
資料庫【三種讀現象】與【四種隔離級別】+MySQL相關命令
資料庫事務特性ACID
資料庫事務特徵,即 ACID:
A Atomicity 原子性
事務是一個原子性質的操作單元,事務裡面的對資料庫的操作要麼都執行,要麼都不執行,
C Consistent 一致性
在事務開始之前和完成之後,資料都必須保持一致狀態,必須保證資料庫的完整性。也就是說,資料必須符合資料庫的規則。
I Isolation 隔離性
資料庫允許多個併發事務同事對資料進行操作,隔離性保證各個事務相互獨立,事務處理時的中間狀態對其它事務是不可見的,以此防止出現數據不一致狀態。可通過事務隔離級別設定:包括讀未提交(Read uncommitted)、讀提交(read committed)、可重複讀(repeatable read)和序列化(Serializable)
D Durable 永續性
一個事務處理結束後,其對資料庫的修改就是永久性的,即使系統故障也不會丟失。
併發控制
併發控制描述了資料庫事務隔離以保證資料正確性的機制。為了保證並行事務執行的準確執行,資料庫和儲存引擎在設計的時候著重強調了併發控制這一點。典型的事務相關機制限制資料的訪問順序(執行排程)以滿足可序列化 和可恢復性。限制資料訪問意味著降低了執行的效能,併發控制機制就是要保證在滿足這些限制的前提下提供儘可能高的效能。經常在不損害正確性的情況下,為了達到更好的效能,可序列化的要求會減低一些,但是為了避免資料一致性的破壞,可恢復性必須保證。
兩階段鎖是關係資料庫中最常見的提供了可序列化和可恢復性的併發控制機制,為了訪問一個數據庫物件,事務首先要獲得這個物件的鎖。對於不同的訪問型別(如對物件的讀寫操作)和鎖的型別,如果另外一個事務正持有這個物件的鎖,獲得鎖的過程會被阻塞或者延遲。
問題產生原因
如果資料庫只提供單人訪問,那麼不會產生這些問題。但是資料庫是給多人訪問的,所以會出現以下幾種不確定的情況。
讀現象舉例
髒讀Dirty reads
髒讀是指在一個事務處理過程裡讀取了另一個未提交事務中的資料。
舉例:事務一、B同時查餘額。事務二向賬戶餘額增加10元,但是提交失敗,導致事務回滾。
| 時間 |
事務一 |
事務二 |
| 1 |
查詢賬戶餘額為100元 |
查詢賬戶餘額為100元 |
| 2 |
增加了10元(此時並沒有commit) |
|
| 3 |
查詢賬戶餘額為110元 |
|
| 4 |
Commit |
Rollback(因某種原因未提交成功) |
最終結果:因為事務二提交失敗,所以賬戶餘額還是100元。但是事務一查詢到未提交的資料,產生了髒讀。
不可重複讀Non-repeatable reads
不可重複讀是指在對於資料庫中的某個資料,一個事務範圍內多次查詢,卻返回了不同的資料值。這是由於在查詢間隔中,資料被另一個事務修改並提交了。
舉例:事務一、B同時查餘額。事務二向賬戶餘額增加10元。並且提交成功
| 時間 |
事務一 |
事務二 |
| 1 |
查詢賬戶餘額為100元 |
查詢賬戶餘額為100元 |
| 2 |
增加了10元 |
|
| 3 |
commit |
|
| 4 |
查詢賬戶餘額為110元 |
|
| 5 |
Commit |
|
事務一在讀取某一資料,而事務二立馬修改了這個資料並且提交事務給資料庫,事務一再次讀取該資料就得到了不同的結果,傳送了不可重複讀。
