
Hadoop2.x新特性:HA、Federation、快照
NameNode HA
(1) 基於NFS共享儲存解決方案
(2) 基於Qurom Journal Manager(QJM)解決方案
NameNode Federation
(1) 存在多個NameNode,每個NameNode分管一部分目錄
(2) NameNode共用DataNode
一、HDFS的新特性HA
(一) HDFS的HA機制
Hadoop 2.2.0 版本之前,NameNode是HDFS叢集的單點故障點,每一個叢集只有一個NameNode ,如果這個機器或者程序不可用,整個叢集就無法使用,直到重啟NameNode或者新重啟一個NameNode節點 。
(1)類似機器跌宕這樣的意外情況將導致叢集不可用,只有重啟NameNode之後才可使用。
(2) 計劃內的軟體或硬體升級(NameNode節點)將導致叢集在短時間範圍內不可用。
HDFS的高可用性(HA ,High Availability)就可以解決上述問題,通過提供選擇執行在同一叢集中的一個熱備用的 "主/備"兩個冗餘NameNode,允許在機器宕機或系統維護的時候,快速轉移到另一個NameNode。
(二) 典型的HA叢集
一個典型的HA叢集,兩個單獨的機器配置為NameNodes,在任何時候,一個NameNode處於活動狀態,另一個處於待機狀態,活動的NameNode負責處理叢集中所有客戶端的操作,待機時僅僅作為一個slave,保持足夠的狀態,如果有必要提供一個快速的故障轉移。
為了保持備用節點與活動節點狀態的同步,目前的實現需要兩個節點同時訪問一個共享儲存裝置(例如從NASNFS掛載)到一個目錄。
當活動節點對名稱空間進行任何修改,它將把修改記錄寫到共享目錄下的一個日誌檔案,備用節點會監聽這個目錄,當發現更改時,它會把修改內容同步到自己的名稱空間。備用節點在故障轉移時,它將保證已經讀取了所有共享目錄內的更改記錄,保證在發生故障前的狀態與活動節點保持完全一致。
為了提供快速的故障轉移,必須保證備用節點有最新的叢集中塊的位置資訊,為了達到這一點,Datanode節點需要配置兩個nameNode的位置,同時傳送塊的位置資訊和心跳資訊到兩個nameNode。
任何時候只有一個namenode處於活動狀態,管理員必須為共享儲存配置至少一個(fencing“規避”)方法。在宕機期間,如果不能確定之間的活動節點已經放棄活動狀態,fencing程序負責中斷以前的活動節點編輯儲存的共享訪問。這可以防止任何進一步的修改名稱空間,允許新的活動節點安全地進行故障轉移。
(三) HA架構
1、只有一個NameNode是Active的,並且只有這個ActiveNameNode能提供服務,改變NameNode。以後可以考慮讓StandbyNameNode提供讀服務。
2、提供手動Failover(故障切換),在升級過程中,Failover在NameNode-DataNode之間寫不變的情況下才能生效。
3、在之前的NameNode重新恢復之後,不能提供failback。
4、資料一致性比Failover更重要。
5、儘量少用特殊的硬體。
6、HA的設定和Failover都應該保證在兩者操作錯誤或者配置錯誤的時候,不得導致資料損壞。
7、NameNode的短期垃圾回收不應該觸發Failover。
8、DataNode會同時向NameNodeActive和NameNodeStandby彙報塊的資訊。NameNodeActive和NameNodeStandby通過NFS備份MetaData資訊到一個磁碟上面。
簡述 Hadoop HA 機制?(面試題)
答題思路從以下四大點,如下:HA 實現的兩個核心要點:
(1) 故障轉移的實現
(2) 共享儲存的實現
Hadoop HA 的兩個方面體現:
(3) NameNode HA
(4) ResourceManager HA
(1) 故障轉移的實現(也稱為NameNode 實現主備切換)
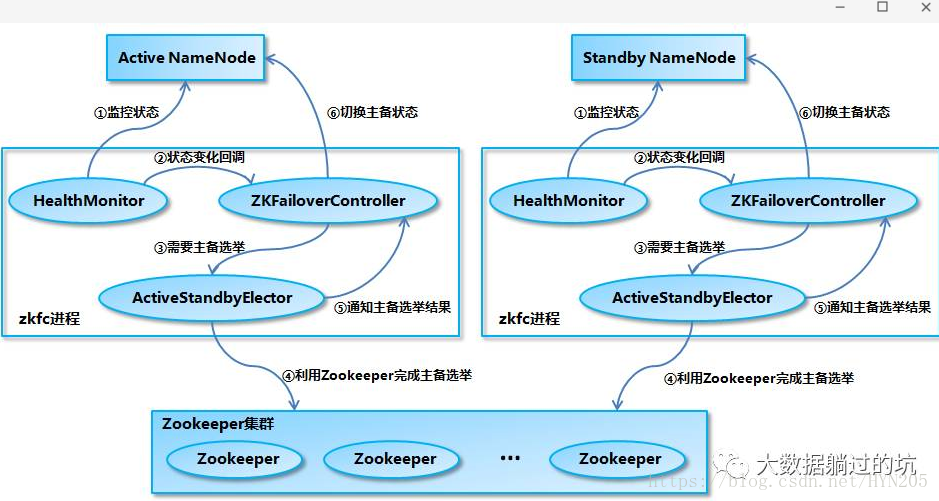
1、HealthMonitor 初始化完成之後會啟動內部的執行緒來定時呼叫對應 NameNode 的 HAServiceProtocol RPC 介面的方法,對 NameNode 的健康狀態進行檢測。
2、HealthMonitor 如果檢測到 NameNode 的健康狀態發生變化,會回撥 ZKFailoverController 註冊的相應方法進行處理。
3、如果 ZKFailoverController 判斷需要進行主備切換,會首先使用 ActiveStandbyElector 來進行自動的主備選舉。
4、ActiveStandbyElector 與 Zookeeper 進行互動完成自動的主備選舉。
5、ActiveStandbyElector 在主備選舉完成後,會回撥 ZKFailoverController 的相應方法來通知當前的 NameNode 成為主 NameNode 或備 NameNode。
