
ElasticSearch+Logstash+Filebeat+Kibana叢集日誌管理分析平臺搭建
一、ELK搜尋引擎原理介紹
在使用搜索引擎是你可能會覺得很簡單方便,只需要在搜尋欄輸入想要的關鍵字就能顯示出想要的結果。但在這簡單的操作背後是搜尋引擎複雜的邏輯和許多元件協同工作的結果。
搜尋引擎的元件一般可分為兩大類:索引元件和搜尋元件。在搜尋之前搜尋引擎必須把可搜尋的所有資料做整合處理並構建索引(倒排索引),將所有資料構建成能被搜尋的格式並存儲起來,這就成為索引元件;能根據使用者搜尋並能從索引元件構建的索引中查詢出使用者想要的結果的元件稱為搜尋元件。
ElasticSearch就屬於搜尋元件的一種,並且它是一個分散式搜尋伺服器,在搭建ElasticSearch叢集時最好有三臺以上的伺服器,因為它的資料都是分片儲存的。Lucene是Apache提供的開源專案,是一個完全用Java編寫的搜尋引擎庫。ElasticSearch使用Lucene作為內部的搜尋索引構建庫,使ElasticSearch集成了搜尋引擎的兩大核心元件。雖然用這兩個元件可以完成索引構建並進行搜尋操作,但成為完善的搜尋引擎是不夠的。
對於叢集日誌分析平臺來說,還需要對大量應用服務的日誌資料進行採集,並按需要的格式進行劃分、儲存、分析,這就要用到Logstash和Filebeat元件。
Filebeat是一個非常輕量化的日誌採集元件,Filebeat 內建的多種模組(auditd、Apache、NGINX、System 和 MySQL)可實現對常見日誌格式的一鍵收集、解析和視覺化。而Logstash是一個開源的伺服器端資料處理管道,它可以同時從多個源中提取資料,對其進行轉換,然後輸出到指定位置。
在解決上面一系列問題後,搜尋引擎還需要提供一個友善的使用者介面來展示給使用者,使使用者能夠進行傻瓜式的搜尋操作,並且還能將搜尋結果通過各種直觀的方式展示在使用者面前。這是就要用到Kibana元件。Kibana可以讓ElasticSearch資料極為豐富的展現出來。
上面提到的元件除了Lucene庫意外其他的都屬於Elastic Stack家族的產品,在普遍的企業中都是採用這些元件構建成叢集來分析處理大量的日誌資料的。更多元件可訪問Elastic官網站點。
二、ELK日誌分析叢集搭建
1.基本架構
在本文示例中,以下面的結構來進行演示,圖1:
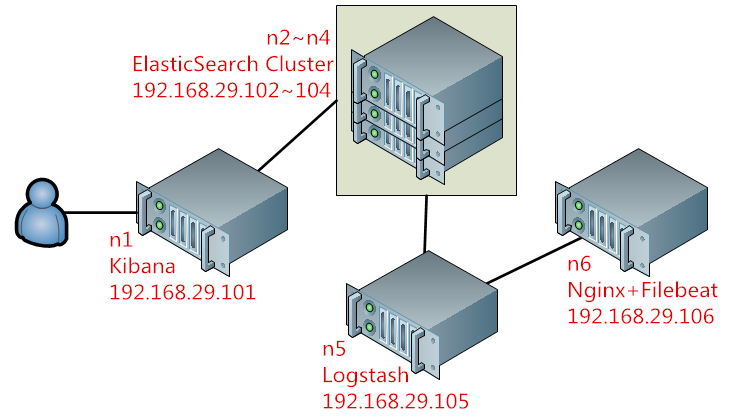
在上圖所示的架構的工作邏輯:Kibana將ElasticSearch叢集提供的搜尋內容進行視覺化處理,並用多種方式展現給使用者;ElasticSearch叢集和其整合的Lucene用來完成對所有采集到的資料進行分析構建索引並提供搜尋;而資料的來源則是通過Logstash和FileBeat採集自Nginx日誌,Logstash將來自FileBeat的資料過濾並輸出給ElasticSearch叢集。
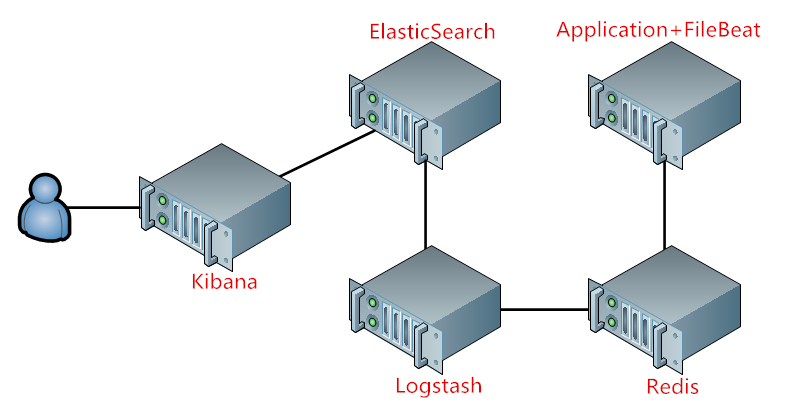
在叢集達到一定規模後,大量的後端應用通過FileBeat採集到資料輸出到Logstash會使Logstash Server稱為效能瓶頸,因為Logstash是用Java程式開發的,很消耗記憶體,當資料處理量大後效能會大打折扣;所以可以在Logstash和FileBeat之間增加Redis,Redis專門用來做佇列資料庫,將在FieBeat中採集的資料平緩的輸出到Logstash。如圖2:
2.搭建ElasticSearch叢集
Linux版本:CentOS7.2
ElasticSearch:5.5.1
下面先用圖1的架構示例來構建叢集,完成後再引入Redis來進行演示,當叢集沒有達到很龐大規模時引入Redis不會對叢集效能有實質性的提升。
由於ElasticSearch是用Java開發的,執行時依賴JDK環境,ElasticSearch叢集所有節點上都需要裝上JDK。在n2~n4節點上安裝ElasticSearch和JDK:
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
在官網下載ElasticSearch,我這裡安裝的是ElasticSearch5.5.1版本,在官網下載rpm包直接安裝:
rpm -ivh elasticsearch-5.5.1.rpm
ElasticSearch5的程式環境:
1 /etc/elasticsearch/elasticsearch.yml #主程式配置檔案 2 /etc/elasticsearch/jvm.options #java配置檔案 3 /etc/elasticsearch/log4j2.properties #日誌配置檔案
主配合檔案配置段:
1 Cluster #叢集配置段,需要設定ElasticSearch叢集名稱 2 Node #各節點配置段,要設定當前主機的主機名 3 Paths #各類路徑配置段 4 Memory #記憶體配置段 5 Network #網路配置段 6 Discovery # 7 Gateway 8 Various