不可重複讀和髒讀的區別
髒讀是某一事務讀取了另一個事務未提交的髒資料
不可重複讀則是讀取了另一事務已提交的資料。
在某些情況下,不可重複讀並不是問題,比如我們多次查詢某個資料當然以最後查詢得到的結果為主。但在另一些情況下就有可能發生問題,例如對同一個資料,A和B因為查詢時間的不同導致最後讀取的資料結果不同,可能就會產生問題。
幻讀 Phantom reads
| 時間 |
事務一 |
事務二 |
| 1 |
查詢資料個數,共2條資料,id分別為1、2 |
查詢資料個數,共2條資料,id分別為1、2 |
| 2 |
新增一條id=3的資料 Insert into table (id) value (3) |
|
| 3 |
commit |
|
| 4 |
再次查詢資料個數,查到3條資料 |
|
| 5 |
Commit |
|
剛開始A讀資料明明為2條,但是第二次卻查到3條。就像產生了幻覺一樣。
幻讀與不可重複讀的區別
相同點:
兩者都是已提交後的資料。
不同點:
範圍不同:不可重複讀查詢的都是同一個資料項,而幻讀針對的是一批資料整體(比如資料的個數)。
針對行為不同:不可重複讀針對資料的修改造成的讀不一致,而幻讀針對資料的插入和刪除造成的讀不一致,如同發生幻覺一樣。
讀現象解決方案
針對併發事務,要想解決髒讀、不可重複讀、幻讀等讀問題,資料庫系統引入了隔離操作,以保證各個執行緒(事務)獲取資料的準確性。
事務隔離級別
在資料庫事務的ACID四個屬性中,隔離性是一個最常放鬆的一個。為了獲取更高的隔離等級,資料庫系統的鎖機制或者多版本併發控制機制都會影響併發。 應用軟體也需要額外的邏輯來使其正常工作。
很多資料庫管理系統定義了不同的“事務隔離等級”來控制鎖的程度。在很多資料庫系統中,多數的資料庫事務都避免高等級的隔離等級(如可序列化)從而減少對系統的鎖定開銷。程式設計師需要小心的分析資料庫訪問部分的程式碼來保證隔離級別的降低不會造成難以發現的程式碼bug。相反的,更高的隔離級別會增加死鎖發生的機率,同樣需要程式設計過程中去避免。
ANSI/ISO SQL定義的標準隔離級別如下:
隔離級別從低到高
- Read uncommttied未提交讀
- Read committed提交讀
- Repeatable reads可重複讀
- Serializable可序列化
Read uncommttied未提交讀
未提交讀(READ UNCOMMITTED)是最低的隔離級別。通過名字我們就可以知道,在這種事務隔離級別下,一個事務可以讀到另外一個事務未提交的資料。
未提交讀的資料庫鎖情況(實現原理)
事務在讀資料的時候並未對資料加鎖。
務在修改資料的時候只對資料增加行級共享鎖。
現象
事務1讀取某行記錄時,事務2也能對這行記錄進行讀取、更新(因為事務一併未對資料增加任何鎖)
當事務2對該記錄進行更新時,事務1再次讀取該記錄,能讀到事務2對該記錄的修改版本(因為事務二隻增加了共享讀鎖,事務一可以再增加共享讀鎖讀取資料),即使該修改尚未被提交。
事務1更新某行記錄時,事務2不能對這行記錄做更新,直到事務1結束。(因為事務一對資料增加了共享讀鎖,事務二不能增加排他寫鎖進行資料的修改)
舉例
舉例還是舉上面的例子
髒讀例子
| 時間 |
事務一 |
