
C語言連結串列(超詳細)
前言:之前學習連結串列的時候總會遇到一些問題
也看了好多人的文章感覺有些不是太實用
然後後來也是自己摸索才大概寫出來的.
在真正的開發中會把連結串列的增刪改查寫到函式裡
但是刪除有點麻煩 找了很多都是刪除第幾個 而不是刪除某個值對應的節點 讓我很難受
所以想寫一些連結串列的操作分享一些 我也不會用長一點的名字去命名 這樣閱讀性會好一些
不過在實際開發中建議使用較長的名字去命名好了 話不多說
一.連結串列的建立
一般分為頭插法和尾插法
1.我在寫專案的時候喜歡使用頭插法
因為我希望在建立結點的時候按照某種方法去排序
如果用尾插法建立的話快 但是 如果在建立好後再排序就有些麻煩
話不多說貼程式碼.
第一步 讓我們寫出這個結點的宣告`
typedef struct node {
int data;
struct node* next;
} Node;
然後先讓我們看看主函式中該怎麼寫
#include <stdio.h>
#include <stdlib.h>
int main() {
Node *head;
head = NULL;
int n;//這裡的n代表建立多少個結點
scanf("%d",&n);
for (int i = 0; i < n; ++i) {
int a;//這裡的a代表傳給結點的值 接下來就是inser()函式的寫法了.
首先我們需要在這個函式裡面建立一個結點
void insert(Node **head ,int 然後怎麼利用頭結點的頭插法把這個連結串列連起來呢?
我們首先得判斷 這個頭結點是不是為NULL 因為在定義的時候定義了NULL
if((*head) == NULL) {//這裡*head 因為head是二級指標 加個*就降了一級.
(*head) = temp; //建議全部帶括號*這個運算子的結合律防止出錯都帶括號把
}其實這個判斷也就是判斷是不是第一次建立 頭結點有沒有東西
頭結點要是有了東西呢?
else {
Node *t = (*head); //讓臨時指標的從頭開始遍歷.
while(t->next != NULL) { // 這裡一定是t->next 如果讓t連的話 就連線不起來
t = t->next;
}
t->next=temp; //指標域的作用就是連線.
}好了 這就是頭插法的建立
但是我們明顯發現效率不高 尾插法建立一個就接到連結串列裡面
建立一個就接進去.
但是頭插法不行. 必須是建立一個 再從頭開始.
但是!
看接下來的一個妙用 我要建立連結串列並且排序.
這裡我們做一個約定 從小到大排列.讓我們看看怎麼做
還是像剛才建立一樣 如果頭是空怎麼怎麼樣 否則怎麼怎麼樣對嗎?
想一想要改這裡嗎?
if((*head) == NULL) {
(*head) = temp;
} else {答案肯定是不用改因為沒資料肯定就把第一個放進去.
那麼肯定就是改下一處了
按照我們剛在的想法是不是可以這樣寫
while(t != NULL) {
if(t->next->data > temp->data) { // 如果t的下一個的資料大於了新結點
temp->next = t->next; //讓新結點的指標指向了t的下一個
t->next = temp; //再讓t指向新結點
return; //返回就好
}
t = t->next;
}但是這裡其實是有兩處問題的 先說第一處:
因為是從小到大比較的 我們上面的寫法是從頭開始
找到比他大的地方就讓他插進去.但是如果新的結點就是最大的呢
也就是跑到完都沒進到 if 語句中去
所以應該加一個
while(t != NULL) {
if(t->next == NULL) {//這一次我們判斷下一個是不是空
t->next = temp; //如果是空了連線一下
return; //返回就行
} else if(t->next->data > temp->data) {
temp->next = t->next;
t->next = temp;
return;
}
t = t->next;
}上述不要忘記了返回
還有一個問題就是如果新的結點比頭結點小了怎麼辦
看看我們上面的寫法他永遠比較的是當前結點的下一個 也就是頭結點根本沒有比較
所以我們讓他在開始的時候比較一下就好了
if(temp->data < (*head)->data) {
temp->next = (*head);//新結點的下一個指向頭結點
(*head) = temp; //頭結點變成了新結點
return; //返回
}好了 這裡就寫完了 開發的時候具體按照你的方式去建立連結串列 要比較什麼 你自己定
完整程式碼
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int data;
struct node* next;
} Node;
void insert(Node **head ,int value) {//這個引數是取頭結點的地址 因為在主函式中定義了這個頭結點 Node* head;所以要傳地址過來.
Node *temp = (Node*)malloc(sizeof(Node));
temp->next = NULL;
temp->data = value;
if((*head) == NULL) {
(*head) = temp;
} else {
Node *t = (*head);
if(temp->data < (*head)->data) {
temp->next = (*head);
(*head) = temp;
return;
}
while(t != NULL) {
if(t->next == NULL) {
t->next = temp;
return;
} else if(t->next->data > temp->data) {
temp->next = t->next;
t->next = temp;
return;
}
t = t->next;
}
}
}
int main() {
Node *head;
head = NULL;
int n;//這裡的n代表建立多少個結點
scanf("%d",&n);
for (int i = 0; i < n; ++i) {
int a;//這裡的a代表傳給結點的值
scanf("%d",&a);
insert(&head, a);//insert 增加連結串列結點函式
}
Node *temp = head;
while(temp != NULL) { //輸出這個連結串列
printf("%d ",temp->data);
temp = temp->next;
}
return 0;
}頭插法講完了 讓我們講一下尾插法
先看一下 一般的建立方式
首先尾插法的核心程式碼
for(int i = 0; i < n; i++) {
temp = (Node*)malloc(sizeof(Node));
temp->next = NULL; //這裡很重要
scanf("%d",&temp->data);
if(head == NULL) {
head = temp;
} else {
q->next = temp; //連線起來
}
q = temp; //尾插法的核心
}解讀 : 建立n個結點 一開始也一樣 判斷head 是不是空
是的話就讓head是第一個結點.
同時我們有個尾巴這個時候因為是第一個結點所以 尾巴也指向了temp
也就是 建立完第一個 我們的 head 和 q 這個指標都指向的第一個結點
然後第二個來了就用(尾結點)q->next的指標指向了第二個結點
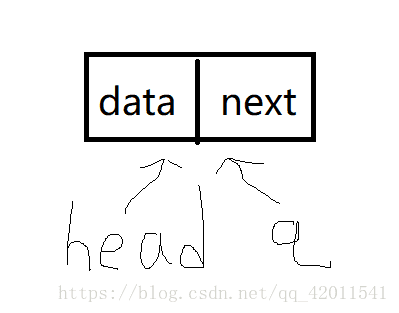
像這樣子 第一個結點 head 和 q都指向第一個
來了一個結點
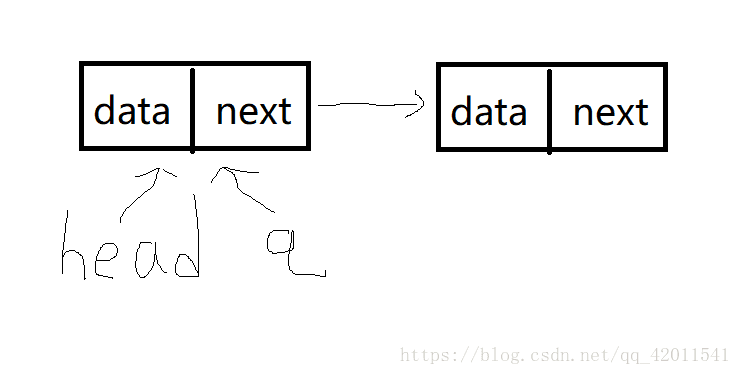
q->next就把第二個連上了
然後q又成了新結點 像這個樣子
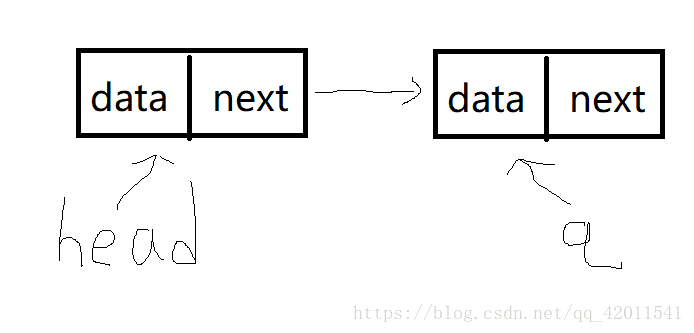
我們發現什麼 建立一個結點q->next連線後
q又指向了新結點
q像不像一個尾巴?
