
如何看待Pensieve:MIT基於神經網路的流媒體位元速率自適應策略(周超)
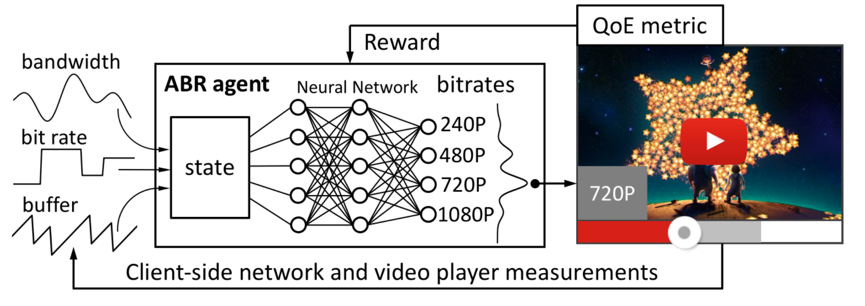
寫在前面
今年的SIGCOMM上, MIT CSAIL的一支研究團隊,發表了一篇名為Pensieve的工作,即利用神經網路優化位元速率自適應演算法,用於提高媒體傳輸質量。文章結果表明:與一般的state-of-the-art 方法相比,Pensieve能平均提升QoE高達12%–25%。之所以介紹這篇文章,基於以下幾方面的原因:一是自己從事流媒體傳輸優化的研究多年,也小有成果,對這類研究自然非常感興趣;二是文章的思路,在2015年時自己曾想過,只是當時既沒有實際需求要深入,也因為確實遇到一些問題不知如何解決(沒有資料集),也就不了了之,這次看到這個文章,自然眼前一亮;三是這個工作是一個很好的引子,給出瞭如何將當前熱的發紫的深度學習,用於流媒體傳輸優化上,先不管其是否完美(research永無止境,沒有完美的),起碼開了一個好頭,有興趣的同行,深入下去應該也能有所小成。此外,該文的一作和其團隊還是非常牛的,當別人還在因為中了個mm、infocom就覺得多牛時,他們團隊在sigcomm, mobicom上跟玩一樣,而且非常務實,基本每篇文章都把程式碼放出來,慚愧~
在閱讀之前,建議熟悉下DASH(Dynamic Additive Streaming over HTTP)或NN(Neural Network)的基本概念和原理,不然有的概念估計不好理解。
開始正題
以下分四個部分介紹下Pensieve:Motivation,Dataset,Network,Results
1、Motivation
Pensieve的動機,即解決傳統位元速率自適應方法面臨的兩大難題:複雜多變的網路環境和QoE指標。
舉例說明,如下圖,其中MPC (Model Predictive Control)是卡內基梅隆大學根據網路變化進行預測優化的位元速率自適應策略,robustMPC則是他的改良版本。
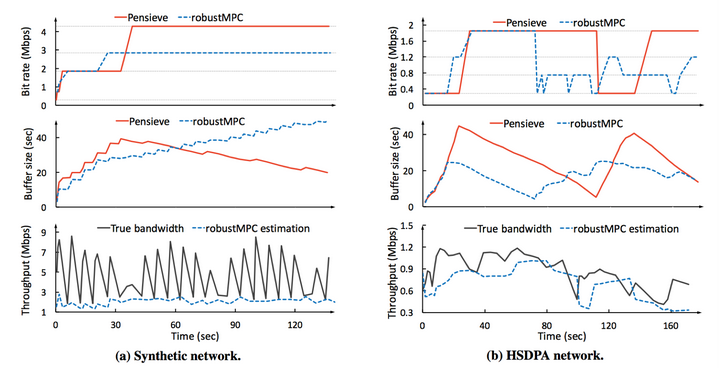
在圖(a)中,頻寬波動劇烈,robustMPC一直較為保守的估計頻寬,導致其頻寬利用率低,不敢請求大位元速率的視訊,而Pensieve則不同,通過buffer來補償頻寬的波動,從而獲得較大的視訊位元速率。圖(b)中,展示了另一個極端例子,即使用者極端的偏好高位元速率,一般的演算法(這裡以robustMPC為例)難以適應使用者的這種需求(個人覺得單獨設計完全也可以達到,只是不夠現實,不可能為每個人每個指標量身定製一套QoE模型),而Pensieve則能自適應的通過低位元速率來攢夠buffer,然後用buffer來補償頻寬,從而請求最大位元速率。這裡僅僅是兩個例子,主要想說明的問題是:state-of-the-art類的策略,一般都是既定策略,難以適應複雜多變的網路和QoE需求,而Pensieve是通過神經網路自我學習,從而達到自適應的目的。
2、Dataset
無資料何來學習,該文通過模擬獲取資料集(早期自己就因為沒有資料集,因此沒有深入下去)
