
用python爬取股票資料的一點小結
阿新 • • 發佈:2018-11-09
一、背景
網上對於爬取股票資料有相對完善的教程。不過大部分教程都是隻能夠爬取一段時間的股票資料,針對某一隻股票的歷史資料爬取,目前還沒有看到比較好的教程。下面對近期學的東西進行一點點小結。
二、股票資料爬取網站
網上更多推薦的是東方財富的股票資料,連結為:http://quote.eastmoney.com/stocklist.html
東方財富上能夠獲得所有股票的編號資訊,有助於股票資料的爬取,但是每天的股票資料,大多都在百度股票資料上進行的爬取,爬取資料的網址為:https://gupiao.baidu.com/stock/
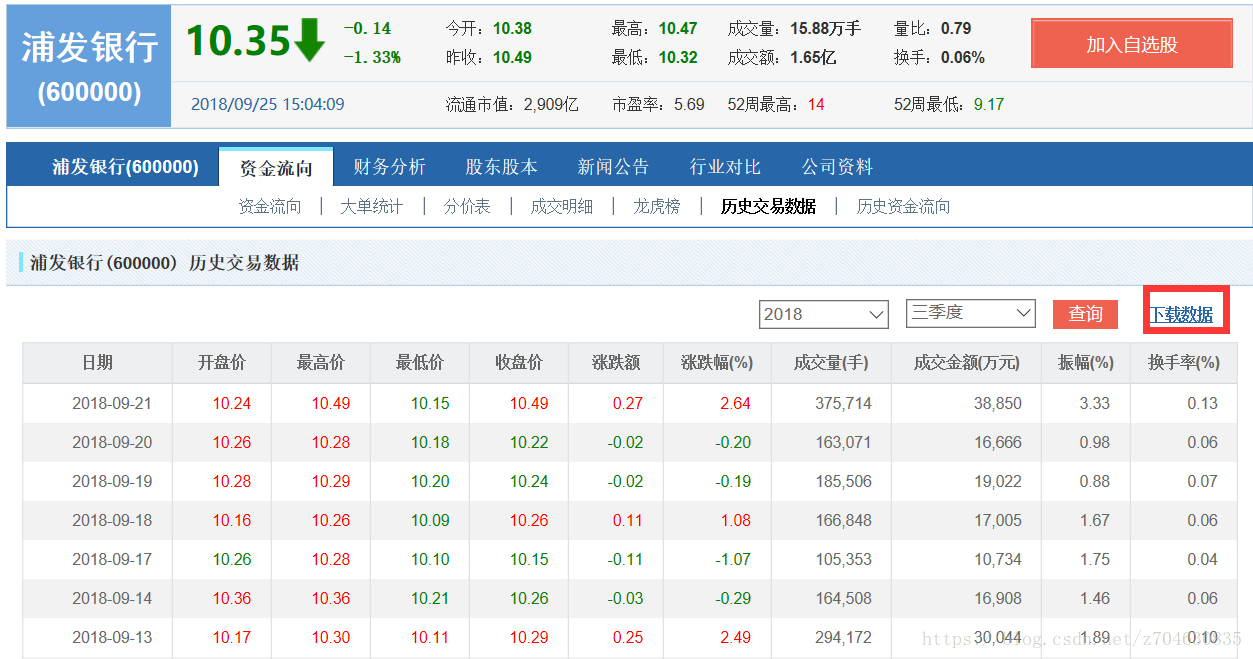
對於某一隻股票的所有歷史資料,這裡推薦網易財經,以600000浦發銀行為例,查詢600000,然後檢視其歷史資料即可,且歷史資料可以直接手動下載。其歷史資料的連結為: http://quotes.money.163.com/trade/lsjysj_600000.html#01b07
三、股票資料爬取的一點小技巧
股票資料的量非常大,這裡在爬取股票資料的時候,需要注意的就是反爬蟲的工作。參考了很多程式碼,總結出比較好的思路有兩個:
一是設定很多header,每次隨機抽取一個header進行資料訪問。下面給出這些header供參考。
import urllib import urllib.request import re import random user_agent = ["Mozilla/5.0 (Windows NT 10.0; WOW64)", 'Mozilla/5.0 (Windows NT 6.3; WOW64)', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11', 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko', 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)', 'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1', 'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3', 'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12', 'Opera/9.27 (Windows NT 5.2; U; zh-cn)', 'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0', 'Opera/8.0 (Macintosh; PPC Mac OS X; U; en)', 'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)', 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ', 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER', 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11'] url='http://quote.stockstar.com/stock/ranklist_a_3_1_'+str(page)+'.html' request=urllib.request.Request(url=url,headers={"User-Agent":random.choice(user_agent)})#隨機從user_agent列表中抽取一個元素
二是每抓一頁隨機休眠幾秒,數值可根據實際情況改動。可參考:
import time
time.sleep(random.randrange(1,4))四、爬取股票程式碼
試驗了很多程式碼,有兩個程式碼還不錯,能夠爬取出部分股票資料。下面直接給出相關程式碼:
import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockURL): html = getHTMLText(stockURL) soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a') for i in a: try: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) except: continue def getStockInfo(lst, stockURL, fpath): count = 0 for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html == "": continue infoDict = {} soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div', attrs={'class': 