
軟體工程的基礎知識概念
軟體的概念:
一個軟體包含下面三個部分:
1、指令的集合,通過執行這些指令可以滿足預期的特徵、功能和效能需求;
2、資料結構,使得程式可以合理利用資訊;
3、軟體描述資訊,它以硬拷貝和虛擬形式存在,用來描述程式操作和使用。
軟體工程的概念:
1、將系統化的、規範化、可量化的方法應用於軟體的開發、執行和維護,即將工程化方法應用於軟體。
2、在1中所述方法的研究。
軟體和硬體的區別:
1、軟體是設計開發的,而不是傳統意義上生產製造的。
2、軟體不會“磨損” 。
3、大多數軟體根據實際的顧客需求定製的。

支援軟體工程的根基在於質量關注點(quality focus)
軟體工程的基礎是過程(process)層。軟體過程將各個技術層次結合在一起,使得合理、及時地開發計算機軟體成為可能;
軟體工程方法(method)為構建軟體提供技術上的解決方法。方法包括:溝通、需求分析、設計模型、程式設計、測試和技術支援。
軟體過程:
軟體過程是工作產品構建時所執行的一系列活動、動作和任務的集合。
Generic Framework Activity (通用框架活動):
適用於所有軟體專案,無論其規模和複雜程度如何。
1、溝通(Communication):目的是理解利益相關者的專案目標,並收集需求以定義軟體特性和功能。
2、策劃(Planning):定義和描述了軟體工程工作,包括需要執行的技術任務、可能的風險、資源需求、工作產品和工作進度計劃。
3、建模(Modeling):利用模型哎更好地理解軟體需求並完成符合這些需求的軟體設計。
4、構建(Construction):它包括編碼和測試以發現編碼中的錯誤。
5、部署(Deployment):軟體交付到使用者,使用者對其進行評測並給出反饋意見。
Umbrella Activities(普適性活動):
普適性活動貫穿軟體專案始終。
1、軟體專案跟蹤和控制:專案根據計劃評估專案進度,並且採取必要的措施保證專案按進度計劃進行。
2、風險管理:對可能影響專案成果或者產品質量的風險進行評估。
3、軟體質量保證:確定和執行軟體質量保證的活動
4、技術評估:評估軟體工程產品、儘量在錯誤傳播到下一個活動之前,發現並清除錯誤。
5、測量:定義和收集過程、專案和產品的度量,以幫助團隊在釋出軟體的時候滿足利益相關者要求。同時,測量還可以與其他框架活動和普適性活動配合使用。
6.軟體配置管理:在整個軟體工程中,管理變更所帶來的影響。
7.可複用管理:定義產品複用的標準,並且建立構建複用機制。
8.工作產品的準備和生產:包括了生產產品所必需的活動。
軟體的生命週期:
軟體生命週期又稱為軟體生存週期或系統開發生命週期,是軟體的產生直到報廢的生命週期。
軟體生存週期包括:
1、問題定義:弄清"使用者需要計算機解決什麼樣的問題”,提出"系統目標和範圍的說明“,提交使用者審查和確認。
2、可行性分析:把待開發系統的目標以明確的語言描述出來,並從經濟、技術、法律等多個方面進行可行性分析。
3、需求分析:弄清使用者對軟體系統的全部需求,編寫需求規格說明書和初步的使用者手冊,提交評審。
4、開發階段:設計、實現(完成源程式的編碼)、測試
5、維護:改正性維護(由於開發測試的不徹底、不完全),適應性維護(適應環境變化),完善性維護(使用過程中提出的一些建設性意見),預防性維護(改善軟體系統的可維護性和可靠性)。
軟體過程:
指軟體生命週期所涉及的一系列相關過程,是指一套關於專案的階段、狀態、方法、技術和開發、維護軟體的人員以及相關Artifacts(計劃、文件、模型、編碼、測試、手冊等)組成。包含基本過程類、支援過程類、組織過程類。
1、基本過程類包括獲取過程、供應過程、開發過程、運作過程、維護過程和管理過程。
2、支援過程類包括文件過程、配置管理過程、質量保證過程、驗證過程、確認過程、聯合評審過程、審計過程以及問題解決過程。
3、組織過程類包括基礎設施過程、改進過程、培訓過程。
軟體過程模型:
過程模型總共分為三大類:
1、慣例過程模型:
瀑布模型(又叫作生命週期模型);
增量過程模型: 包括增量模型、RAD模型;
演化過程模型: 包括原型開發模型、螺旋模型、協同開發模型;
專用過程模型: 包括基於構件的開發模型、形式化方法模型、面向方面的軟體開發模型。
2、面向物件模型:
噴泉模型;
可重用部件組裝模型。
3、敏捷過程模型:
XP模型;
自適應軟體開發;
動態系統開發;
Scrum模型;
Crystal模型;
特徵驅動開發;
敏捷建模。
常見軟體工程模型:
瀑布模型:
將軟體生命週期中的各個活動規定為線性連線的模型,包括需求分析、設計、編碼、測試、執行與維護,由前至後、相互銜接的固定順序,如同瀑布流水逐級下落。

瀑布模型是以文件作為驅動、適合於軟體需求很明確的軟體專案的模型。
V模型:
瀑布模型的一個變體,提供了一種驗證確認活動應用於早期軟體工程工作中的方法。

瀑布模型的優點:
容易理解,管理成本低;
強調開發的階段性早期計劃及需求調查和產品測試。
瀑布模型的缺點:
客戶必須能夠完整、正確和清晰地表達他們的需要;
開始2個或3個階段,很難評估真正的進度;
專案結束時,出現大量的整合和測試工作;
需求或設計中的錯誤往往只有到了專案後期才能夠被發現,對於專案風險的控制能力較弱,從而導致專案常常延期完成,開發費用超出預算。
增量模型:
融合了瀑布模型的基本成分和原型實現的迭代特徵,它假設可以將需求分段為一系列增量產品,每一增量可以分別開發。

使用增量模型,第1個增量往往是核心的產品。客戶對每個增量的使用和評估都作為下一個增量釋出的新特徵和功能,這個過程在每一個增量釋出後不斷重複,直到產生了最終的完善產品。增量模型強調每一個增量均釋出一個可操作的產品。
增量模型的優點:
容易理解,管理成本低;
強調開發的階段性早期計劃及需求調查和產品測試;
第一個可交付版本所需要的成本和時間很少;
開發由增量表示的小系統所承擔的風險不大;減少使用者需求的變更;
執行增量投資,即在專案開始時,可以僅對一個或兩個增量投資。
增量模型的缺點:
如果沒有對使用者的變更需求進行規劃,那麼產生的初始增量可能會造成後來增量的不穩定;
如果需求不想早期思考的那樣穩定和完整,那麼一些增量就可能需要重新開發,重新發布;
管理髮生的成本、進度和配置的複雜性可能會超出組織的能力。
演化模型:
是迭代的過程,軟體開發人員能逐步開發出更完整的軟體版本,適用於軟體需求缺乏準確認識的情況,典型的演化模型有原型模型和螺旋模型。
1、演化模型之原型模型:
是預期系統的一個可執行版本,反映了系統性的一個選定的子集,一個原型不必滿足目標軟體的所有約束,目的是能快速、低成本地構建原型。
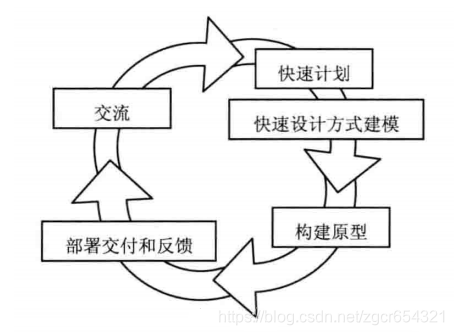
原型模型開始於溝通,其目的是定義軟體的總體目標,標識需求,然後快速制定原型開發的計劃,確定原型的目標和範圍,採用快速射擊的方式對其進行建模,並構建原型。
根據原型的目的,可分為三種:
探索型原型:
目的是弄清目標的要求,確定所希望的特性,並探討多種方案的可行性。
實驗型原型:
目的是驗證方案或演算法的合理性,是在大規模開發和實現前,用於考查方案是否合適、規格說明是否可靠等。
演化型原型:
目的是將原型作為目標系統的一部分,通過對原型的多次改進,逐步將原型演化成最終的目標系統。
2、演化型模型之螺旋模型:
將瀑布模型與演化模型結合起來,加入了兩種模型均忽略的風險分析,彌補了這兩種模型的不足。
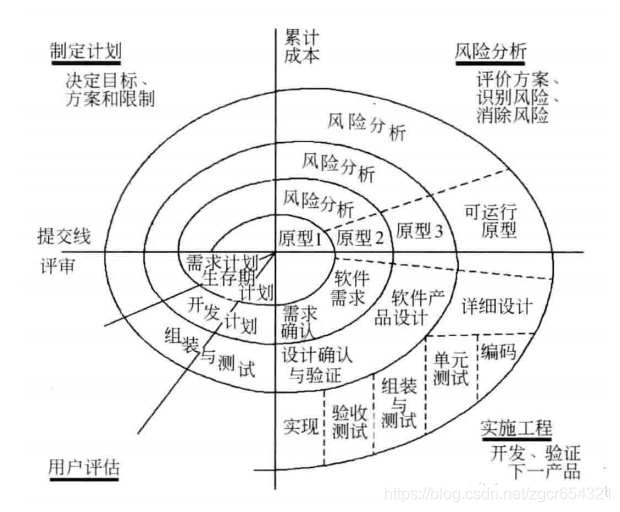
螺旋模型將開發過程分為幾個螺旋週期,每個螺旋週期大致和瀑布模型相符合:
制定計劃:確定軟體的目標,選定實施方案,明確專案開發的限制條件。
風險分析:分析所需的方案,識別風險,消除風險。
實施工程:實施軟體開發,驗證階段性產品。
使用者評估:評價開發工作,提出修正建議,建立下一個週期的開發計劃。