6、ZKFailoverController 呼叫對應 NameNode 的 HAServiceProtocol RPC 介面的方法將 NameNode 轉換為 Active 狀態或 Standby 狀態。
(2) 共享儲存的實現(也稱為基於 QJM 的共享儲存系統的資料同步)
基於 QJM 的共享儲存系統主要用於儲存 EditLog,並不儲存 FSImage 檔案。 FSImage檔案還是在 NameNode 的本地磁碟上。 QJM 共享儲存的基本思想來自於 Paxos 演算法,採用多個稱為 JournalNode 的節點組成的 JournalNode 叢集來儲存 EditLog。每個 JournalNode 儲存同樣的 EditLog 副本。每次 NameNode 寫 EditLog 的時候,除了向本地磁碟寫入 EditLog 之外,也會並行地向 JournalNode 叢集之中的每一個 JournalNode 傳送寫請求,只要大多數 (majority)的 JournalNode 節點返回成功就認為向 JournalNode 叢集寫入 EditLog 成功。如果有 2N+1 臺JournalNode,那麼根據大多數的原則,最多可以容忍有 N 臺 JournalNode 節點掛掉。
(3) NameNode HA
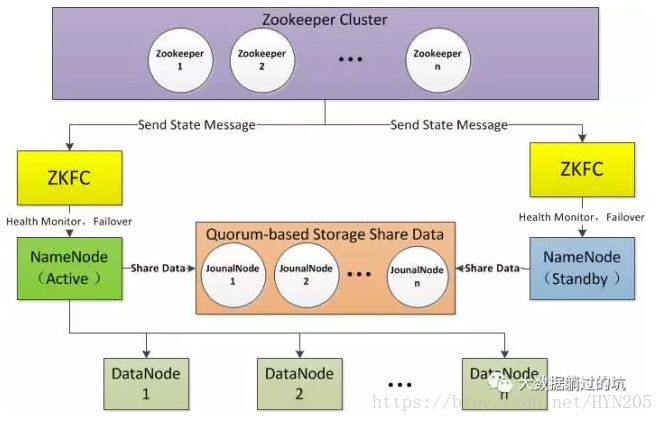
使用Active NameNode,Standby NameNode 兩個節點可以解決單點問題,兩個節點通過JounalNode共享狀態,通過ZKFC 選舉Active ,監控狀態,自動備份。
1)Active NameNode
接受client的RPC請求並處理,同時寫自己的Editlog和共享儲存上的Editlog,接收DataNode的Block report, block location updates和heartbeat。
2)Standby NameNode
同樣會接到來自DataNode的Block report, block location updates和heartbeat,同時會從共享儲存的Editlog上讀取並執行這些log操作,保持自己NameNode中的元資料(Namespcae information + Block locations map)和Active NameNode中的元資料是同步的。所以說Standby模式的NameNode是一個熱備(Hot Standby NameNode),一旦切換成Active模式,馬上就可以提供NameNode服務。
3)JounalNode
用於Active NameNode , Standby NameNode 同步資料,本身由一組JounnalNode節點組成,該組節點奇數個。
4)ZKFC
監控NameNode程序,自動備份。
(4) ResourceManager HA

由一對Active,Standby結點構成,通過RMStateStore儲存內部資料和主要應用的資料及標記。目前支援的可替代的RMStateStore實現有:基於記憶體的MemoryRMStateStore,基於檔案系統的FileSystemRMStateStore,及基於zookeeper的ZKRMStateStore。 ResourceManager HA的架構模式同NameNode HA的架構模式基本一致,資料共享由RMStateStore,而ZKFC成為 ResourceManager程序的一個服務,非獨立存在。
二、HDFS的新特性Federation
HDFS Federation使用了多個獨立的Namenode/namespace來使得HDFS的命名服務能夠水平擴充套件。在HDFS Federation中的Namenode之間是聯盟關係,他們之間相互獨立且不需要相互協調。HDFS Federation中的Namenode提供了提供了名稱空間和塊管理功能。HDFS Federation中的datanode被所有的Namenode用作公共儲存塊的地方。每一個datanode都會向所在叢集中所有的Namenode註冊,並且會週期性的傳送心跳和塊資訊報告,同時處理來自Namenode的指令。
Federation HDFS與當前HDFS的比較
當前HDFS只有一個名稱空間(Namespace),它使用全部的塊。而Federation HDFS中有多個獨立的名稱空間(Namespace),並且每一個名稱空間使用一個塊池(block pool)。
當前HDFS中只有一組塊。而Federation HDFS中有多組獨立的塊。塊池(block pool)就是屬於同一個名稱空間的一組塊。
