
mysql基礎架構之查詢語句執行流程
這篇筆記主要記錄mysql的基礎架構,一條查詢語句是如何執行的。
比如,在我們從student表中查詢一個id=2的資訊
select * from student where id=2;在解釋這條語句執行流程之前,我們看看mysql的基礎架構。
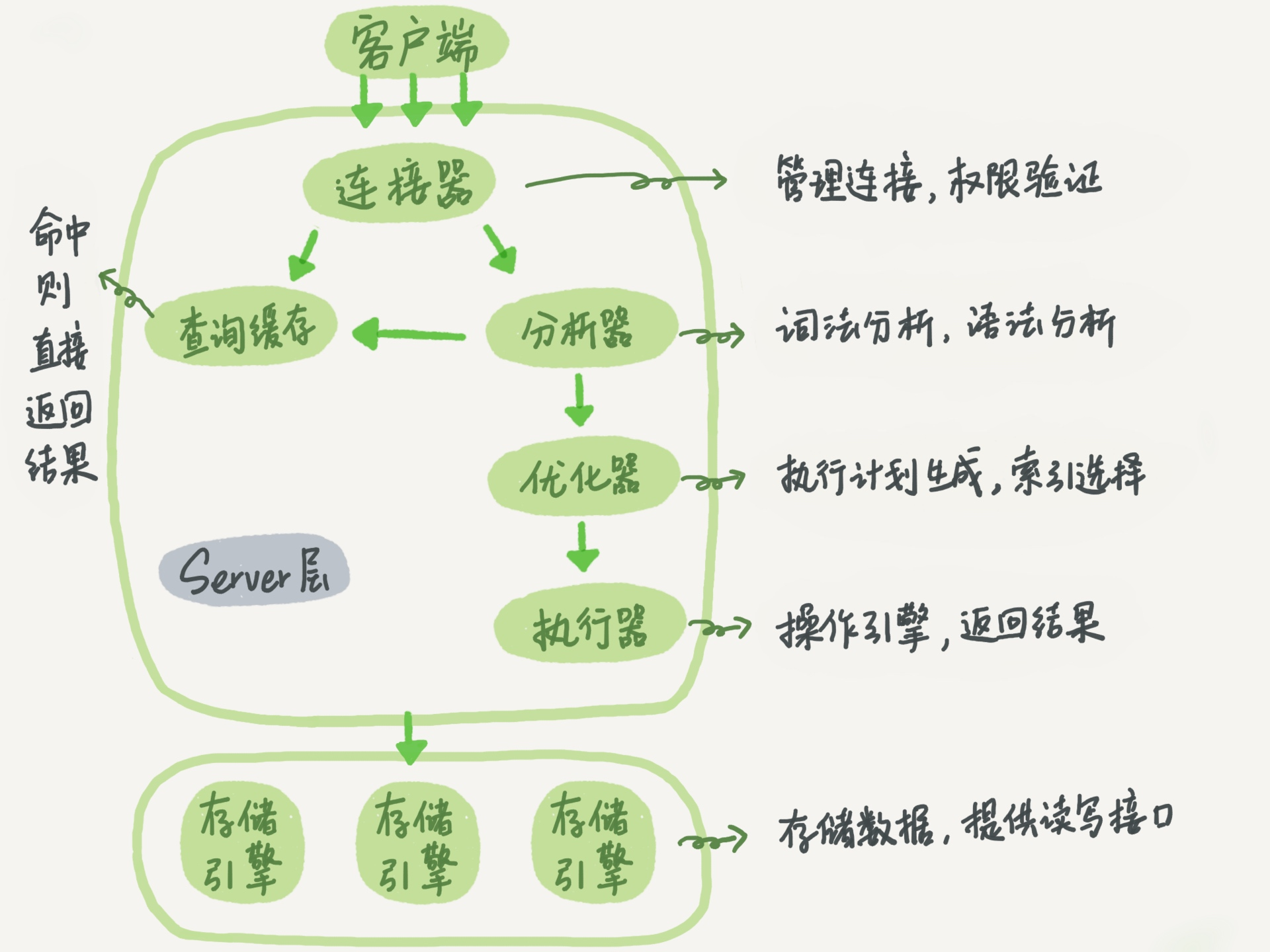
圖來自極客時間的mysql實踐,該圖是描述的是MySQL的邏輯架構。
- server層包括聯結器、查詢快取、分析器、優化器、執行器涵蓋 MySQL 的大多數核心服務功能,以及所有的內建函式所有跨儲存引擎的功能都在這一層實現,比如儲存過程、觸發器、視等。
- 儲存引擎層負責資料的儲存和提取。其架構模式是外掛式的,支援InnoDB、MyISAM、Memory 等多個儲存引擎,平常我們比較常用的是innoDB引擎
聯結器
我們在使用資料庫之前,需要連線到資料庫,連線語句是
mysql -h $ip -u $username -p $password而我們的聯結器就是處理這個過程的,聯結器的主要功能是負責跟客戶端建立連線、獲取許可權、維持和管理連線,聯結器在使用的過程中如果該使用者的許可權改變,是不會馬上生效的,因為使用者許可權是在連線的時候讀取的,只能重新連線才可以更新許可權
聯結器與客戶端通訊的協議是tcp協議的,連線以後可以使用show processlist;看到執行的連線數

同時在連線時間內超過8小時是sleep的狀態會自動斷開,這個是mysql預設設定,如果一直不斷開,那麼這個過程可以叫做一個長連線
與之對應的有短連線,短連線是指在執行一條或幾條的以後斷開連線。
當不斷使用長連線的時候會佔用很大的記憶體資源,在mysql5.7以後可以使用mysql_reset_connection語句來重新初始化資源。
查詢快取
經過連線以後,就連線上資料庫了,這個時候可以執行語句了。
執行語句的時候,mysql首先是去查詢快取,之前有沒有執行過這樣的語句,mysql會將之前執行過的語句和結果以key-value的形式儲存起來(當然有一定的儲存和實效時間)。如果存在快取,則直接返回快取的結果。
快取的工作流程是
- 伺服器接收SQL,以SQL和一些其他條件為key查詢快取表