實際通過視訊下載,記錄真實網路狀態獲取資料集,自然是最合理的,但是這樣會特別費時費力,而且真實網路波動厲害,基本不具有可重現性,因此資料集的清洗和普適性也很難把握。因此,該工作通過模擬,獲取各個chunk下載前後的狀態,包括下載時長、頻寬、buffer等等。模擬的網路會過於理想,是否能真的反應真實網路環境,有待商榷。不過慶幸的事,最後作者通過實驗在真實環境進行了一些測試,說明了模型還是挺靈活有效的。
3、Network
先上圖,分三部分,從左到右,依次為輸入、模型處理、輸出
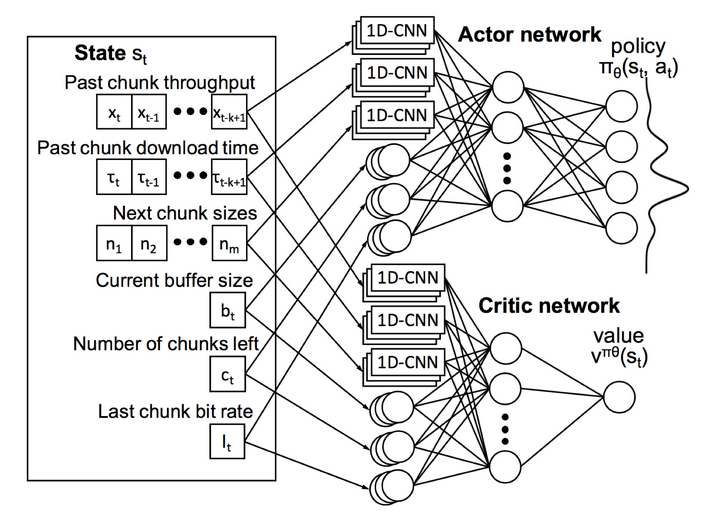
模型的輸入:即狀態資訊,包括:chunk throughput vector(下載每個片段的平均位元速率),chunk download time vector(下載每個片段所花的時間),next chunk size vector(可選chunk的大小,即可用位元速率集合),buffer size(當前buffer),chunks left(剩餘未下載的片段數量),last chunk bit-rate(上一個請求片段的位元速率)。
工作流程:在給定上述狀態S時,執行操作A,從而得到結果B,即輸出下一個片段的位元速率,此時狀態從S遷移到S’,如此迴圈。整個過程是不是覺得很眼熟,沒錯,馬爾科夫決策的基本步驟,本人的一篇best paper http://ieeexplore.ieee.org/document/7457843/,採用的就用馬爾科夫決策來解決DASH中的ABR問題,具體的細節可以看擴充套件後的長文 http://ieeexplore.ieee.org/document/7393865/,發表在Trans. Multimedia上。不過,在傳統馬爾科夫決策中,轉移概率矩陣、代價函式等都是事先分析好的,整個系統按照既定規則運轉。而在Pensieve中,代價函式、決策模型等是通過資料訓練出來的,按照作者的觀點,其適應性會更強。
值得注意的是,上圖中包含兩個網路模型,一個是Actor,一個是Critic,其中Critic主要是訓練cost function的,類似馬爾科夫決策中的代價函式,用於輔助Actor網路,Actor是真正的決策模型,輸出下一個片段的位元速率。
模型引數細節:Actor網路,對於前三個vector,利用滑動視窗,取8個歷史值組成一個vector作為輸入,分別經過一個1*4的一維卷積網路,該網路具有128個filters,後三個因素,則取當前狀態值,經過一個1*1的卷積網路,將所有的輸出經過一個全連層得到一個1*128的vector,最後經過softmax進行判決,得到一個vector,描述了不同位元速率被選中的概率。Critic網路與Actor基本一致,不同的是最後的輸出是一個單值,而不是一個vector。
4、Results
學術論文的結果都是非常好的,不然也不會放在論文上,這一般需要讀者有自己的判斷能力。這篇文章的實驗還是非常完善的,從各個維度都進行了詳細的說明和比較,這裡只選擇幾個結果簡單說明,具體的可以參見論文字身 http://web.mit.edu/pensieve/content/pensieve-sigcomm17.pdf
首先要提一下的是其QoE model,其QoE模型如下:
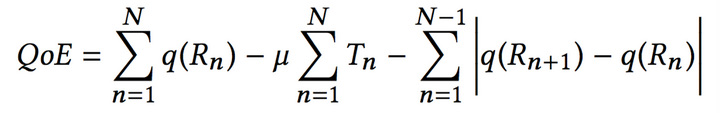
即考慮了位元速率大小、卡頓、位元速率平滑性三個方面,其中,針對其中第一項,即位元速率的大小,又分為如下幾個case:

總體來說,該模型還是比較簡單的,而且在某種程度上,不能真正的反應流媒體傳輸的質量(目前這個領域的研究工作很多,但是流媒體主觀質量這個問題,基本誰都能說自己是對的,也都不對,依據場景需求建立最合適的model,才是最實際的)。最開始我以為該文解決了流媒體領域的這一大難題,即如何定義一個靠譜的QoE模型,然而到最後,還是比較失望的,因為該文章的需要針對不同的QoE模型,訓練不同的network,也就是在QoE上,並沒有任何的創新突破。
以下是分別在FCC和HSDPA兩個資料集上的QoE結果和CDF,可以看出,Pensieve的優勢還是很明顯的。
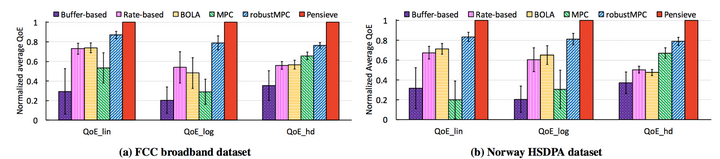
QoE performance over FCC & HSDPA
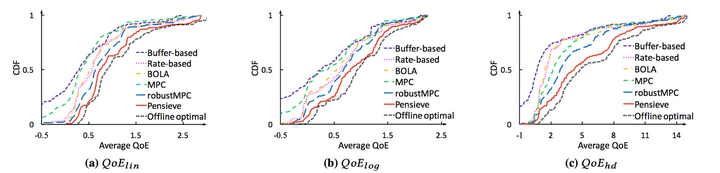
CDF Performance over FCC dataset
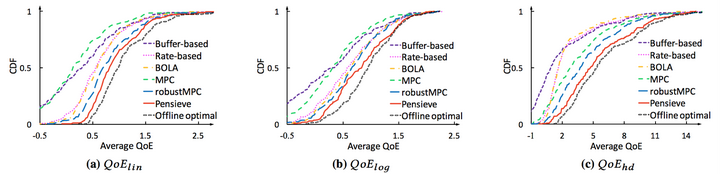
CDF Performance over HSDPA dataset
最後的一張圖比較有意思,該圖說和Offline optimal(知道未來網路狀態,做全域性優化,這個實際不可能提前知道,所有隻是為了實驗比較),效能僅僅相差9.1%,但是和Online optimal相比,效能只相差0.2%,某種程度上是在說,哥要麼不出手,出手就基本已經做到最優了,你們不用再多想了,對於這點,不做評論,大家自己去腦洞。
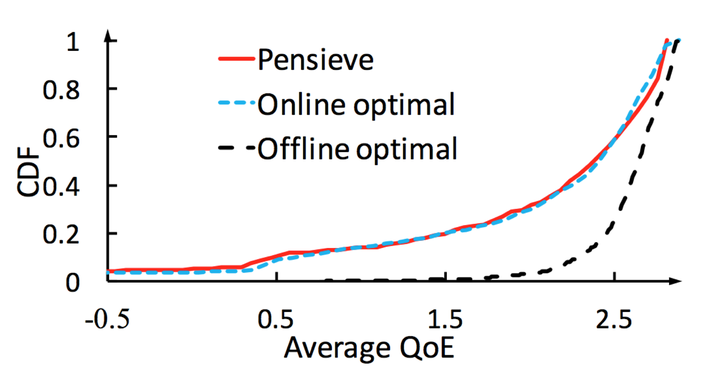
寫在最後
這篇文章無疑是一篇經典,一方面因為他的效能,但我覺得更多的是開闢了一個思路,雖然該思路在以前的文章有很多影子,但是這算是第一個這麼完善的給做出來了 https://github.com/hongzimao/pensieve。當然,還有一些問題,也是值得同行們一起去研究和探討的(個人觀點,不代表權威),例如:
1、基於學習的model,其靈活性較高,但與針對特性場景設計的algorithm相比,其效能是否也能較好,畢竟實際系統都是有特定應用場景的
2、模擬生成的資料集,肯定無法反應真實網路的所有case,如何更好的構建資料集,是一個大難點
3、QoE model,如果更靈活,而不用分別train,可以考慮。畢竟,千人千面最難,在給定QoE model的前提下,整個問題的挑戰也就沒那麼大了。
4、網路結構非常簡單,複雜的結構會怎樣(作者做了很多實驗,包括網路深度、資料集的視窗大小等)?例如什麼CNN、ResNet、DenseNet之類的(需要這麼複雜的網路麼,我也不知道,純屬腦洞)
5、流媒體傳輸的其他方向能否也採用learning的方法,例如jscc、uep等