事務二 |
| 1 |
查詢賬戶餘額為100元 |
查詢賬戶餘額為100元 |
| 2 |
增加了10元(此時並沒有commit) |
|
| 3 |
查詢賬戶餘額為110元 |
|
| 4 |
Commit |
Rollback(因某種原因未提交成功) |
事務一一共查詢了兩次。在第二次的查詢過程中,事務二對資料進行了修改,並未提交。
但是事務一讀取到了事務二未提交的內容,這種執行緒稱為髒讀。
所以,未提交讀會導致髒讀
Read committed提交讀
提交讀(READ COMMITTED)也可以翻譯成讀已提交,通過名字也可以分析出,在一個事務修改資料過程中,如果事務還沒提交,其他事務不能讀該資料。
提交讀的資料庫鎖情況
事務對當前被讀取的資料加 行級共享鎖(當讀到時才加鎖),一旦讀完該行,立即釋放該行級共享鎖;
事務在更新某資料的瞬間(就是發生更新的瞬間),必須先對其加 行級排他鎖,直到事務結束才釋放。
現象:
事務1在讀取某行記錄的整個過程中,事務2都可以對該行記錄進行讀取(因為事務一對該行記錄增加行級共享鎖的情況下,事務二同樣可以對該資料增加共享鎖來讀資料。)。
事務1讀取某行的一瞬間,事務2不能修改該行資料,但是,只要事務1讀取完改行資料,事務2就可以對該行資料進行修改。(事務一在讀取的一瞬間會對資料增加共享鎖,任何其他事務都不能對該行資料增加排他鎖。但是事務一隻要讀完該行資料,就會釋放行級共享鎖,一旦鎖釋放,事務二就可以對資料增加排他鎖並修改資料)
事務1更新某行記錄時,事務2不能對這行記錄做更新,直到事務1結束。(事務一在更新資料的時候,會對該行資料增加排他鎖,知道事務結束才會釋放鎖,所以,在事務二沒有提交之前,事務一都能不對資料增加共享鎖進行資料的讀取。所以,提交讀可以解決髒讀的現象)
舉例
不可重複讀例子
| 時間 |
事務一 |
事務二 |
| 1 |
查詢賬戶餘額為100元 |
查詢賬戶餘額為100元 |
| 2 |
增加了10元 |
|
| 3 |
commit |
|
| 4 |
查詢賬戶餘額為110元 |
|
| 5 |
Commit |
|
幻讀例子
| 時間 |
事務一 |
事務二 |
| 1 |
查詢資料個數,共2條資料,id分別為1、2 |
查詢資料個數,共2條資料,id分別為1、2 |
| 2 |
新增一條id=3的資料 Insert into table (id) value (3) |
|
| 3 |
commit |
|
| 4 |
再次查詢資料個數,查到3條資料 |
|
| 5 |
Commit |
|
在提交讀隔離級別中,在事務二提交之前,事務一不能讀取資料。只有在事務二提交之後,事務一才能讀資料。
但是從上面的例子中我們也看到,事務一兩次讀取的結果並不一致,所以提交讀不能解決不可重複讀和幻讀的讀現象。
小結
因為:提交讀這種隔離級別保證了讀到的任何資料都是提交的資料
所以:解決了髒讀問題
但是:不能解決 不可重複讀和幻讀
因為:每次資料讀完之後其他事務可以修改剛才讀到的資料。
Repeatable reads可重複讀
可重複讀(REPEATABLE READS),由於提交讀隔離級別會產生不可重複讀的讀現象。所以,比提交讀更高一個級別的隔離級別就可以解決不可重複讀的問題。這種隔離級別就叫可重複讀(這名字起的是不是很任性!!)