螺旋模型強調風險分析,使得開發人員和使用者對每個演化層出現的風險有所瞭解,從而做出應有的反應。因此,該模型特別適用於龐大、複雜並且具有高風險的系統。
螺旋模型和瀑布模型比較:
螺旋模型支援使用者需求動態變化,為使用者參與軟體開發的所有關鍵決策提供了方便,有助於提高軟體的適應能力,並且為專案管理人員及時調整管理決策提供了便利,從而降低了軟體開發的風險。在使用螺旋模型進行軟體開發時,需要開發人員具有相當豐富的風險評估經驗和專門知識。另外,過多的迭代次數會增加開發成本,延遲提交時間。
協同模型:
有時候又稱為協同工程,它允許軟體團隊表述本章所描述的任何模型中的迭代和併發元素。 協同建模提供了專案當前狀態的準確畫面。 適合所有型別的軟體開發,協同模型通常更適合涉及不同工程團隊的產品工程專案。
統一過程模型:
統一過程模型是一種“用例驅動、以體系結構為核心、迭代及增量”的軟體 過程框架,由 UML 方法和工具支援。

它是一種增量模型,定義了五個階段:
起始階段,包括使用者溝通和計劃活動,強調定義和細化用例;
細化階段,包括使用者溝通和建模活動,重點是建立分析和設計模型;
構件階段,細化模型設計,並將設計模型轉化為軟體構件實現;
轉化階段,將軟體從開發人員傳遞給終端使用者,並由使用者完成 beta 測試和驗收測試;
生產階段,持續地監控軟體的執行,並提供技術支援。
統一過程模型的優點:
任何功能開發後就進入測試過程,及早進行驗證;
早期風險識別,採取預防措施。
統一過程模型的缺點:
需求必須在開始之前完全弄清楚,否則有可能在架構上出現錯誤;
必須有嚴格的過程管理,以免使過程退化為原始的試→錯→改模式;
如果不加控制的讓使用者過早接觸沒有測試完全,版本不穩定的產品可能對用 戶和開發團隊都帶來負面的影響。
噴泉模型:
一種以使用者需求為動力,以物件作為驅動的模型,適合於面向物件的開發方法。它克服了瀑布模型不支援軟體重用和多項開發活動整合的侷限性,噴泉模型使開發過程具有迭代性和無間隙性。
噴泉模型的優點:
提高軟體專案的開發效率,節省開發時間。
噴泉模型的缺點:
開發階段是重疊的,開發過程中需要大量的開發人員,不利於專案的管理。需要嚴格的管理文件,使得稽核的難度加大。
基於構件的開發模型:
利用預先包裝的構件來構造應用系統,基於構件的開發模型具有許多螺旋模型的特點,它本質上是演化模型,需要以迭代的方式構建模型。分為領域工程和應用系統工程兩部分。

領域工程的目的是構建領域模型、領域基準體系結構和可複用構件庫。 應用系統工程的目的是使用可複用構件組裝應用系統。
形式化方法模型:
建立在嚴格數學基礎上的一種軟體開發方法,主要活動是生成計算機軟體形式化的數字規格說明。用嚴格的數學語言和語義描述功能規約和設計規約,通過數學的分析和推導,易於發現需求的歧義性、不完整性和不一致性,易於對分析模型、設計模型和程式進行驗證。
結構化分析的概念:
是一種軟體開發方法,一般利用圖形表達使用者需求,強調開發方法的結構合理性以及開發軟體的結構合理性。
結構是指系統內各個組成要素之間的相互聯絡、相互作用的框架。結構化開發提出了一組提高軟體結構合理性的準則,如分解與抽象、模組獨立性、資訊隱蔽等。針對軟體生存週期各個不同的階段,它有結構化分析和結構化程式設計等方法。
結構化分析方法給出一組幫助系統分析人員產生功能規約的原理與技術。它一般利用圖形表達使用者需求,使用的手段主要有資料流圖、資料字典、結構化語言、判定表以及判定樹等。
結構化分析的步驟如下:
分析當前的情況,做出反映當前物理模型的DFD;
推匯出等價的邏輯模型的DFD;
設計新的邏輯系統,生成資料字典和基元描述;
建立人機介面,提出可供選擇的目標系統物理模型的DFD;
確定各種方案的成本和風險等級,據此對各種方案進行分析;
選擇一種方案;
建立完整的需求規約。
敏捷宣言(Agile development manifesto):
個人和這些個人之間的交流勝過了開發過程和工具
可執行的軟體勝過了寬泛的文件
客戶合作勝過了合同談判
對變更的良好響應勝過了按部就班地遵循計劃
極限程式設計:
極限程式設計是敏捷軟體開發使用最廣泛的一個方法。極限指的是把好的開發實踐運用到極致。廣泛運用於需求模糊且經常變動的場合。極限程式設計面對變化和不確定性更加快速敏捷,能快速持續迭代漸增。
極限程式設計的特點:
1、客戶作為開發團隊的成員。客戶與開發緊密配合,客戶負責確定需求,回答問題,驗收。
2、短交付週期。兩週一次迭代,互動目標系統可工作的版本,不斷演示迭代生成的系統獲得反饋意見。
3、結對程式設計,測試驅動開發。先有好的測試方案然後再程式設計,所有的測試工作完成了才算工作完成。
4、整合所有。程式程式碼歸所有人所有,任何人都有修改程式碼的權利,全體成員對所有程式碼負責。
5、持續整合。多次整合系統,隨著需求的變更,不斷迴歸測試。
6、可持續開發速度,能維持長期穩定的速度,開放的工作空間,全體成員在開放場所工作,隨時自由交流討論。
7、及時調整計劃。計劃是靈活和循序漸進的。
8、重構。程式碼重構是在不影響系統行為的前提下,重新調整和優化系統的內部結構,降低複雜性,消除冗餘,增加靈活性,提高效能。不要過分依賴重構,前期重設計。
設計概念:
抽象(Abstraction):
過程抽象是指具有明確和有限的指令序列(描述動作)
資料抽象是描述資料物件的冠名資料集合(描述動作怎麼做)
體系結構(Architecture):
軟體的整體結構和這種結構為系統提供概念完整方式。構件表示主要的系統元素及其互動。
模式(Patterns):
模式承載了已證實的解決方案的精髓。設計模式描述了在某個特定場景與可能影響模式應用和使用方法的“影響力”中解決某個特定的設計問題的設計結構。
關注點分離(Separation of concerns):
它表明任何複雜問題如果被分解為可以獨立解決和優化的若干塊,該複雜問題能夠更容易的被處理。
模組化(Modularity):
模組化是關注點分離最常見的表現。模組化設計使得開發工作更易規劃。
資訊隱蔽(Hiding):
隱蔽意味著通過定義一系列獨立的模組可以得到有效的模組化,獨立模組互相之間只交流實現軟體功能所必須的那些資訊。隱蔽定義並加強了對模組內過程細節的訪問約束和對模組所使用的任何區域性資料結構的訪問約束。
功能獨立(Functional independence):
開發具有“專一”功能和低耦合性的模組即可實現功能獨立。
求精(Refinement):
通過連續精化過程細節層次來實現程式的開發,通過逐步分解功能的巨集觀陳述直到形成程式設計語言的語句來進行層次開發。
抽象和精化是互補的概念。
方面(Aspects):
一個方面作為一個獨立的模組進行實施,而不是作為“分割的”或者和許多構件“糾纏的”軟體片段進行實施。設計體系結構應當支援定義一個方面,該方面即一個模組,該模組能夠使該關注點經過它橫切的所有其他關注點而得到實施。
重構(Refactoring):
重構是使用這樣一種方式改變軟體系統的過程:不改變程式碼的外部行為而是改進其內部結構。
物件:
物件(Object)是系統中用來描述客觀事物的一個實體,它是構成系統的一個基本單位,由一組屬性和對這組屬性進行操作的一組服務組成。
類:
類(Class)是具有相同屬性和服務的一組物件的集合,它為屬於該類的全部物件提供了統一的抽象描述,其內部包括屬性和服務兩個主要部分。
封裝:
封裝(Encapsulation)是把物件的屬性和服務結合成一個獨立的系統單位,並儘可能隱藏物件的內部細節。
繼承:
繼承(Inheritance)是指子類可以自動擁有父類的全部屬性和服務。
訊息:
訊息(Message)是物件發出的服務請求,一般包含提供服務的物件標識、服務標識、輸入資訊和應答資訊等資訊。
多型性:
多型性(Polymorphism)是指在父類中定義的屬性或服務被子類繼承後,可以具有不同的資料型別或表現出不同的行為。
主動物件:
主動物件(Active Object)是一組屬性和一組服務的封裝體,其中至少有一個服務不需要接收訊息就能主動執行(稱為主動服務)。
面向物件分析:
面向物件的分析(OOA)就是運用面向物件的方法進行需求分析,其主要任務是分析和理解問題域,找出描述問題域和系統責任所需的類及物件,分析它們的內部構成和外部關係,建立OOA模型。
面向物件設計:
面向物件的設計(OOD)就是根據已建立的分析模型,運用面向物件技術進行系統軟體設計。它將OOA 模型直接變成OOD模型,並且補充與一些實現有關的部分,如人機介面、資料儲存、任務管理等。
面向物件程式設計:
面向物件的程式設計(OOP)就是用一種面向物件的程式語言將OOD模型中的各個成分編寫成程式。
面向物件測試:
面向物件的測試(OOT)是指對於運用OO技術開發的軟體,在測試過程中繼續運用OO技術進行以物件概念為中心的軟體測試。
黑盒測試:
黑盒測試也稱功能測試或資料驅動測試,它是在已知產品所應具有功能的情況下,通過測試來檢測每個功能是否都能正常使用。
白盒測試:
白盒測試也稱結構測試或邏輯驅動測試,它是知道產品內部工作過程,可通過測試來檢測產品內部動作是否按照規格說明書的規定正常進行,按照程式內部的結構測試程式,檢驗程式中的每條通路是否都有能按預定要求正確工作,而不顧它的功能。
基本設計原則:
開閉原則(Open-Closed Principle ,OCP):模組應該對外延具有開放性,對修改具有封閉性。
依賴倒置原則(Dependency Inversion Principle ,DIP):依賴於抽象,而非具體實現。
Liskov替換原則(Liskov Substitution Principle (LSP)):子類可以替換他們的基類。
介面分離原則(The Interface Segregation Principle (ISP)):多個客戶專用介面比一個通用介面好
釋出複用等價性原則(The Release Reuse Equivalency Principle,REP):複用的粒度就是釋出的粒度
共同封裝原則(The Common Closure Principle (CCP)):一同變更的類應該合在一起
共同複用原則(The Common Reuse Principle (CRP)):不能一起復用的類不能被分到一組
內聚性(Cohesion):
內聚性意味著構件或者類只封裝那些相互關聯密切,以及與構件或類自身有親密關係的屬性和操作。
功能內聚:主要通過操作來體現,當一個模組只完成某一組特定操作並返回結果時,就稱此模組是功能內聚的。
分層內聚:高層能夠訪問低層的服務,但低層不能訪問高層的服務。
通訊內聚:訪問相同資料的所有操作被定義在同一個類中。(資料的查詢,訪問,儲存)
耦合性(Coupling):
耦合是類之間彼此聯絡程度的一種定性度量。 隨著類(構件)相互依賴越來越多,類之間的耦合程度亦會增加。
內容耦合:暗中修改其他構件的內部資料,這違反了資訊隱蔽原則
公用耦合:當大量的構件都要使用同一個全域性變數時發生這種耦合
控制耦合:當操作A呼叫操作B,並向B傳遞控制標記時,就會發生這種耦合。
標記耦合:當類B被宣告為類A某一操作中的一個引數型別時,就會發生這種耦合。
資料耦合:當操作需要傳遞長串的資料引數時,就會發生這種耦合。
例程呼叫耦合:當一個操作呼叫另一個操作時,就會發生這種耦合。
型別使用耦合:當構件A使用了在構件B中定義的一個數據型別時,就會發生這種耦合。
包含或者匯入耦合:當構件A引入或者包含一個構件B的包或者內容時,就會發生這種耦合。
外部耦合:當一個構件和基礎設施構件進行通訊和協作時,就會發生這種耦合。
為什麼要高內聚?
模組之間的關係越緊密,出錯就越少!
為什麼要低耦合?
子程式間的關係越複雜,就會產生更多的意想不到的錯誤!會給以後的維護工作帶來很多麻煩!
高內聚低耦合,是軟體工程中的概念,是判斷設計好壞的標準,主要是面向物件的設計,主要是看類的內聚性是否高,耦合度是否低。