1 # ---------------------------------- Cluster ----------------------------------- 2 # 3 # Use a descriptive name for your cluster: 4 # 5 #cluster.name: my-application 6 cluster.name: myels #叢集名稱,ElasticSearch是基於叢集名和主機名來識別叢集成員的 7 # ------------------------------------ Node ------------------------------------ 8 # 9 # Use a descriptive name for the node: 10 # 11 #node.name: node-1 12 node.name: n2 #本節點名 13 # Add custom attributes to the node: 14 # 15 #node.attr.rack: r1 16 # 17 # ----------------------------------- Paths ------------------------------------ 18 # 19 # Path to directory where to store the data (separate multiple locations by comma): 20 # 21 #path.data: /path/to/data 22 path.data: /els/data #查詢索引資料存放路徑 23 # Path to log files: 24 path.data: /els/logs #日誌路徑 25 #path.logs: /path/to/logs 26 # 27 # ----------------------------------- Memory ----------------------------------- 28 # 29 # Lock the memory on startup: 30 # 31 #bootstrap.memory_lock: true #是否開啟時就劃用所有記憶體 32 # 33 # Make sure that the heap size is set to about half the memory available 34 # on the system and that the owner of the process is allowed to use this 35 # limit. 36 # 37 # Elasticsearch performs poorly when the system is swapping the memory. 38 # 39 # ---------------------------------- Network ----------------------------------- 40 # 41 # Set the bind address to a specific IP (IPv4 or IPv6): 42 # 43 #network.host: 192.168.0.1 44 network.host: 192.168.29.102 #監聽地址,預設是本地 45 # Set a custom port for HTTP: 46 # 47 #http.port: 9200 #監聽埠 48 # 49 # For more information, consult the network module documentation. 50 # 51 # --------------------------------- Discovery ---------------------------------- 52 # 53 # Pass an initial list of hosts to perform discovery when new node is started: 54 # The default list of hosts is ["127.0.0.1", "[::1]"] 55 # 56 discovery.zen.ping.unicast.hosts: ["n2", "n3", "n4"] #為了安全起見,儘量將ElasticSearch節點的解析名配置進來(畫圈圈) 57 # 58 # Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1): 59 # 60 discovery.zen.minimum_master_nodes: 2 #腦裂預防選項 61 # 62 # For more information, consult the zen discovery module documentation. 63 # 64 # ---------------------------------- Gateway ----------------------------------- 65 # 66 # Block initial recovery after a full cluster restart until N nodes are started: 67 # 68 #gateway.recover_after_nodes: 3 69 # 70 # For more information, consult the gateway module documentation. 71 # 72 # ---------------------------------- Various ----------------------------------- 73 # 74 # Require explicit names when deleting indices: 75 # 76 #action.destructive_requires_name: trueElasticSearch主配置