好了 把他放函式裡面吧
但是! 我們發現一個問題 怎麼保留這個尾巴呢?
想一想你呼叫函式 在函式裡面保留尾巴
函式結束就釋放掉了
所以我們有三個方法
第一個就是把尾巴定義在主函式裡 然後每次把這個尾巴的地址傳過去 在裡面改變尾巴
像這樣子
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int data;
struct node* next;
} Node;
void insert(Node **head, Node **q, int value) {// 第一個頭的地址 第二個尾的地址
Node* temp = (Node*)malloc(sizeof(Node));
temp->next = NULL;
temp->data = value;
}
int main() {
Node *head, *temp, *q;
head = NULL;
int n;
scanf("%d",&n);
for(int i = 0; i < n; i++) {
int a;
scanf("%d",&a);
insert(&head, &q, a);
}
Node *t = head;
while(t != NULL) {
printf("%d ",t->data);
t = t->next;
}
return 0;
}然後 判斷方面和一開始的頭插不太一樣 和尾插的是一樣 來看看
void insert(Node **head, Node **q, int value) {// 第一個頭的地址 第二個尾的地址
Node* temp = (Node*)malloc(sizeof(Node));
temp->next = NULL;
temp->data = value;
if((*head) == NULL) {
(*head) = temp;
} else {
(*q)->next = temp;
}
(*q) = temp;
return;
}怎麼樣? 很簡單吧?
說一下第二種方式 就是多了一個返回值 返回一個Node*
然後傳尾結點的形參就行了
Node* insert(Node **head, Node *q, int value) 函式宣告變成了這樣
for(int i = 0; i < n; i++) {
int a;
scanf("%d",&a);
q = insert(&head, q, a);
}然後主函式裡 這樣呼叫函式
Node* insert(Node **head, Node *q, int value) {
Node* temp = (Node*)malloc(sizeof(Node));
temp->next = NULL;
temp->data = value;
if((*head) == NULL) {
(*head) = temp;
} else {
q->next = temp;
}
q = temp; //在這裡改變了尾結點
return q;// 返回新的尾結點
}函式體
然後就是第三種方法用到了 static關鍵字
不知道可以百度下 就是在函式裡面用static關鍵字修飾了尾結點
你就可以每次呼叫這個函式這個結點就一直保留上次的值
方法就是這樣 也不用傳一個尾結點過來
void insert(Node **head, int value) {// 第一個頭的地址 第二個尾的地址
static Node* q;
Node* temp = (Node*)malloc(sizeof(Node));
temp->next = NULL;
temp->data = value;
if((*head) == NULL) {
(*head) = temp;
} else {
q->next = temp;
}
q = temp;
return ;
}好了連結串列的增加到此結束
二.連結串列的刪除
這個是比較難的.我們這裡的刪除用的是輸入一個值去刪除一個結點 或者全部刪除
比如開發學生管理系統 你要按照學號去刪除人
或者開發票務管理系統按照電影票去刪除 你並不知道他是第幾個對不對
好了,開始吧.
讓我們給出這個函式的宣告
void remove(Node **head, int key);兩個引數 一個是連結串列的頭.從頭開始刪除
一個是要刪除對應的資料
比如 3 5 4 8 5 4 5
刪除5
就變成了 5 5 5
好了 開始寫函式吧 首先得有個東西從頭開始遍歷
void remove(Node **head, int key) {
Node *t = (*head);
}這樣寫OK把?
我們從頭開始遍歷 我們可以定義 如果當前的結點的下一個結點和key相等
就讓一個臨時結點儲存下一個結點並且當前結點指向下一個結點的下一個結點
就比如當前結點是1號結點
有1->2->3->NULL
然後傳過來的key就是2
那麼我讓一個臨時結點儲存2號結點 讓1->3->NULL
然後free(2)就可以
if(t->next->data == key) { // 如果相等就釋放相應的結點
Node* temp = t->next;
t->next = t->next->next;
free(temp);
} else {//否則才讓t = t->next 想一想為什麼
t = t->next;
}上述想一想.