'stock-bets'}) name = stockInfo.find_all(attrs={'class': 'bets-name'})[0] infoDict.update({'股票名稱': name.text.split()[0]}) keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f: f.write(str(infoDict) + '\n') count = count + 1 print("\r當前進度: {:.2f}%".format(count * 100 / len(lst)), end="") except: count = count + 1 print("\r當前進度: {:.2f}%".format(count * 100 / len(lst)), end="") continue def main(): stock_list_url = 'http://quote.eastmoney.com/stocklist.html' stock_info_url = 'https://gupiao.baidu.com/stock/' output_file = 'D:/BaiduStockInfo.txt' slist = [] getStockList(slist, stock_list_url) getStockInfo(slist, stock_info_url, output_file) if __name__ == '__main__': mian()
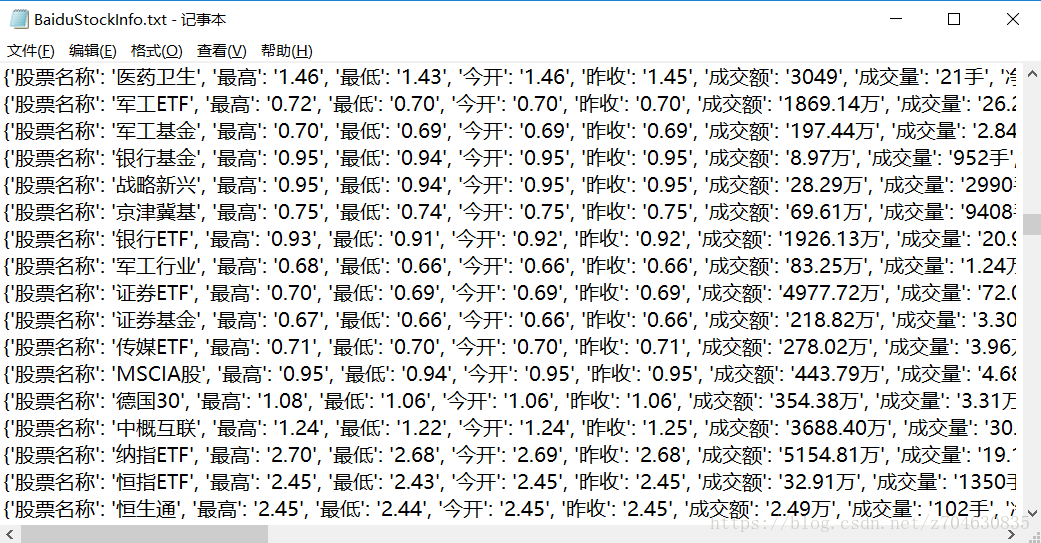
測試過上述程式碼,能夠下載部分股票資料的當日情況,但存在的問題是下載一陣之後就不再下載資料,且下載資料的效果並不理想,排版很亂。下面是爬取股票資料的結果:
另一個比較好的程式碼為:
import urllib
import urllib.request
import re
import random
import time
#抓取所需內容
user_agent = ["Mozilla/5.0 (Windows NT 10.0; WOW64)", 'Mozilla/5.0 (Windows NT 6.3; WOW64)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11']
stock_total=[] # 所有頁面的股票資料
for page in range(1,8): # 下載1-7頁的股票資料
url='http://quote.stockstar.com/stock/ranklist_a_3_1_'+str(page)+'.html'
request=urllib.request.Request(url=url,headers={"User-Agent":random.choice(user_agent)})#隨機從user_agent列表中抽取一個元素
try:
response=urllib.request.urlopen(request)
except urllib.error.HTTPError as e: #異常檢測
print('page=',page,'',e.code)
except urllib.error.URLError as e:
print('page=',page,'',e.reason)
content=response.read().decode('gbk') #讀取網頁內容
print('get page',page) #列印成功獲取的頁碼
pattern=re.compile('<tbody[\s\S]*</tbody>')
body=re.findall(pattern,str(content))
pattern=re.compile('>(.*?)<')
stock_page=re.findall(pattern,body[0]) #正則匹配
stock_total.extend(stock_page)
time.sleep(random.randrange(1,4)) #每抓一頁隨機休眠幾秒,數值可根據實際情況改動
#刪除空白字元
stock_last=stock_total[:] #stock_last為最終所要得到的股票資料
for data in stock_total:
if data=='':
stock_last.remove('')
#列印部分結果
print('程式碼','\t','簡稱',' ','\t','最新價','\t',' ','漲跌幅','\t',' ','漲跌額','\t',' ','5分鐘漲幅')
for i in range(0,len(stock_last),13): #原網頁有13列資料,所以步長為13
print(stock_last[i],'\t',stock_last[i+1],' ','\t',stock_last[i+2],' ','\t',stock_last[i+3],' ','\t',stock_last[i+4],' ','\t',stock_last[i+5])
該程式碼可以直接下載股票的相應資料,存在的問題也是隻能下載一部分資料。
目前關於如何下載一支股票的所有歷史資料,還在學習中。。。。。。