建立資料和日誌目錄並修改目錄許可權並啟動ElasticSearch:
mkdir -pv /els/{data,logs} chown -R elasticsearch.elasticsearch /els/
systemctl start elasticsearch
啟動時發生了錯誤:
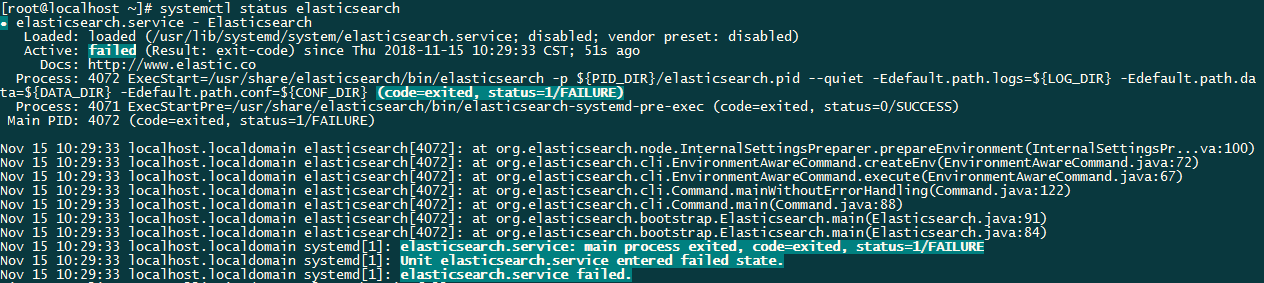
檢視 /var/log/messages 發現一條警告資訊:
elasticsearch: OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
這是因為JVM中的 ParallelGCThreads 引數未設定正確導致的,我修改了虛擬機器的執行緒數後又出現了新的報錯:
elasticsearch: Exception in thread "main" ElasticsearchParseException[duplicate settings key [path.data] found at line number [36], column number [12], previous value [/els/data], current value [/els/logs]]
這個的大致意思就是路徑衝突了,後來發現在主配置檔案中我將 path.logs: /els/logs 寫成了 path.data: /els/logs ,導致路徑衝突。
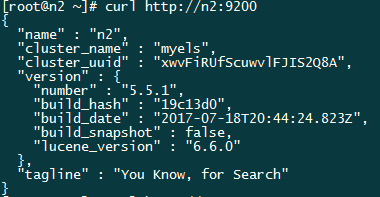
啟動完成後可以看到9200和9300埠被監聽:

至此ElasticSearch叢集就已經工作起來了。
2.安裝Kibana
在n1上安裝Kibana:
rpm -ivh kibana-5.5.1-x86_64.rpm
修改Kibana配置檔案:
vim /etc/kibana/kibana.yml
1 # Kibana is served by a back end server. This setting specifies the port to use. 2 #server.port: 5601 3 server.port: 5601 #監聽埠 4 # Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values. 5 # The default is 'localhost', which usually means remote machines will not be able to connect. 6 # To allow connections from remote users, set this parameter to a non-loopback address. 7 #server.host: "localhost" 8 server.host: "192.168.29.101" #監聽地址 9 # Enables you to specify a path to mount Kibana at if you are running behind a proxy. This only affects 10 # the URLs generated by Kibana, your proxy is expected to remove the basePath value before forwarding requests 11 # to Kibana. This setting cannot end in a slash. 12 #server.basePath: "" 13 14 # The maximum payload size in bytes for incoming server requests. 15 #server.maxPayloadBytes: 1048576 16 17 # The Kibana server's name. This is used for display purposes. 18 #server.name: "your-hostname" 19 server.name: "n1" #主機名 20 # The URL of the Elasticsearch instance to use for all your queries. 21 #elasticsearch.url: "http://n2:9200" 22 elasticsearch.url: "http://n2:9200" #ElasticSearch地址 23 # When this setting's value is true Kibana uses the hostname specified in the server.host 24 # setting. When the value of this setting is false, Kibana uses the hostname of the host 25 # that connects to this Kibana instance. 26 #elasticsearch.preserveHost: true 27 28 # Kibana uses an index in Elasticsearch to store saved searches, visualizations and 29 # dashboards. Kibana creates a new index if the index doesn't already exist. 30 #kibana.index: ".kibana" 31 32 # The default application to load. 33 #kibana.defaultAppId: "discover" 34 35 # If your Elasticsearch is protected with basic authentication, these settings provide 36 # the username and password that the Kibana server uses to perform maintenance on the Kibana 37 # index at startup. Your Kibana users still need to authenticate with Elasticsearch, which 38 # is proxied through the Kibana server. 39 #elasticsearch.username: "user" #可以設定登入認證使用者和密碼 40 #elasticsearch.password: "pass" 41 42 # Enables SSL and paths to the PEM-format SSL certificate and SSL key files, respectively. 43 # These settings enable SSL for outgoing requests from the Kibana server to the browser. 44 #server.ssl.enabled: false 45 #server.ssl.certificate: /path/to/your/server.crt 46 #server.ssl.key: /path/to/your/server.key 47 48 # Optional settings that provide the paths to the PEM-format SSL certificate and key files. 49 # These files validate that your Elasticsearch backend uses the same key files. 50 #elasticsearch.ssl.certificate: /path/to/your/client.crt 51 #elasticsearch.ssl.key: /path/to/your/client.key 52 53 # Optional setting that enables you to specify a path to the PEM file for the certificate 54 # authority for your Elasticsearch instance. 55 #elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ] 56 57 # To disregard the validity of SSL certificates, change this setting's value to 'none'. 58 #elasticsearch.ssl.verificationMode: full 59 60 # Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of 61 # the elasticsearch.requestTimeout setting. 62 #elasticsearch.pingTimeout: 1500 63 64 # Time in milliseconds to wait for responses from the back end or Elasticsearch. This value 65 # must be a positive integer. 66 #elasticsearch.requestTimeout: 30000 67 68 # List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side 69 # headers, set this value to [] (an empty list). 70 #elasticsearch.requestHeadersWhitelist: [ authorization ] 71 72 # Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten 73 # by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration. 74 #elasticsearch.customHeaders: {} 75 76 # Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable. 77 #elasticsearch.shardTimeout: 0 78 79 # Time in milliseconds to wait for Elasticsearch at Kibana startup before retrying. 80 #elasticsearch.startupTimeout: 5000 81 82 # Specifies the path where Kibana creates the process ID file. 83 #pid.file: /var/run/kibana.pid 84 85 # Enables you specify a file where Kibana stores log output. 86 #logging.dest: stdout 87 88 # Set the value of this setting to true to suppress all logging output. 89 #logging.silent: false 90 91 # Set the value of this setting to true to suppress all logging output other than error messages. 92 #logging.quiet: false 93 94 # Set the value of this setting to true to log all events, including system usage information 95 # and all requests. 96 #logging.verbose: false 97 98 # Set the interval in milliseconds to sample system and process performance 99 # metrics. Minimum is 100ms. Defaults to 5000. 100 #ops.interval: 5000 101 102 # The default locale. This locale can be used in certain circumstances to substitute any missing 103 # translations. 104 #i18n.defaultLocale: "en"View Code
瀏覽器訪問http://192.168.29.101:5601,顯示如下,說明Kibana已經安裝成功:

3.在n6上安裝Nginx和Filebeat
前面已經將ElasticSearch搜尋引擎最重要的部分搭建完成了,可以進行搜尋和構建索引了。下面來部署資料採集的部分。我這裡用Nginx來做演示,用Filebeat將Nginx的日誌蒐集並輸出給ElasticSearch並構建索引提供搜尋。
在n6節點安裝Nginx和Filebeat:
rpm -ivh filebeat-5.5.1-x86_64.rpm yum install -y nginx
配置Filebeat並啟動:
vim /etc/filebeat/filebeat.yml
1 #=========================== Filebeat prospectors ============================= 2 3 filebeat.prospectors: 4 5 # Each - is a prospector. Most options can be set at the prospector level, so 6 # you can use different prospectors for various configurations. 7 # Below are the prospector specific configurations. 8 9 - input_type: log 10 11 # Paths that should be crawled and fetched. Glob based paths. 