因為 如果不把t = t->next放在else裡看一下下面的情況
key = 3
你的結點是2 3 3 3 2
我們現在刪除第二號結點 也就是第一個3
刪完後變成了
2->3->3->2->NULL
然後這個時候t是什麼?
t就是第二個結點 然後過來判斷 t的下一個是不是3 是3刪除了
然後2->3->2->NULL
然後跑完了 發現並沒有刪除完全.所以刪除結點就別讓這個跑了
好了然後看一下這個刪除的完整程式碼
while(t->next != NULL) {
if(t->next->data == key) {
Node* temp = t->next;
t->next = t->next->next;
free(temp);
} else {
t = t->next;
}
}但是上述還有一個問題 如果刪的那個剛好是頭呢?
我們是從第二個開始刪的因為我並沒有用一個東西去保留上一個結點 所以我判斷當前的下一個 這樣好刪些
所以頭結點是無法刪除的
怎麼解決這個問題呢? 單獨判斷下就好了
想一想是在while迴圈開始 還是 結束之後?
肯定是結束之後啊.
要是在開始 發現前兩個都是你要刪的 你是不是又漏刪一個.
所以一個while迴圈跑完 該刪的都刪完了 就剩頭了 頭要麼是 要麼不是
判斷一下 是就刪了 不是就不管
.
if((*head)->data == key) {
Node* temp = (*head);
(*head) = (*head)->next;
free(temp);
}好了 看一下 刪除的完整程式碼
void remove(Node **head, int key) {
Node *t = (*head);
while(t->next != NULL) {
if(t->next->data == key) {
Node* temp = t->next;
if(t->next->next == NULL) {
t->next = NULL;
free(temp);
break;
} else {
t->next = t->next->next;
free(temp);
}
} else {
t = t->next;
}
}
if((*head)->data == key) {
Node* temp = (*head);
(*head) = (*head)->next;
free(temp);
}
}好了 其實 刪除有很多種方式 你可以知道原理後自己寫 注意有一些細節
那麼相對來說難一些的刪除都搞定了改 查兩個超簡單的還難嘛?
三.連結串列的改
說一下 連結串列的改一般來說是改單個連結串列 連結串列的改其實可以和連結串列的查聯合起來
連結串列查到了一個結點返回給連結串列修改功能連結串列一改豈不是美滋滋
我這裡 單獨寫一個功能
哈哈哈 後面就好寫了 寫完連結串列的查 再寫另外一版本
來改連結串列函式宣告
void change(Node **head, int key);//由於是要更改所以傳地址第一個引數是連結串列的頭 第二個是要修改的那個序號
其實我們這裡面重複用到了連結串列的查詢
寫完連結串列的查 再寫一版修改
還是老模版 從頭開始 只不過這次不像刪除那麼麻煩 好了 話不多說
直接上完整程式碼
void change(Node **head, int key) {
Node *t = (*head);
while (t != NULL) {
if (t->data == key) {
//這裡寫修改
break; //全改就不要break; 改一個就break;
}
t = t->next;
}
}連結串列的改寫完了, 是不是很簡單?
四.連結串列的查
我這裡連結串列的查分為兩種
1.帶返回值
帶返回值我們返回一個結點
函式宣告
Node* find(Node **head, int key);後面的話不多話 找到了這個 就返回這個結點
直接完整程式碼:
Node* find(Node *head, int key) { //這裡head一維指標不用修改操作
Node *t = (*head);
while(t != NULL) {
if(t->data == key) {
return t;
}
t = t->next;
}
}2.不帶返回值
完整程式碼
void find(Node *head, int key) {//這裡head一維指標不用修改操作
Node *t = (*head);
while(t != NULL) {
if(t->data == key) {
printf("");
//....省略一大堆程式碼
}
t = t->next;
}
}第二個找到全部的輸出 比如符合的電影票 火車票OK
我們上次說的可以用查和改寫一個程式碼
先寫兩個宣告
Node* find(Node *head, int key);
void change(Node **head, int key);Node* find(Node *head, int key) {
Node *t = head;
while(t != NULL) {
if(t->data == key) {
return t;
}
t = t->next;
}
}
void change(Node **head, int key) {
Node *t = find((*head), key);
//這裡修改t這個結點的程式碼
}好了 就到這裡
如果我寫連結串列到這你能完全跟的上 不妨看看我另外一篇儲存資料的結構
二叉樹 其實真的和連結串列很像
https://blog.csdn.net/qq_42011541/article/details/80547098