
大資料學習之路98-Zookeeper管理Kafka的OffSet
阿新 • • 發佈:2018-11-09
我們之前的OffSet都是交給broker自己管理的,現在我們希望自己管理。
我們可以通過zookeeper進行管理。
我們在程式中想要使用zookeeper,那麼就肯定會有api允許我們操作。
new ZKGroupTopicDirs()注意:這裡使用客戶端的時候導包為:
import org.I0Itec.zkclient.ZkClient
我們可以看到這個api需要兩個引數,
一個是group的id另一個就是topic主題
他返回的其實就是一個拼接的字串,我們可以看一下原始碼:

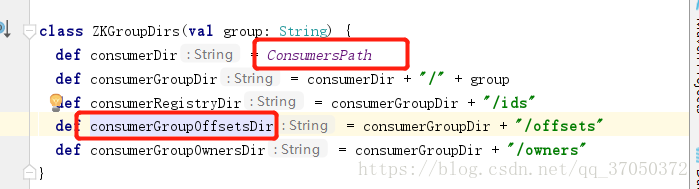
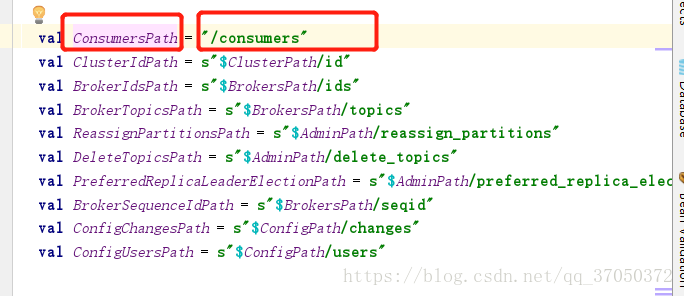
生成的目錄結構 * /customer/g100/offsets/wordcount
這裡拼接的字串是不包括分割槽的,因為這個分割槽是動態值。
/**
* 如果我們自己維護偏移量
* 問題:
* 1.程式在第一次啟動的時候,應該從什麼開始消費資料?earliest
* 2.程式如果不是第一次啟動的話,應該從什麼位置開始消費資料?
* 上一次自己維護的偏移量接著往後消費,比如上一次儲存的offset=88
*/那麼我們如何判斷是否是第一次連線呢?
我們可以去zookeeper目錄下看一下:

我們可以看到暫時consumer目錄下只有這兩個。
所以我們判斷程式是否第一次執行,我們只需要判斷這個目錄底下有沒有生成我們的新目錄即可。
我們這裡設定的groupId是g100
所以我們需要判斷的是
/customer/g100/offsets/wordcount下面有沒有孩子節點,如果有,說明之前維護過偏移量,如果沒有的話說明程式是第一次執行。
如果是之前啟動過則在該目錄下會有生成好的序列的分割槽號。
類似於這樣:
程式碼如下:
package com.test.sparkStreaming import kafka.utils.{ZKGroupTopicDirs, ZkUtils} import org.I0Itec.zkclient.ZkClient import org.apache.kafka.common.TopicPartition import org.apache.log4j.{Level, Logger} import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.kafka.common.serialization.StringDeserializer object KafkaDirect_ZK_Offset { def main(args: Array[String]): Unit = { Logger.getLogger("org.apache.spark").setLevel(Level.OFF) val conf: SparkConf = new SparkConf().setAppName("KafkaDirect_ZK_Offset").setMaster("local[*]") val ssc: StreamingContext = new StreamingContext(conf,Seconds(5)) val groupId = "g100" /** * kafka引數列表 */ val kafkaParams = Map[String,Object]( "bootstrap.servers" -> "marshal:9092,marshal01:9092,marshal02:9092,marshal03:9092,marshal04:9092,marshal05:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> groupId, "auto.offset.reset" -> "earliest", "enable.auto.commit" -> (false:java.lang.Boolean) ) val topic = "wordcount" val topics = Array(topic) /** * 如果我們自己維護偏移量 * 問題: * 1.程式在第一次啟動的時候,應該從什麼開始消費資料?earliest * 2.程式如果不是第一次啟動的話,應該從什麼位置開始消費資料? * 上一次自己維護的偏移量接著往後消費,比如上一次儲存的offset=88 */ val zKGroupTopicDirs: ZKGroupTopicDirs = new ZKGroupTopicDirs(groupId,topic) /** * 生成的目錄結構 * /customer/g1/offsets/wordcount */ val offsetDir: String = zKGroupTopicDirs.consumerOffsetDir //zk字串連線組 val zkGroups = "marshal:2181,marshal01:2181,marshal02:2181,marshal03:2181,marshal04:2181,marshal05:2181" //建立一個zkClient連線 val zkClient: ZkClient = new ZkClient(zkGroups) //子節點的數量 val childrenCount: Int = zkClient.countChildren(offsetDir) //子節點的數量>0就說明非第一次 val stream = if(childrenCount>0){ println("已經啟動過") //用來儲存我們已經讀取到的偏移量 var fromOffsets = Map[TopicPartition,Long]() (0 until childrenCount).foreach(partitionId => { val offset = zkClient.readData[String](offsetDir+s"/$partitionId") fromOffsets += (new TopicPartition(topic,partitionId) -> offset.toLong) }) KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Assign[String,String](fromOffsets.keys.toList,kafkaParams,fromOffsets) ) } else{ println("第一次啟動") KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String,String](topics,kafkaParams) ) } stream.foreachRDD( rdd => { //轉換rdd為Array[OffsetRange] val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges val maped: RDD[(String, String)] = rdd.map(record => (record.key,record.value)) //計算邏輯 maped.foreach(println) //自己儲存資料,自己管理 for(o <-offsetRanges){ //寫入到zookeeper,第二個引數為是否啟動安全 ZkUtils(zkClient,false).updatePersistentPath(offsetDir+"/"+o.partition,o.untilOffset.toString) } } ) ssc.start() ssc.awaitTermination() } }
第一次執行結果如下:


我們再看zookeeper的目錄:
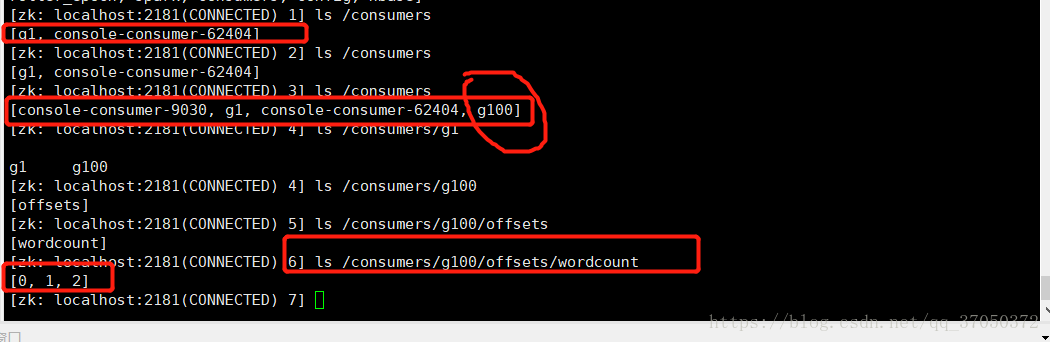
然後我們第二次執行,結果如下:

已經消費過的資料就不會再消費了。