- 如果找到了快取,則直接返回快取
- 如果沒有找到快取,則執行SQL查詢,包括原來的SQL解析,優化等。
- 執行完SQL查詢結果以後,將SQL查詢結果快取入快取表
當然,如果這個表修改了,那麼使用這個表中的所有快取將不再有效,查詢快取值得相關條目將被清空。所以在一張被反覆修改的表中進行語句快取是不合適的,因為快取隨時都會實效,這樣查詢快取的命中率就會降低很多,不是很划算。
當這個表正在寫入資料,則這個表的快取(命中快取,快取寫入等)將會處於失效狀態,在Innodb中,如果某個事務修改了這張表,則這個表的快取在事務提交前都會處於失效狀態,在這個事務提交前,這個表的相關查詢都無法被快取。
一般來說,如果是一張靜態表或者是很少變化的表就可以進行快取,這樣的命中率就很高。
下面來說說快取的使用時機,衡量開啟快取是否對系統有效能提升是一個很難的話題
- 通過快取命中率判斷, 快取命中率 = 快取命中次數 (
Qcache_hits) / 查詢次數 (Com_select) - 通過快取寫入率, 寫入率 = 快取寫入次數 (
Qcache_inserts) / 查詢次數 (Qcache_inserts) - 通過 命中-寫入率 判斷, 比率 = 命中次數 (
Qcache_hits) / 寫入次數 (Qcache_inserts), 高效能MySQL中稱之為比較能反映效能提升的指數,一般來說達到3:1則算是查詢快取有效,而最好能夠達到10:1
分析器
在查詢快取實效或者是無快取的時候,這個時候MySQL的server就會利用分析器來分析語句,分析器也叫解析器。
MySQL分析器由兩部分組成,第一部分是用來詞法分析掃描字元流,根據構詞規則識別單個單詞,MySQL使用Flex來生成詞法掃描程式在sql/lex.h中定義了MySQL關鍵字和函式關鍵字,用兩個陣列儲存;第二部分的功能是語法分析在詞法分析的基礎上將單詞序列組成語法短語,最後生成語法樹,提交給優化器語法分析器使用Bison,在sql/sql_yacc.yy中定義了語法規則。然後根據關係代數理論生成語法樹。
上面解釋分析器太官方和複雜了,其實分析器主要是用來進行“詞法分析”然後知道這個資料庫語句是要幹嘛,代表啥意思。
