
深入理解mysql資料庫B+樹索引
索引的作用:
首先索引通俗來講就像書的目錄,通過索引可以快速查詢對應資料,但這僅僅是表面上的,索引主要作用有3點,這僅僅算作其中1點。以下是鄙人的理解:
- 通過索引可以減少資料的掃描量(例如上面提到的將全書掃描,變成了根據目錄找)
- 索引可以把對硬碟的隨機IO變為順序IO()
- 索引可以在排序、分組等操作時避免建立臨時表()
詳細展開來:
mysql資料庫索引的資料結構是B+樹。什麼是B+樹?
如果不是很瞭解樹的同學可以來到這裡視覺化構建樹,選擇對應的資料結構就可以了,我這裡的動圖也是從這來的。
上面部落格中對樹的概念講的比較詳細了,下面補充一下關於索引的選擇,mysql為什麼選擇B+樹(推薦與上面兩個連結一起閱讀):
為什麼不用簡單的二叉樹:
二叉樹存在著這麼樣一個弊端:在極端情況,他會成為一個連結串列,導致效能急劇下降。特製作一動圖供大家更好的理解:

從動圖中可以看出,如果資料完全順序插入(比如索引的主鍵開啟了自增)會導致成為一個連結串列一樣的資料結構,查詢時候有可能演變為全表掃描,查詢動圖如下:

於是我們想把它優化一下,調整為平衡一點的二叉樹(葉子節點的高度差<=1)
平衡二叉樹動圖:

為什麼不使用平衡二叉樹(二路平衡查詢樹):
我們知道資料庫中是儲存資料的,資料量經常會達到百萬以上的級別,這時候的平衡二叉樹雖然解決了二叉樹的極限情況,但對於大資料來講,他的高度可能成百上千高度。
這裡補充一下資料庫有索引時查詢資料的過程:
mspaint畫了個簡單的圖片,如果用平衡二叉樹儲存,假設主鍵索引儲存如下圖

如果要找主鍵為13的資料,需要把10經過磁碟IO讀到記憶體中,來對比,發現13>10,然後根據10的right值再進行一次IO拿到22,,對比發現13<22,然後根據22的left值再進行一次IO拿到13,發現13==13,則拿到4080,再從硬碟去讀。
這是軟體的過程,但我們知道,計算機底層是磁碟,磁碟IO是非常耗費時間的,而磁碟讀的時候一般是讀取4k的資料,我們一次IO讀取了4k資料(4k這裡大家自行補充硬體知識,玩過固態硬碟的朋友都知道4k應該,不知道的朋友自行百度,
總結平衡二叉樹不能作為索引的兩個主要原因:
- 高度太高 導致IO次數太多
- 單節點儲存的資料個數太少 導致IO次數變多
解釋:不能很好地利用磁碟特性(一次讀4k ),也沒有利用到磁碟的預讀(關於磁碟IO點這裡)
如果我們一次磁碟IO可以獲得多個索引的值,那效率就大大提高了,於是來到了B樹(多路平衡查詢樹)的概念。
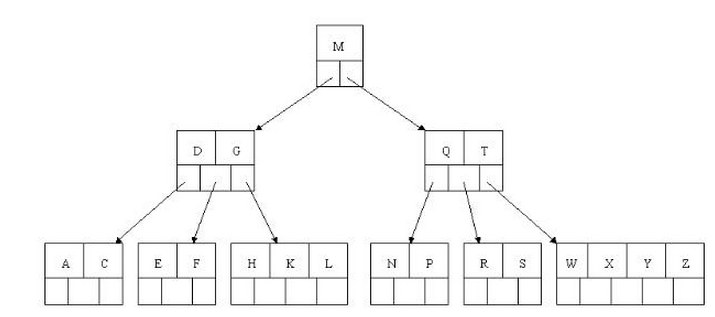
(圖片來自部落格,圖僅供參考)
如果用B樹儲存A-Z則只需要3層即可,而平衡二叉樹則需要6層,這樣就減少了一般的IO次數,查詢效率翻倍
為什麼不用B樹(多路平衡查詢樹)
B樹相比平衡二叉樹大大減少了高度,也增加了單個節點上的數量,看起來已經非常不錯了,是的,但我們資料庫select操作時,很多時候不是select一條資料,而是多條資料,引來了B+樹的概念,如下
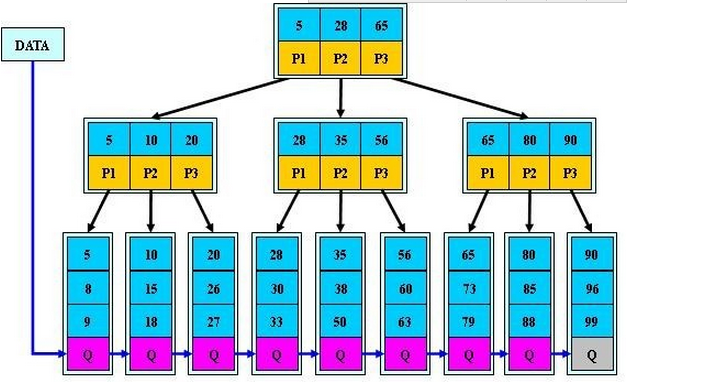
(圖片來源部落格)
B+樹和B樹相比,所有的資料只存在於葉子節點中,非葉子節點不儲存資料,且所有葉子節點為順序連結串列,以便掃描。
B樹的節點中存放了一定資料,B+樹的查詢區間為左閉右開區間,如上圖中查詢索引值為5的資料時,在根節點有三個區間:[5,28)[28,65)[65,∞),第一個區間包含5,但是非葉子節點不儲存資料地址,繼續往左找,來到[5,10)[10,20)[20,∞),繼續往左找來到葉子節點,發現有5,則找到。
B+樹對比B樹的優勢有:
- 擁有B樹的優勢
- 由於葉子節點的連結串列,掃表能力更強
- 節點的結構不同,磁碟讀寫能力更強
- 每次查詢都會來到葉子節點,磁碟IO時間固定,查詢效率穩定,準確統計和排查系統問題
- 排序能力更好
當然這些好處不是白來的,而是犧牲了不穩定的快速查詢(比如上述查詢5的例子提到的,B樹在根節點就返回了,而B+樹無論什麼索引值,都一定要到葉子節點才返回),但同樣因為這兒,也會能夠更準確統計和排查系統問題 。