12 paths: 13 #- /var/log/*.log 14 - /var/log/nginx/access.log #指定要採集的日誌檔案路徑 15 #- c:\programdata\elasticsearch\logs\* 16 17 # Exclude lines. A list of regular expressions to match. It drops the lines that are 18 # matching any regular expression from the list. 19 #exclude_lines: ["^DBG"] 20 21 # Include lines. A list of regular expressions to match. It exports the lines that are 22 # matching any regular expression from the list. 23 #include_lines: ["^ERR", "^WARN"] 24 25 # Exclude files. A list of regular expressions to match. Filebeat drops the files that 26 # are matching any regular expression from the list. By default, no files are dropped. 27 #exclude_files: [".gz$"] 28 29 # Optional additional fields. These field can be freely picked 30 # to add additional information to the crawled log files for filtering 31 #fields: 32 # level: debug 33 # review: 1 34 35 ### Multiline options 36 37 # Mutiline can be used for log messages spanning multiple lines. This is common 38 # for Java Stack Traces or C-Line Continuation 39 40 #multiline.pattern: ^\[ 41 42 # Defines if the pattern set under pattern should be negated or not. Default is false. 43 #multiline.negate: false 44 45 #multiline.match: after 46 47 48 #================================ General ===================================== 49 50 # The name of the shipper that publishes the network data. It can be used to group 51 # all the transactions sent by a single shipper in the web interface. 52 #name: 53 54 # The tags of the shipper are included in their own field with each 55 # transaction published. 56 #tags: ["service-X", "web-tier"] 57 58 # Optional fields that you can specify to add additional information to the 59 # output. 60 #fields: 61 # env: staging 62 63 #================================ Outputs ===================================== 64 65 # Configure what outputs to use when sending the data collected by the beat. 66 # Multiple outputs may be used. 67 68 #-------------------------- Elasticsearch output ------------------------------ 69 output.elasticsearch: 70 # Array of hosts to connect to. 71 hosts: ["n2:9200"] #資料輸出到ElasticSearch,填寫叢集其中的一個即可 72 73 # Optional protocol and basic auth credentials. 74 #protocol: "https" 75 #username: "elastic" 76 #password: "changeme" 77 78 #----------------------------- Logstash output -------------------------------- 79 #output.logstash: 80 # The Logstash hosts 81 #hosts: ["localhost:5044"] 82 83 # Optional SSL. By default is off. 84 # List of root certificates for HTTPS server verifications 85 #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] 86 87 # Certificate for SSL client authentication 88 #ssl.certificate: "/etc/pki/client/cert.pem" 89 90 # Client Certificate Key 91 #ssl.key: "/etc/pki/client/cert.key" 92 93 #================================ Logging ===================================== 94 95 # Sets log level. The default log level is info. 96 # Available log levels are: critical, error, warning, info, debug 97 #logging.level: debug 98 99 # At debug level, you can selectively enable logging only for some components. 100 # To enable all selectors use ["*"]. Examples of other selectors are "beat", 101 # "publish", "service". 102 #logging.selectors: ["*"]View Code
systemctl start filebeat
在瀏覽器上訪問n6節點,使Nginx生成日誌檔案,觸發Filebeat將資料輸出給ElasticSearch,然後訪問n1節點的Kibana,配置索引模式構建索引。在Nginx被訪問後會自動生成:
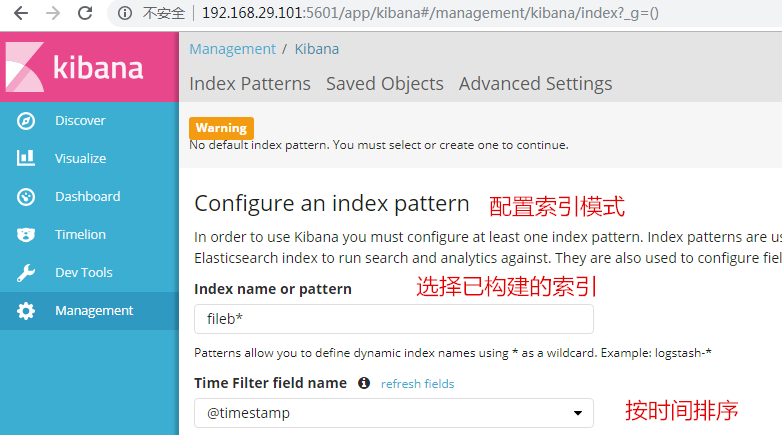
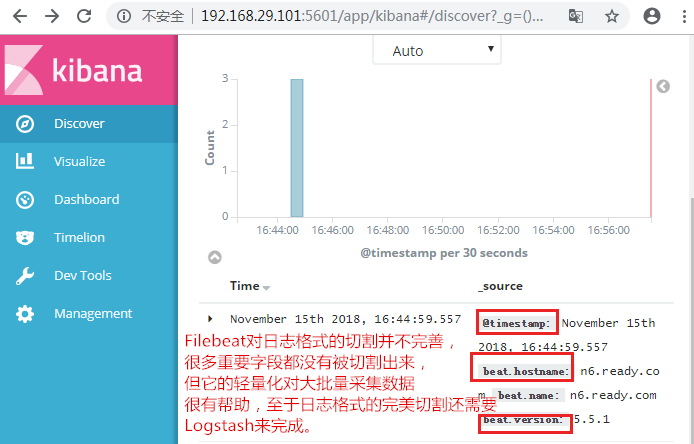
4.安裝並配置Logstash
在n5節點上安裝Logstash,Logstash的執行依賴JDK環境,所以也需要安裝JDK:
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel rpm -ivh logstash-5.5.1.rpm
Logstash的元件結構分為輸入元件(Input plugin)、輸出元件(Output plugin)、過濾元件(Filter plugin),圖示:
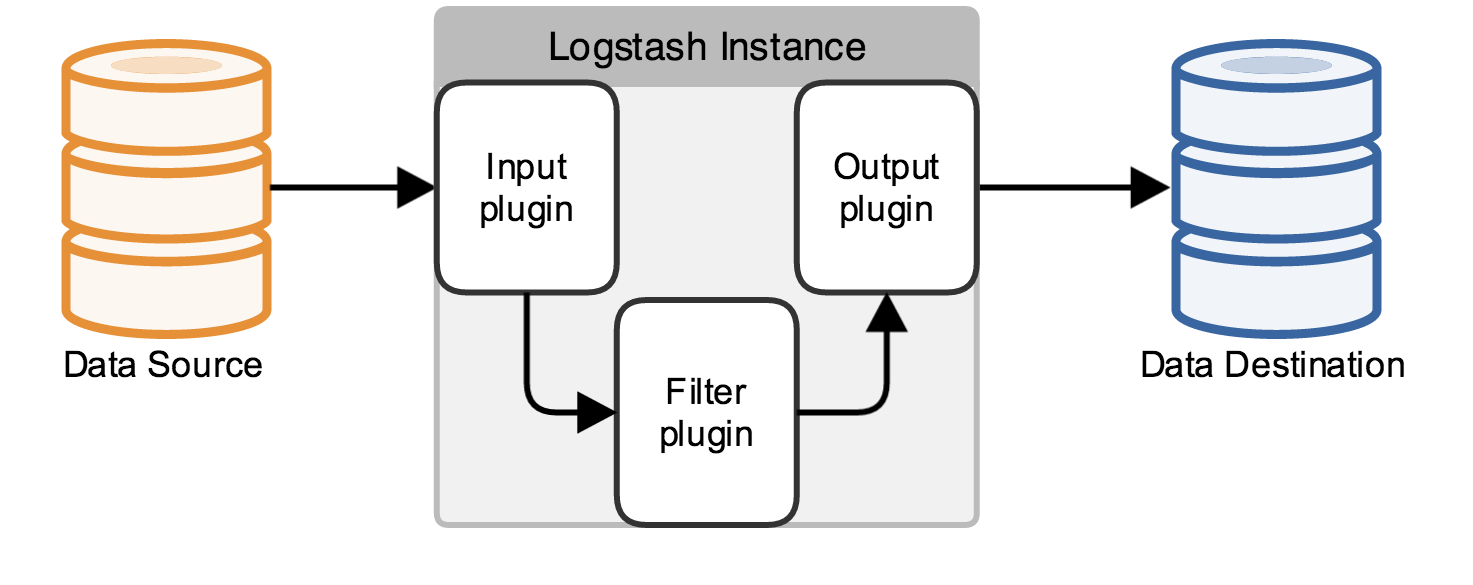
測試Logstash是否能正常執行時,為避免與root發生許可權衝突,需要切換至logstash使用者嘗試啟動Logstash:
su - logstash -s /bin/bash
主配置檔案為: /etc/logstash/logstash.yml ,基本上不需要做修改,但要修改n6節點上的Filebeat配置檔案,將Filebeat的輸出從ElasticSearch修改成向Logstash輸出:
#----------------------------- Logstash output -------------------------------- output.logstash: # The Logstash hosts #hosts: ["localhost:5044"] hosts: ["n5:5044"]View Code
在n5節點上編寫Logstash過濾模組:
1 input { #定義資料輸入來源,這裡定義的是從Filebeat輸入 2 beats { 3 host => '0.0.0.0' #監聽地址 4 port => 5044 5 } 6 } 7 filter { #過濾模組,將輸入的資料按某種定義的格式做處理切割 8 grok { #由grok模組來過濾 9 match => { 10 "message" => "%{IPORHOST:clientip}" #切割源message的格式 11 } 12 } 13 } 14 15 output { #將過濾後的資料輸出到ElasticSearch 16 elasticsearch { 17 hosts => ["n2:9200","n2:9200","n2:9200"] 18 index => "logstash-nginxlog-%{+YYYY.MM.dd}" 19 } 20 }View Code
在Kibana上重新查詢便能看出已經將 clientip 切割出來了,這種的切割功能用Filebeat是沒辦法實現的:
