排序的方式
GET /orcas/_search
{
"query": {
"match": {
"title": "保溫杯"
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
4.5.1. 多欄位排序
假定我們想要結合使用 price和 _score(得分) 進行查詢,並且匹配的結果首先按照價格排序,然後按照相關性得分排序:
GET /orcas/_search
{
"query":{
"bool":{
"must":{ "match": { "title": "保溫杯" }},
"filter":{
"range":{"price":{"gt":200,"lt":600}}
}
}
},
"sort": [
{ "price": { "order": "desc" }},
{ "_score": { "order": "desc" }}
]
}
5.聚合aggregations
便於實現對資料的統計、分析。
5.1.基本概念
Elasticsearch中的聚合,包含多種型別,最常用的兩種,一個叫桶,一個叫度量:
桶(bucket):
桶的作用,是按照某種方式對資料進行分組,每一組資料在ES中稱為一個桶。
Elasticsearch中提供的劃分桶的方式有很多:
- Date Histogram Aggregation:根據日期階梯分組,例如給定階梯為周,會自動每週分為一組
- Histogram Aggregation:根據數值階梯分組,與日期類似
- Terms Aggregation:根據詞條內容分組,詞條內容完全匹配的為一組
- Range Aggregation:數值和日期的範圍分組,指定開始和結束,然後按段分組
- ……
度量(metrics):
分組完成以後,我們一般會對組中的資料進行聚合運算,例如求平均值、最大、最小、求和等,這些在ES中稱為度量。
比較常用的一些度量聚合方式:
- Avg Aggregation:求平均值
- Max Aggregation:求最大值
- Min Aggregation:求最小值
- Percentiles Aggregation:求百分比
- Stats Aggregation:同時返回avg、max、min、sum、count等
- Sum Aggregation:求和
- Top hits Aggregation:求前幾
- Value Count Aggregation:求總數
- ……
5.2.案例
例:
GET /cars/_search
{
"size": 0,
"aggs": {
"popular_brand": {
"terms": {
"field": "make"
},
"aggs": {
"price_avg": {
"avg": {
"field": "price"
}
}
}
}
}
}
結果:
......
......
"aggregations": {
"popular_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "honda",
"doc_count": 3,
"price_avg": {
"value": 16666.666666666668
}
},
{
"key": "ford",
"doc_count": 2,
"price_avg": {
"value": 27500
}
},
{
"key": "toyota",
"doc_count": 2,
"price_avg": {
"value": 13500
}
},
{
"key": "bmw",
"doc_count": 1,
"price_avg": {
"value": 80000
}
}
]
}
}