可重複讀的資料庫鎖情況
事務在讀取某資料的瞬間(就是開始讀取的瞬間),必須先對其加 行級共享鎖,直到事務結束才釋放;
事務在更新某資料的瞬間(就是發生更新的瞬間),必須先對其加 行級排他鎖,直到事務結束才釋放。
現象
事務1在讀取某行記錄的整個過程中,事務2都可以對該行記錄進行讀取(因為事務一對該行記錄增加行級共享鎖的情況下,事務二同樣可以對該資料增加共享鎖來讀資料。)。
事務1在讀取某行記錄的整個過程中,事務2都不能修改該行資料(事務一在讀取的整個過程會對資料增加共享鎖,直到事務提交才會釋放鎖,所以整個過程中,任何其他事務都不能對該行資料增加排他鎖。所以,可重複讀能夠解決不可重複讀的讀現象)
事務1更新某行記錄時,事務2不能對這行記錄做更新,直到事務1結束。(事務一在更新資料的時候,會對該行資料增加排他鎖,知道事務結束才會釋放鎖,所以,在事務二沒有提交之前,事務一都能不對資料增加共享鎖進行資料的讀取。所以,提交讀可以解決髒讀的現象)
舉例
不可重複讀例子(在這裡,這個問題已被解決)
| 時間 |
事務一 |
事務二 |
| 1 |
查詢賬戶餘額為100元 |
查詢賬戶餘額為100元 |
| 2 |
Commit |
|
| 3 |
增加了10元 |
|
| 4 |
|
commit |
| 5 |
查詢賬戶餘額為110元 |
|
| 6 |
Commit |
|
在上面的例子中,只有在事務一提交之後,事務二才能更改該行資料。
所以,只要在事務一從開始到結束的這段時間內,無論他讀取該行資料多少次,結果都是一樣的。
從上面的例子中我們可以得到結論:可重複讀隔離級別可以解決不可重複讀的讀現象。
但是可重複讀這種隔離級別中,還有另外一種讀現象他解決不了,那就是幻讀。看下面的幻讀例子:
| 時間 |
事務一 |
事務二 |
| 1 |
查詢資料個數,共2條資料,id分別為1、2 |
查詢資料個數,共2條資料,id分別為1、2 |
| 2 |
新增一條id=3的資料 Insert into table (id) value (3) |
|
| 3 |
commit |
|
| 4 |
再次查詢資料個數,查到3條資料 |
|
| 5 |
Commit |
|
上面的兩個事務執行情況及現象如下:
1.事務一進行查詢操作,查詢資料庫個數,工2條資料。這時,他會給這查詢到的2條資料增加行級共享鎖。任何其他事務無法更改查詢到的這2條記錄。
2.事務二往表中插入一條資料操作。因為此時沒有任何事務對錶增加表級鎖,所以,該操作可以順利執行。
3.事務一再次執行查詢操作,卻查到3條資料,增加的這條正是事務二剛剛插入的那條。
所以,事務一的兩次範圍查詢結果並不相同。這也就是我們提到的幻讀。
Serializable可序列化
可序列化(Serializable)是最高的隔離級別,前面提到的所有的隔離級別都無法解決的幻讀,在可序列化的隔離級別中可以解決。
我們說過,產生幻讀的原因是事務一在進行範圍查詢的時候沒有增加範圍鎖(range-locks:給SELECT 的查詢中使用一個“WHERE”子句描述範圍加鎖),所以導致幻讀。
可序列化的資料庫鎖情況
事務在讀取資料時,必須先對其加 表級共享鎖 ,直到事務結束才釋放;
事務在更新資料時,必須先對其加 表級排他鎖 ,直到事務結束才釋放。
現象
事務1正在讀取A表中的記錄時,則事務2也能讀取A表,但不能對A表做更新、新增、刪除,直到事務1結束。(因為事務一對錶增加了表級共享鎖,其他事務只能增加共享鎖讀取資料,不能進行其他任何操作)
事務1正在更新A表中的記錄時,則事務2不能讀取A表的任意記錄,更不可能對A表做更新、新增、刪除,直到事務1結束。(事務一對錶增加了表級排他鎖,其他事務不能對錶增加共享鎖或排他鎖,也就無法進行任何操作)
雖然可序列化解決了髒讀、不可重複讀、幻讀等讀現象。但是序列化事務會產生以下效果:
1.無法讀取其它事務已修改但未提交的記錄。
2.在當前事務完成之前,其它事務不能修改目前事務已讀取的記錄。
3.在當前事務完成之前,其它事務所插入的新記錄,其索引鍵值不能在當前事務的任何語句所讀取的索引鍵範圍中。
小結
四種事務隔離級別從隔離程度上越來越高,但同時在併發性上也就越來越低。之所以有這麼幾種隔離級別,就是為了方便開發人員在開發過程中根據業務需要選擇最合適的隔離級別。
隔離級別vs讀現象
| 隔離級別 |
髒讀 |
不可重複讀 |
幻讀 |
| 未提交讀Read uncommitted |
可能發生 |
可能發生 |
可能發生 |
| 提交讀Read committed |
- |
可能發生 |
可能發生 |
| 可重複讀Repeatable read |
- |
- |
可能發生 |
| 可序列化Serializable |
- |
- |
- |
可序列化(Serializable)隔離級別不等同於可序列化(Serializable)。可序列化排程是避免以上三種現象的必要條件,但不是充分條件。
“可能發生”表示這個隔離級別會發生對應的現象,“-”表示不會發生。
隔離級別vs 鎖持續時間
在基於鎖的併發控制中,隔離級別決定了鎖的持有時間。"C"-表示鎖會持續到事務提交。 "S" –表示鎖持續到當前語句執行完畢。如果鎖在語句執行完畢就釋放則另外一個事務就可以在這個事務提交前修改鎖定的資料,從而造成混亂。
| 隔離級別l |
寫操作 |
讀操作 |
範圍操作 (...where...) |
| 未提交讀Read uncommitted |
S |
S |
S |
| 提交讀Read committed |
C |
S |
S |
| 可重複讀Repeatable read |
C |
C |
S |
| 可序列化Serializable |
C |
C |
C |
MySQL事務隔離簡單介紹
在MySQL裡共有四個隔離級別,分別是:
- Read uncommttied(讀未提交資料)
- Read committed(讀已提交資料)
- Repeatable read(可重複讀)
- Serializable(可序列化)
在MySQL資料庫裡,預設的事務隔離級別是Repeatable read(可重複讀)。
相關命令
1.檢視當前會話隔離級別
SELECT @@tx_isolation;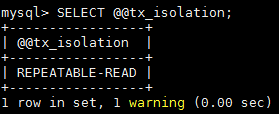
2.檢視系統當前隔離級別
SELECT @@global.tx_isolation;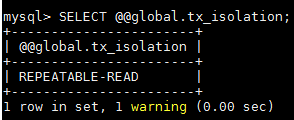
3.設定當前會話隔離級別
set session transaction isolation level read uncommitted;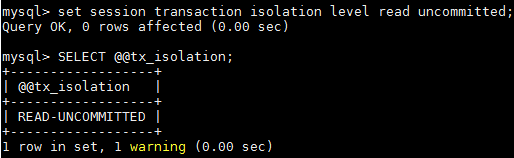
4.設定系統當前隔離級別
set global transaction isolation level read uncommitted;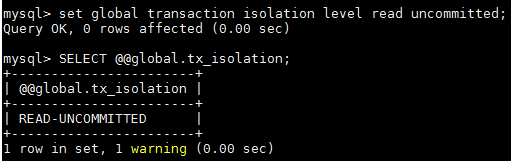
5.命令列,開始事務時
set autocommit=off;或者
start transaction;
注意
但是這裡有一點需要注意的是資料庫的預設引擎是InnoDB在使用InnoDB引擎下,即便設定的事務隔離級別是Repeatable read,也不會出現資料幻讀現象。
-原因:MySQL InnoDB儲存引擎,實現的是基於多版本的併發控制協議——MVCC (Multi-Version Concurrency Control) 所以在Repeatable Read (RR)隔離級別下不存在幻讀。
參考:
http://www.luxinzhi.com/database/502.html
https://zh.wikipedia.org/wiki/%E4%BA%8B%E5%8B%99%E9%9A%94%E9%9B%A2
http://www.cnblogs.com/zhoujinyi/p/3437475.html
https://www.jianshu.com/p/4e3edbedb9a8
http://www.cnblogs.com/zhoujinyi/p/3437475.html
http://www.hollischuang.com/archives/943