當前HDFS由一個Namenode和一組datanode組成。而Federation HDFS由多個Namenode和一組datanode,每一個datanode會為多個塊池(block pool)儲存塊。
1.Block Pool(塊池)
所謂Block pool(塊池)就是屬於單個名稱空間的一組block(塊)。每一個datanode為所有的block pool儲存塊。Datanode是一個物理概念,而block pool是一個重新將block劃分的邏輯概念。同一個datanode中可以存著屬於多個block pool的多個塊。Block pool允許一個名稱空間在不通知其他名稱空間的情況下為一個新的block建立Block ID。同時,一個Namenode失效不會影響其下的datanode為其他Namenode的服務。當datanode與Namenode建立聯絡並開始會話後自動建立Block pool。每個block都有一個唯一的標識,這個標識我們稱之為擴充套件的塊ID(Extended Block ID)= BlockID+BlockID。這個擴充套件的塊ID在HDFS叢集之間都是唯一的,這為以後叢集歸併創造了條件。
Datanode中的資料結構都通過塊池ID(BlockPoolID)索引,即datanode中的BlockMap,storage等都通過BPID索引。在HDFS中,所有的更新、回滾都是以Namenode和BlockPool為單元發生的。即同一HDFS Federation中不同的Namenode/BlockPool之間沒有什麼關係。Hadoop V0.23版本中Block Pool的管理功能依然放在了Namenode中,將來的版本中會將Block Pool的管理功能移動的新的功能節點中。
2.Datanode的改進
在datanode中,對應於每個Namnode都有一條相應的執行緒。每個datanode會去每一個Namenode註冊,並且週期性的給所有的Namenode傳送心跳及datanode的使用報告。Datanode還會給Namenode傳送其所在的block pool的block report(塊報告)。由於有多個Namenode同時存在,因此任何一個Namenode都可以隨時動態加入、刪除和更新。
3.Federation中的其他方面的改進
提供了工具,對於Namenode的初始化和退役的監控和管理。允許在datanode級別或者block pool級別的負載均衡。Datanode的後臺守護程序,為Federation所做的磁碟和目錄掃描。提供了顯示Namenode的Block pool的使用狀態的Web UI。還提供了對全部叢集儲存使用狀態的UI展示。在Web UI中列出了所有的Namenode及其細節,如Namenode-BlockPoolID和儲存的使用狀態,失去聯絡的、活的和死的塊資訊。還有前往各個Namenode Web UI的連結。Datanode退役狀態的展示。
4.多名稱空間的管理問題
在一個叢集中需要唯一的名稱空間還是多個名稱空間,核心問題名稱空間中資料的共享和訪問的問題。使用全域性唯一的名稱空間是解決資料共享和訪問的一種方法。在多名稱空間下,我們還可以使用Client Side Mount Table方式做到資料共享和訪問。
5.Namespace Volume(名稱空間卷)
一個Namespace和它的Block Pool合在一起稱作Namespace Volume。Namespace Volume是一個獨立完整的管理單元。當一個Namenode/Namespace被刪除,與之相對應的Block Pool也也被刪除。在升級時每一個Namespace Volume也會整體作為一個單元。
6.ClusterID
在HDFS Federation中添加了Cluster ID用來區分叢集中的每個節點。當格式化一個Namenode時,這個ClusterID會自動生成或者手動提供。在格式化同一叢集中其他Namenode時會用到這個ClusterID。
7.HDFS Federation對老版本的HDFS是相容的
這種相容性可以使得已有的Namenode配置不需要任何改變繼續工作。
三、HDFS的新特性快照
在2.x終於實現了快照。設定一個目錄為可快照:
hdfs dfsadmin -allowSnapshot <path>
取消目錄可快照:
hdfs dfsadmin -disallowSnapshot <path>
生成快照:
hdfs dfs -createSnapshot <path> [<snapshotName>]
刪除快照:
hdfs dfs -deleteSnapshot <path> <snapshotName>
快照位置
可快照目錄下的snapshot子目錄
列出所有可快照目錄:
hdfs lsSnapshottableDir
比較快照之間的差異:
hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot>