
python學習第37天GIL鎖、死鎖現象與遞歸鎖、信號量、Event時間、線程queue
一、GIL鎖
1. 什麽是GIL全局解釋器鎖
定義: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)‘‘‘ 結論:在Cpython解釋器中,同一個進程下開啟的多線程,同一時刻只能有一個線程執行,無法利用多核優勢
GIL本質就是一把互斥鎖,相當於執行權限,每個進程內都會存在一把GIL,同一進程內的多個線程
必須搶到GIL之後才能使用Cpython解釋器來執行自己的代碼,即同一進程下的多個線程無法實現並行
但是可以實現並發
在Cpython解釋器下,如果想實現並行可以開啟多個進程
2. 為何要有GIL
因為Cpython解釋器的垃圾回收機制不是線程安全的
原理:如果多個線程的target=work,那麽執行流程是
多個線程先訪問到解釋器的代碼,即拿到執行權限,然後將target的代碼交給解釋器的代碼去執行
解釋器的代碼是所有線程共享的,所以垃圾回收線程也可能訪問到解釋器的代碼而去執行,這就導致了一個問題:對於同一個數據100,可能線程1執行x=100的同時,而垃圾回收執行的是回收100的操作,解決這種問題沒有什麽高明的方法,就是加鎖處理,如下圖的GIL,保證python解釋器同一時間只能執行一個任務的代碼
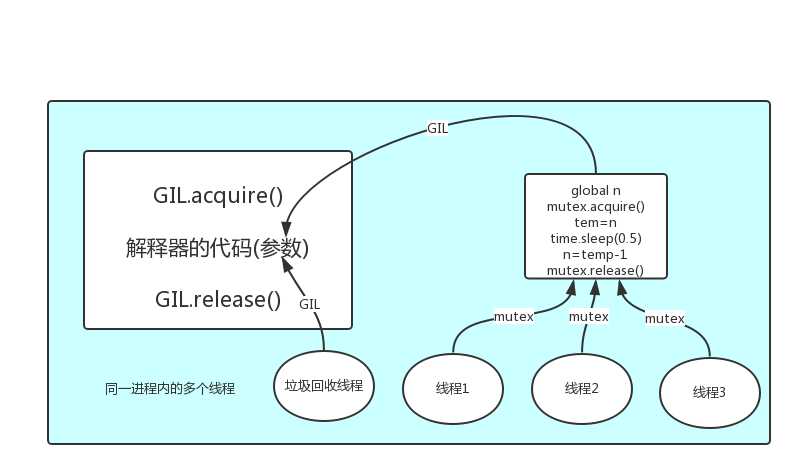
3. 如何用GIL
有了GIL,應該如何處理並發
首先需要明確的一點是GIL並不是Python的特性,它是在實現Python解析器(CPython)時所引入的一個概念。就好比C++是一套語言(語法)標準,但是可以用不同的編譯器來編譯成可執行代碼。有名的編譯器例如GCC,INTEL C++,Visual C++等。Python也一樣,同樣一段代碼可以通過CPython,PyPy,Psyco等不同的Python執行環境來執行。像其中的JPython就沒有GIL。然而因為CPython是大部分環境下默認的Python執行環境。所以在很多人的概念裏CPython就是Python,也就想當然的把GIL
有了GIL的存在,同一時刻同一進程中只有一個線程被執行
聽到這裏,有的同學立馬質問:進程可以利用多核,但是開銷大,而python的多線程開銷小,但卻無法利用多核優勢,也就是說python沒用了,php才是最牛逼的語言?
別著急啊,老娘還沒講完呢。
要解決這個問題,我們需要在幾個點上達成一致:
#1. cpu到底是用來做計算的,還是用來做I/O的? #2. 多cpu,意味著可以有多個核並行完成計算,所以多核提升的是計算性能 #3. 每個cpu一旦遇到I/O阻塞,仍然需要等待,所以多核對I/O操作沒什麽用處
一個工人相當於cpu,此時計算相當於工人在幹活,I/O阻塞相當於為工人幹活提供所需原材料的過程,工人幹活的過程中如果沒有原材料了,則工人幹活的過程需要停止,直到等待原材料的到來。
如果你的工廠幹的大多數任務都要有準備原材料的過程(I/O密集型),那麽你有再多的工人,意義也不大,還不如一個人,在等材料的過程中讓工人去幹別的活,
反過來講,如果你的工廠原材料都齊全,那當然是工人越多,效率越高
結論:
對計算來說,cpu越多越好,但是對於I/O來說,再多的cpu也沒用
當然對運行一個程序來說,隨著cpu的增多執行效率肯定會有所提高(不管提高幅度多大,總會有所提高),這是因為一個程序基本上不會是純計算或者純I/O,所以我們只能相對的去看一個程序到底是計算密集型還是I/O密集型,從而進一步分析python的多線程到底有無用武之地
分析: 我們有四個任務需要處理,處理方式肯定是要玩出並發的效果,解決方案可以是: 方案一:開啟四個進程 方案二:一個進程下,開啟四個線程 #單核情況下,分析結果: 如果四個任務是計算密集型,沒有多核來並行計算,方案一徒增了創建進程的開銷,方案二勝 如果四個任務是I/O密集型,方案一創建進程的開銷大,且進程的切換速度遠不如線程,方案二勝 #多核情況下,分析結果: 如果四個任務是計算密集型,多核意味著並行計算,在python中一個進程中同一時刻只有一個線程執行用不上多核,方案一勝 如果四個任務是I/O密集型,再多的核也解決不了I/O問題,方案二勝 #結論:現在的計算機基本上都是多核,python對於計算密集型的任務開多線程的效率並不能帶來多大性能上的提升,甚至不如串行(沒有大量切換),但是,對於IO密集型的任務效率還是有顯著提升的。 復制代碼
計算密集型:應該使用多進程 # from multiprocessing import Process # from threading import Thread # import os,time # # def work(): # res=0 # for i in range(100000000): # res*=i # # if __name__ == ‘__main__‘: # l=[] # print(os.cpu_count()) # start=time.time() # for i in range(6): # # p=Process(target=work) # p=Thread(target=work) # l.append(p) # p.start() # for p in l: # p.join() # stop=time.time() # print(‘run time is %s‘ %(stop-start)) #4.271663427352905
# IO密集型: 應該開啟多線程
from multiprocessing import Process from threading import Thread import threading import os,time def work(): time.sleep(2) if __name__ == ‘__main__‘: l=[] start=time.time() for i in range(300): # p=Process(target=work) #2.225289821624756 p=Thread(target=work) #2.002105951309204 l.append(p) p.start() for p in l: p.join() stop=time.time() print(‘run time is %s‘ %(stop-start))
4、GIL與自定義互斥鎖
機智的同學可能會問到這個問題,就是既然你之前說過了,Python已經有一個GIL來保證同一時間只能有一個線程來執行了,為什麽這裏還需要lock?
首先我們需要達成共識:鎖的目的是為了保護共享的數據,同一時間只能有一個線程來修改共享的數據
然後,我們可以得出結論:保護不同的數據就應該加不同的鎖。
最後,問題就很明朗了,GIL 與Lock是兩把鎖,保護的數據不一樣,前者是解釋器級別的(當然保護的就是解釋器級別的數據,比如垃圾回收的數據),後者是保護用戶自己開發的應用程序的數據,很明顯GIL不負責這件事,只能用戶自定義加鎖處理,即Lock
過程分析:所有線程搶的是GIL鎖,或者說所有線程搶的是執行權限
線程1搶到GIL鎖,拿到執行權限,開始執行,然後加了一把Lock,還沒有執行完畢,即線程1還未釋放Lock,有可能線程2搶到GIL鎖,開始執行,執行過程中發現Lock還沒有被線程1釋放,於是線程2進入阻塞,被奪走執行權限,有可能線程1拿到GIL,然後正常執行到釋放Lock。。。這就導致了串行運行的效果
既然是串行,那我們執行
t1.start()
t1.join
t2.start()
t2.join()
這也是串行執行啊,為何還要加Lock呢,需知join是等待t1所有的代碼執行完,相當於鎖住了t1的所有代碼,而Lock只是鎖住一部分操作共享數據的代碼。
from threading import Thread,Lock import time mutex=Lock() n=100 def task(): global n with mutex: temp=n time.sleep(0.1) n=temp-1 if __name__ == ‘__main__‘: l=[] for i in range(100): t=Thread(target=task) l.append(t) t.start() for t in l: t.join() print(n)#結果可能是99,代碼運行順序錯亂
加了互斥鎖後
from threading import Thread,Lock import os,time def work(): global n lock.acquire() temp=n time.sleep(0.1) n=temp-1 lock.release() if __name__ == ‘__main__‘: lock=Lock() n=100 l=[] for i in range(100): p=Thread(target=work) l.append(p) p.start() for p in l: p.join() print(n) #結果肯定為0,由原來的並發執行變成串行,犧牲了執行效率保證了數據安全 復制代碼
分析:
#1.100個線程去搶GIL鎖,即搶執行權限
#2. 肯定有一個線程先搶到GIL(暫且稱為線程1),然後開始執行,一旦執行就會拿到lock.acquire()
#3. 極有可能線程1還未運行完畢,就有另外一個線程2搶到GIL,然後開始運行,但線程2發現互斥鎖lock還未被線程1釋放,於是阻塞,被迫交出執行權限,即釋放GIL
#4.直到線程1重新搶到GIL,開始從上次暫停的位置繼續執行,直到正常釋放互斥鎖lock,然後其他的線程再重復2 3 4的過程
比較2個運行的時間
#不加鎖:並發執行,速度快,數據不安全 from threading import current_thread,Thread,Lock import os,time def task(): global n print(‘%s is running‘ %current_thread().getName()) temp=n time.sleep(0.5) n=temp-1 if __name__ == ‘__main__‘: n=100 lock=Lock() threads=[] start_time=time.time() for i in range(100): t=Thread(target=task) threads.append(t) t.start() for t in threads: t.join() stop_time=time.time() print(‘主:%s n:%s‘ %(stop_time-start_time,n)) ‘‘‘ Thread-1 is running Thread-2 is running ...... Thread-100 is running 主:0.5216062068939209 n:99 ‘‘‘
#不加鎖:未加鎖部分並發執行,加鎖部分串行執行,速度慢,數據安全 from threading import current_thread,Thread,Lock import os,time def task(): #未加鎖的代碼並發運行 time.sleep(3) print(‘%s start to run‘ %current_thread().getName()) global n #加鎖的代碼串行運行 lock.acquire() temp=n time.sleep(0.5) n=temp-1 lock.release() if __name__ == ‘__main__‘: n=100 lock=Lock() threads=[] start_time=time.time() for i in range(100): t=Thread(target=task) threads.append(t) t.start() for t in threads: t.join() stop_time=time.time() print(‘主:%s n:%s‘ %(stop_time-start_time,n)) ‘‘‘ Thread-1 is running Thread-2 is running ...... Thread-100 is running 主:53.294203758239746 n:0 ‘‘‘
#有的同學可能有疑問:既然加鎖會讓運行變成串行,那麽我在start之後立即使用join,就不用加鎖了啊,也是串行的效果啊 #沒錯:在start之後立刻使用jion,肯定會將100個任務的執行變成串行,毫無疑問,最終n的結果也肯定是0,是安全的,但問題是 #start後立即join:任務內的所有代碼都是串行執行的,而加鎖,只是加鎖的部分即修改共享數據的部分是串行的 #單從保證數據安全方面,二者都可以實現,但很明顯是加鎖的效率更高. from threading import current_thread,Thread,Lock import os,time def task(): time.sleep(3) print(‘%s start to run‘ %current_thread().getName()) global n temp=n time.sleep(0.5) n=temp-1 if __name__ == ‘__main__‘: n=100 lock=Lock() start_time=time.time() for i in range(100): t=Thread(target=task) t.start() t.join() stop_time=time.time() print(‘主:%s n:%s‘ %(stop_time-start_time,n)) ‘‘‘ Thread-1 start to run Thread-2 start to run ...... Thread-100 start to run 主:350.6937336921692 n:0 #耗時是多麽的恐怖 ‘‘‘
二、死鎖與遞歸鎖
進程也有死鎖與遞歸鎖,在進程那裏忘記說了,放到這裏一切說了額
所謂死鎖: 是指兩個或兩個以上的進程或線程在執行過程中,因爭奪資源而造成的一種互相等待的現象,若無外力作用,它們都將無法推進下去。此時稱系統處於死鎖狀態或系統產生了死鎖,這些永遠在互相等待的進程稱為死鎖進程,如下就是死鎖
復制代碼 from threading import Thread,Lock import time mutexA=Lock() mutexB=Lock() class MyThread(Thread): def run(self): self.func1() self.func2() def func1(self): mutexA.acquire() print(‘\033[41m%s 拿到A鎖\033[0m‘ %self.name) mutexB.acquire() print(‘\033[42m%s 拿到B鎖\033[0m‘ %self.name) mutexB.release() mutexA.release() def func2(self): mutexB.acquire() print(‘\033[43m%s 拿到B鎖\033[0m‘ %self.name) time.sleep(2) mutexA.acquire() print(‘\033[44m%s 拿到A鎖\033[0m‘ %self.name) mutexA.release() mutexB.release() if __name__ == ‘__main__‘: for i in range(10): t=MyThread() t.start() ‘‘‘ Thread-1 拿到A鎖 Thread-1 拿到B鎖 Thread-1 拿到B鎖 Thread-2 拿到A鎖 然後就卡住,死鎖了
好比甲在房間一拿了房間 二的鑰匙被鎖在房間一裏,乙在房間二拿了房間 一的鑰匙被鎖在房間二裏
解決方式:可以把房間一和房間二的鑰匙設置成通用鑰匙,程序裏就用了叫遞歸鎖
遞歸鎖,在Python中為了支持在同一線程中多次請求同一資源,python提供了可重入鎖RLock。
這個RLock內部維護著一個Lock和一個counter變量,counter記錄了acquire的次數,從而使得資源可以被多次require。直到一個線程所有的acquire都被release,其他的線程才能獲得資源。上面的例子如果使用RLock代替Lock,則不會發生死鎖:
from threading import Thread,Lock,RLock import time # mutexA=Lock() # mutexB=Lock() mutexB=mutexA=RLock() class Mythead(Thread): def run(self): self.f1() self.f2() def f1(self): mutexA.acquire() print(‘%s 搶到A鎖‘ %self.name) mutexB.acquire() print(‘%s 搶到B鎖‘ %self.name) mutexB.release() mutexA.release() def f2(self): mutexB.acquire() print(‘%s 搶到了B鎖‘ %self.name) time.sleep(2) mutexA.acquire() print(‘%s 搶到了A鎖‘ %self.name) mutexA.release() mutexB.release() if __name__ == ‘__main__‘: for i in range(100): t=Mythead() t.start()
三、信號量
同進程的一樣
Semaphore管理一個內置的計數器,
每當調用acquire()時內置計數器-1;
調用release() 時內置計數器+1;
計數器不能小於0;當計數器為0時,acquire()將阻塞線程直到其他線程調用release()。
實例:(同時只有5個線程可以獲得semaphore,即可以限制最大連接數為5):
from threading import Thread,Semaphore import threading import time # def func(): # if sm.acquire(): # print (threading.currentThread().getName() + ‘ get semaphore‘) # time.sleep(2) # sm.release() def func(): sm.acquire() print(‘%s get sm‘ %threading.current_thread().getName()) time.sleep(3) sm.release() if __name__ == ‘__main__‘: sm=Semaphore(5) for i in range(23): t=Thread(target=func) t.start()
與進程池是完全不同的概念,進程池Pool(4),最大只能產生4個進程,而且從頭到尾都只是這四個進程,不會產生新的,而信號量是產生一堆線程/進程
四、Event事件
同進程的一樣
線程的一個關鍵特性是每個線程都是獨立運行且狀態不可預測。如果程序中的其 他線程需要通過判斷某個線程的狀態來確定自己下一步的操作,這時線程同步問題就會變得非常棘手。為了解決這些問題,我們需要使用threading庫中的Event對象。 對象包含一個可由線程設置的信號標誌,它允許線程等待某些事件的發生。在 初始情況下,Event對象中的信號標誌被設置為假。如果有線程等待一個Event對象, 而這個Event對象的標誌為假,那麽這個線程將會被一直阻塞直至該標誌為真。一個線程如果將一個Event對象的信號標誌設置為真,它將喚醒所有等待這個Event對象的線程。如果一個線程等待一個已經被設置為真的Event對象,那麽它將忽略這個事件, 繼續執行
event.isSet():返回event的狀態值; event.wait():如果 event.isSet()==False將阻塞線程; event.set(): 設置event的狀態值為True,所有阻塞池的線程激活進入就緒狀態, 等待操作系統調度; event.clear():恢復event的狀態值為False。

例如,有多個工作線程嘗試鏈接MySQL,我們想要在鏈接前確保MySQL服務正常才讓那些工作線程去連接MySQL服務器,如果連接不成功,都會去嘗試重新連接。那麽我們就可以采用threading.Event機制來協調各個工作線程的連接操作
from threading import Thread,Event import threading import time,random def conn_mysql(): count=1 while not event.is_set(): if count > 3: raise TimeoutError(‘鏈接超時‘) print(‘<%s>第%s次嘗試鏈接‘ % (threading.current_thread().getName(), count)) event.wait(0.5) count+=1 print(‘<%s>鏈接成功‘ %threading.current_thread().getName()) def check_mysql(): print(‘\033[45m[%s]正在檢查mysql\033[0m‘ % threading.current_thread().getName()) time.sleep(random.randint(2,4)) event.set() if __name__ == ‘__main__‘: event=Event() conn1=Thread(target=conn_mysql) conn2=Thread(target=conn_mysql) check=Thread(target=check_mysql) conn1.start() conn2.start() check.start() 復制代碼
五、線程queue
import queue # queue.Queue() #先進先出 # q=queue.Queue(3) # q.put(1) # q.put(2) # q.put(3) # print(q.get()) # print(q.get()) # print(q.get()) # queue.LifoQueue() #後進先出->堆棧 # q=queue.LifoQueue(3) # q.put(1) # q.put(2) # q.put(3) # print(q.get()) # print(q.get()) # print(q.get()) # queue.PriorityQueue() #優先級 q=queue.PriorityQueue(3) #優先級,優先級用數字表示,數字越小優先級越高 q.put((10,‘a‘)) q.put((-1,‘b‘)) q.put((100,‘c‘)) print(q.get()) print(q.get()) print(q.get())
python學習第37天GIL鎖、死鎖現象與遞歸鎖、信號量、Event時間、線程queue