這個時候如果分析器分析出這個語句有問題的時候會報錯,比如ERROR 1064 (42000): You have an error in your SQL syntax
優化器
在分析器分析完了以後知道這個語句是幹嘛的時候,接下來是專門用一個優化器進行語句優化,優化器的任務是發現執行SQL查詢的最佳方案。大多數查詢優化器,包括MySQL的查詢優化器,總或多或少地在所有可能的查詢評估方案中搜索最佳方案。
優化器主要是選擇一個最佳的執行方案,執行方案是為了減少開銷,提高執行效率。
MySQL的優化器是一個非常複雜的部件,它使用了非常多的優化策略來生成一個最優的執行計劃:
- 重新定義表的關聯順序(多張表關聯查詢時,並不一定按照SQL中指定的順序進行,但有一些技巧可以指定關聯順序)
- 優化MIN()和MAX()函式(找某列的最小值,如果該列有索引,只需要查詢B+Tree索引最左端,反之則可以找到最大值,具體原理見下文)
- 提前終止查詢(比如:使用Limit時,查詢到滿足數量的結果集後會立即終止查詢)
- 優化排序(在老版本MySQL會使用兩次傳輸排序,即先讀取行指標和需要排序的欄位在記憶體中對其排序,然後再根據排序結果去讀取資料行,而新版本採用的是單次傳輸排序,也就是一次讀取所有的資料行,然後根據給定的列排序。對於I/O密集型應用,效率會高很多)
隨著MySQL的不斷髮展,優化器使用的優化策略也在不斷的進化,這裡僅僅介紹幾個非常常用且容易理解的優化策略而已。
執行器
在分析器知道語句要幹什麼,優化器知道怎麼做以後,下面就到了執行的階段,執行是交給執行器的。
執行器在執行的時候首先判斷該使用者對該表有沒有執行許可權,如果沒有則會返回denied之類的錯誤提示。
如果有許可權,則會開啟表繼續執行。開啟表的時候,執行器會根據表定義的引擎,去使用該引擎的介面。
最後執行語句得到資料返回給客戶端。
總結
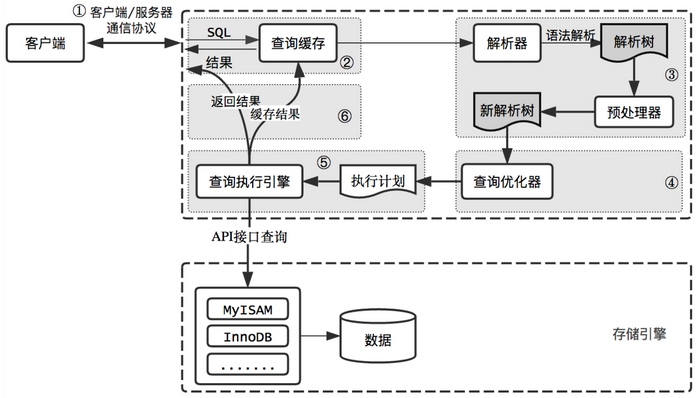
MySQL得到sql語句後,大概流程如下:
- 0.聯結器負責和客戶端進行通訊
- 1.查詢快取:首先查詢快取看是否存在k-v快取
- 2.解析器:負責解析和轉發sql
- 3.前處理器:對解析後的sql樹進行驗證
- 4.優化器:得到一個執行計劃
- 5.查詢執行引擎:執行器執行語句得到資料結果集
- 6.將資料放回給呼叫端。
