
大資料之Hadoop學習(環境配置)——Hadoop偽分散式叢集搭建
title: Hadoop偽分散式叢集搭建
date: 2018-11-14 15:17:20
tags: Hadoop
categories: 大資料
點選檢視我的部落格: Josonlee’s Blog
文章目錄
前言準備
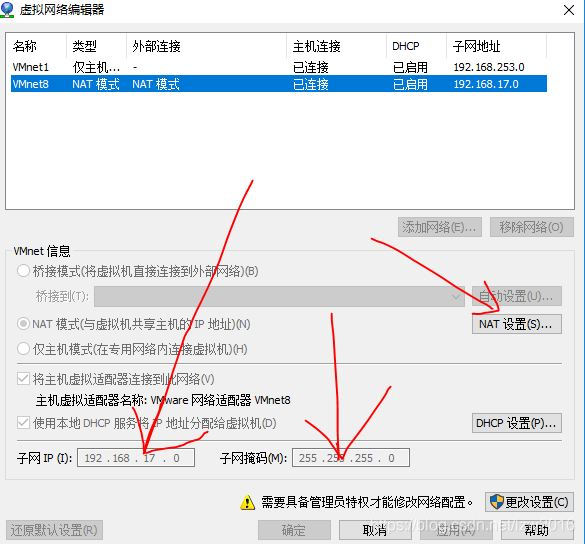
Win10上通過VMware12 + Centos7準備好了基本環境,配置虛擬機器的子網IP地址(我這裡是192.168.17.0),如圖通過管理員可配置子網IP,掩碼,閘道器(我這裡是192.168.17.2)
下文提到的檔案上傳到虛擬機器中,建議使用WinSCP工具
偽分散式特點
具備Hadoop的所有功能,在單機上模擬一個分散式的環境,需要配置hdfs和yarn框架
- HDFS:主節點:master,從節點:slave 【偽分散式這裡也是master】
- Yarn:容器,執行MapReduce程式
- 主節點:ResourceManager
- 從節點:NodeManager
JDK 下載和環境配置
- 下載安裝
這裡下載Linux版本:http://www.oracle.com/technetwork/java/javase/downloads/index.html ,我這裡使用的是 jdk-8u131-linux-x64 版本
首先要把下載的檔案上傳到centos系統下的隨便那個目錄下(最好root下),把檔案解壓縮到/root 目錄下
以下操作都是在root管理員許可權下操作
cd /root
rpm -ivh [你下載的檔名]
- 環境配置
編輯環境變數,在/etc/profile檔案中新增如下變數
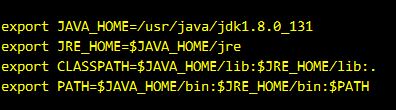
注意,我這裡jdk1.8.0_131換成你下載的jdk版本號即可
- 測試
命令列下輸入 java -version,能正確檢視到java的版本就表示上面步驟配置成功
配置虛擬機器網路環境
首先要知道完全分散式和偽分散式的原理是一樣的,都得有master和slave節點,節點之間通訊時不可能有DHCP臨時隨機配置IP,所以要配置虛擬機器的固定IP
- 設定靜態IP
同樣是在/etc下(這是配置檔案所在地)
ls sysconfig/network-scripts/ifcfg-ens*
# 輸出結果就是要配置的檔案
vi sysconfig/network-scripts/ifcfg-en*
# 進入編輯
改動以下設定
BOOTPROTO=static //改成static
ONBOOT=yes //改成yes
IPADDR=192.168.17.10 //隨便設,不過要在子網192.168.17.0下
NETMASK=255.255.255.0 //掩碼
GATEWAY=192.168.17.2 //第一步配置時設好的
DNS1=192.168.17.2 //隨便寫
- 設定主機名
命令列下輸入hostname可檢視主機名,一般是localhost,但為了方便重新設定主機名
vi /etc/hostname
刪掉原先的,配置主機名(如master,namenode等)
- 繫結IP地址到主機名的對映
vi /etc/hosts
# 追加如下內容
127.168.17.10 master //就是你配置的固定IP和主機名
- 關閉防火牆
我這裡是centos,防火牆是firewall,而不是iptables【其他系統有其他關閉方法】。防火牆務必要關閉,否則完全分散式搭建的話無法和其他主機相連
systemctl stop firewalld //停止firewall服務
systemctl disable firewalld //禁止firewall開機啟動
然後可以通過systemctl status firewalld檢視防火牆狀態
Active: inactive (dead) //這就是關閉了
- 重啟網路服務
systemctl restart network,然後你可以ping以下主機名ping master,看可以ping通嗎,可以的話就OK
配置Hadoop的環境
下載Hadoop
(1) apache hadoop:http://www-us.apache.org/dist/hadoop/common/ 【這個是開源的】
(2) cloudera hadoop(CDH):http://archive-primary.cloudera.com/cdh5/cdh/5/ 【推薦使用】
CDH是hadoop的一個版本,我們老師推薦的,原因沒記住是啥
上傳並解壓安裝
我這裡是下的hadoop-2.6.0-cdh5.12.1,一樣是上傳放在了/root目錄下
tar -zxvf hadoop-2.6.0-cdh5.12.1.tar.gz -C /home/hadoop //把hadoop-2.6.0-cdh5.12.1解壓到/home/hadoop目錄下
cd /home/hadoop/hadoop-2.6.0-cdh5.12.1 //切換到該目錄下
hdfs在執行時需要name,data,logs,tmp資料夾用來存放原資料,實際資料,日誌,臨時檔案
mkdir hdfs hdfs/name hdfs/data logs tmp //在hadoop目錄中建立
配置Hadoop環境變數
vi /home/hadoop/.bash_profile
# 修改新增下列內容
export HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.12.1 //hadoop主目錄
export HADOOP_LOG_DIR=$HADOOP_HOME/logs //hadoop日誌目錄
export YARN_LOG_DIR=$HADOOP_LOG_DIR //YARN日誌目錄
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH //新增hadoop命令路徑
中文去掉
修改hadoop配置檔案
我在文末會放一個連結,你可以直接下載,修改其中的主機名上傳到/home/hadoop/hadoop-2.6.0-cdh5.12.1/etc/hadoop目錄下,覆蓋原檔案即可
cd /home/hadoop/hadoop-2.6.0-cdh5.12.1/etc/hadoop
中文統統都去掉
- 設定java所在環境變數
在hadoop-env.sh、mapred-env.sh、yarn-env.sh中分別設定JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_131 //之前設定的
- 配置slaves檔案 設定slave節點名
vi slaves
#新增slave節點名
master
因為是偽分散式,一臺虛擬機器充當master也充當slave
- 修改log4j.properties檔案
追加一行內容:log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR,避免啟動時報警
- 配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value> //指定對外訪問介面
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.6.0-cdh5.12.1/tmp</value> //指定臨時檔案放哪
</property>
</configuration>
- 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop-2.6.0-cdh5.12.1/hdfs/name</value> //元資料放哪
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop-2.6.0-cdh5.12.1/hdfs/data</value> //實際資料放哪
</property>
<property>
<name>dfs.replication</name>
<value>1</value> // 這個1是指定資料備份幾份 【預設3份,偽分散式1是因為只有一個slave】
</property>
<property>
<name>dfs.permissions</name>
<value>false</value> // 跳過身份驗證
</property>
</configuration>
以上是hdfs的配置,下面是yarn的配置
- 配置mapred-site.xml檔案
cp mapred-site.xml.template mapred-site.xml
該檔案預設不存在,需要用模板檔案來建立
<configuration>
<property>
<name>mapreduce.framework.name</name> //配置MapReduce執行時用的框架為yarn
<value>yarn</value>
</property>
</configuration>
- 配置yarn-site.xml檔案
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name> //配置ResourceManager的地址
<value>master:8031</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name> //配置NodeManager執行任務的方式
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 設定hadoop目錄的owner
chown -R hadoop:hadoop /home/hadoop/hadoop-2.6.0-cdh5.12.1 //修改hadoop目錄的owner
以上就是Hadoop基本配置
配置hadoop使用者免密登入
從上文可以看出,我的centos的普通使用者是hadoop(/home/hadoop),設定hadoop使用者免密登入可以便於叢集間後臺資料傳輸時省去密碼的輸入過程
這裡使用ssh免密登入,rsa加密演算法
- 切換到hadoop使用者
- 命令列執行
ssh -keygen -t rsa- 遇到提示時,回車即可;三次回車
- 預設會在
/home/hadoop/.ssh/下生成私鑰(id_rsa)、公鑰(id_rsa.pub)
進入.ssh目錄,把公鑰彙總到授權檔案(authorized_keys),並授權
cd ~/.ssh
cat id_rsa.pub >> authorized_keys //在master執行,合併授權檔案
chmod 600 authorized_keys //設定授權檔案的訪問許可權為讀寫
如果是完全分散式搭建,這裡略有不同。要在每臺主機上都生成公鑰、私鑰,並把公鑰彙總到master節點的授權檔案中,然後master再把授權檔案分發給每個節點
- 測試ssh免密登入
如果配置成功,輸入ssh master[主機名]即可登入,登入會顯示Last login:XXX...。第一次登入會有提示,輸入yes就OK
如果以上配置都成功了,那恭喜你,配置成功了
啟動Hadoop
格式化hdfs檔案系統
第一次啟動時乾的
hdfs namenode -format
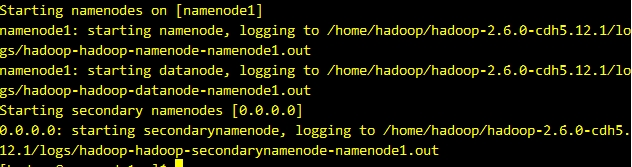
啟動hdfs
start-dfs.sh
結果如下圖
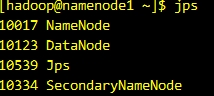
你可以使用jps命令檢視當前執行的程序
你也可以本地通過瀏覽器檢視,開啟瀏覽器輸入 http://192.168.17.10:50070 【這個IP是前面配的固定IP地址】
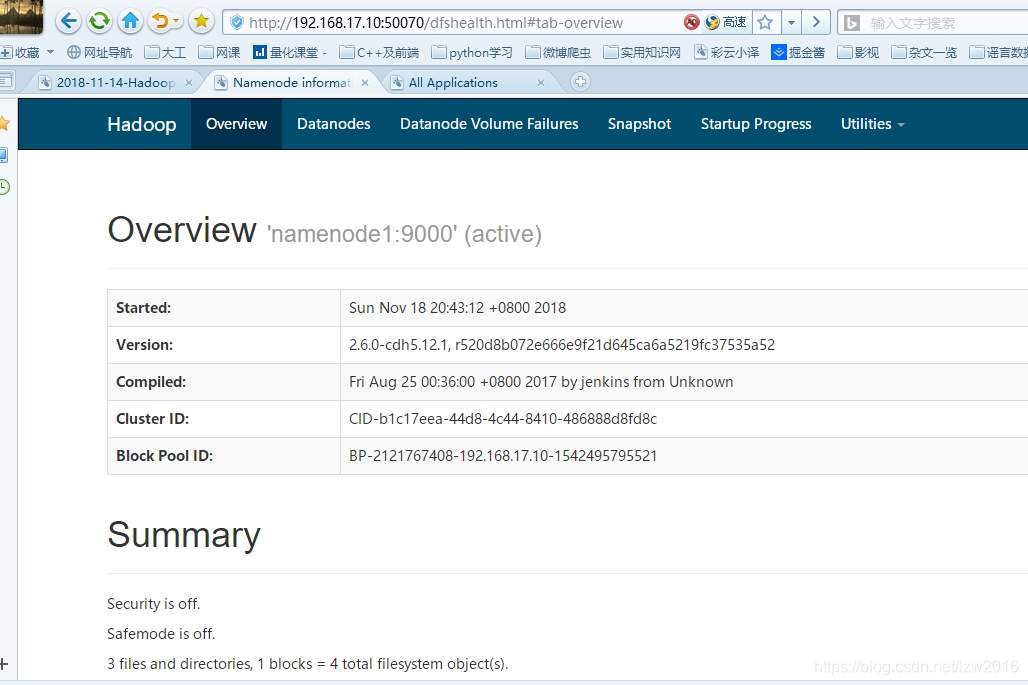
啟動yarn
start-yarn.sh
master啟動ResourceManager程序,slave啟動NodeManager程序

你也可以本地通過瀏覽器檢視,開啟瀏覽器輸入 http://192.168.17.10:8088
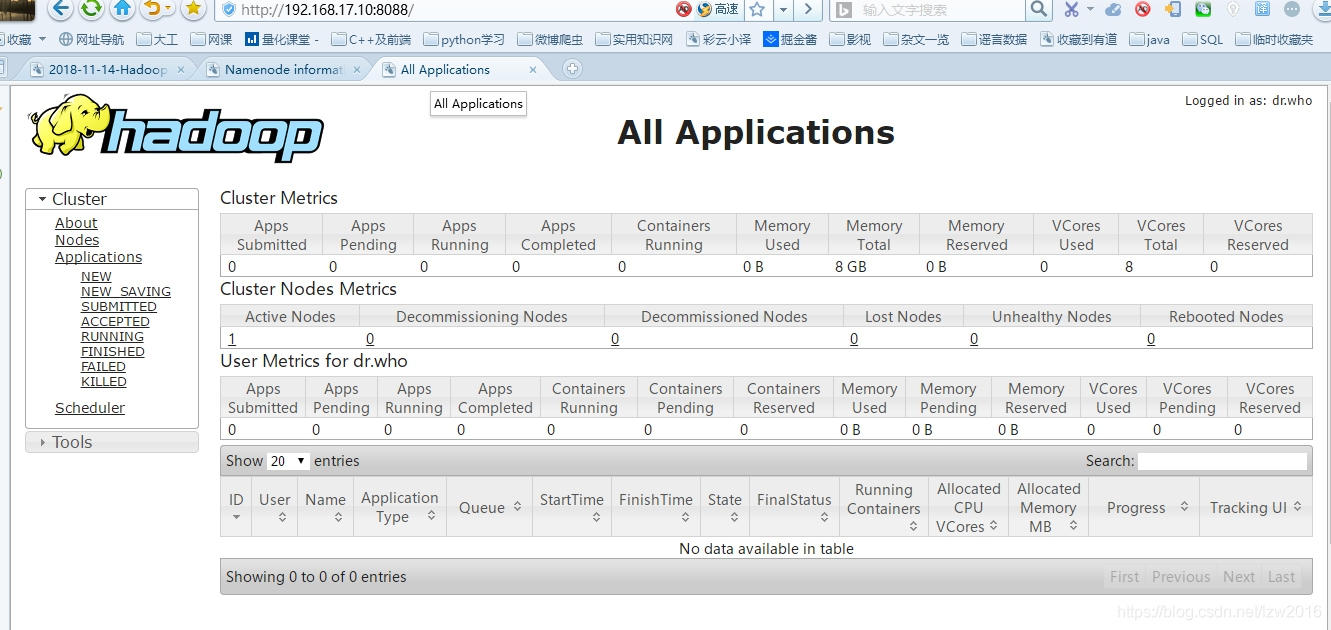
啟動JobHistory Server(MR)
mr-jobhistory-daemon.sh start historyserver
記錄分散式環境下提交的作業記錄,namenode啟動JobHistoryServer程序
你也可以本地通過瀏覽器檢視,開啟瀏覽器輸入 http://192.168.17.10:19888
最近開的大資料課,包含Hadoop和Spark倆門,會不定時記錄學習心得,優先會記錄在github部落格上,有空就遷移過來
點選檢視我的部落格: Josonlee’s Blog
這是我文中提到的我配置好的配置檔案,點選下載即可,要修改處可參考我文中的註釋
下一篇會談如何編寫MapReduce程式和如何本地配置eclipse連線虛擬機器hdfs伺服器