
【CPU微架構設計】分散式多埠(4寫2讀)暫存器堆設計
暫存器堆(Register File)是微處理的關鍵部件之一。暫存器堆往往具有多個讀寫埠,其中寫埠往往與多個處理單元相對應。傳統的方法是使用集中式暫存器堆,即一個集中式暫存器堆匹配N個處理單元。隨著埠數量的增加,集中式暫存器堆的功耗、面積、時序均會呈冪增長,進而可能降低處理器總體效能。
下圖所示為傳統的集中式暫存器堆結構:

本文討論一種基於分佈儲存和麵積與時序互換原則的多埠暫存器堆設計,我們暫時稱之為“分散式暫存器堆”。該種暫存器從埠使用上,仍與集中式暫存器堆完全相容,但該暫存器堆使用多個暫存器簇和塊分散式地儲存運算元。當並行寫入時,各暫存器簇分散式地儲存寫入結果;當讀出時,由相應的仲裁演算法在多個暫存器簇的結果中選取確定的一個簇作為最終輸出。圖二顯示了這種分散式暫存器堆的邏輯結構。
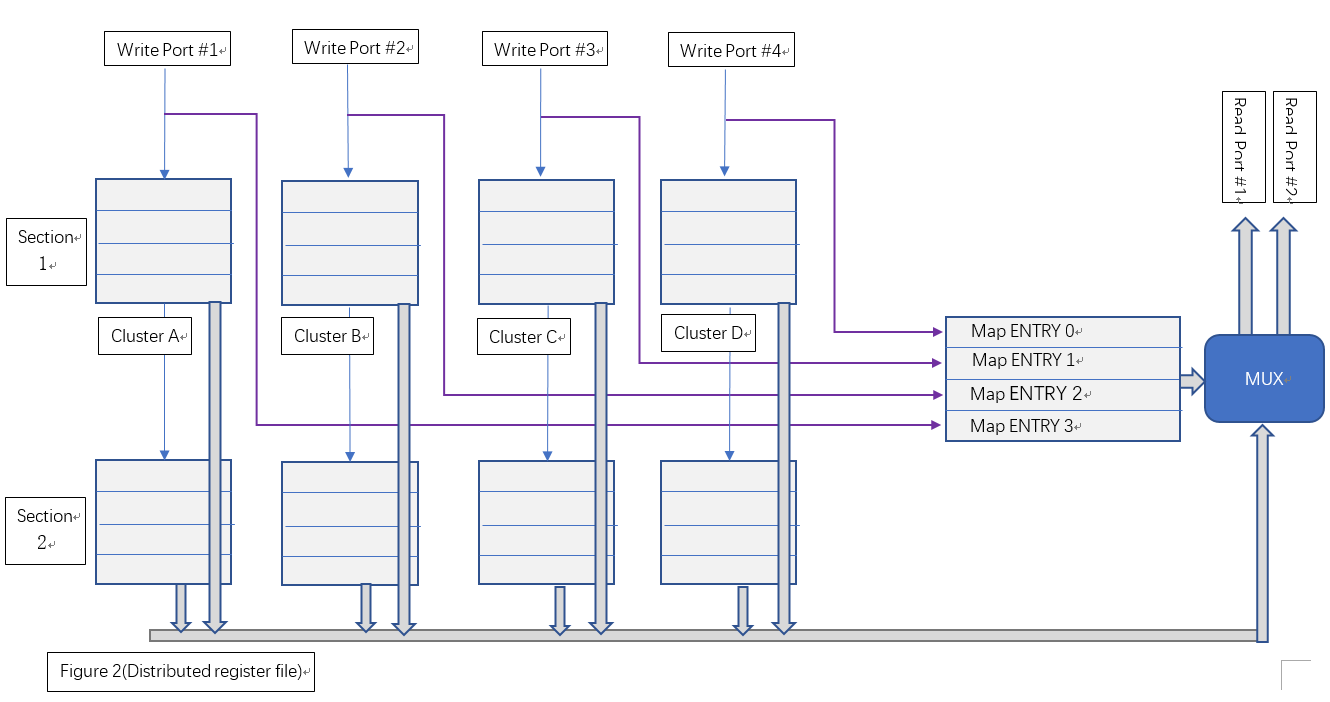
該結構主要由區塊(Section)和簇(Cluster)兩個維度組織暫存器:
(1)、從Section層面看,Section 1和Section 2是兩個完全相同的組成結構(相當於邏輯的複製),同時兩個Section中暫存器所持有的運算元也完全相同。一個Section只能處理一個讀埠的操作。Section1負責處理讀埠#1,而Section2負責處理讀埠#2。
(2)、從Cluster層面看,Cluster A、B、C、D是幾個分別獨立的集中式暫存器堆,其具體結構可等價為一個雙口RAM。寫入時,Clusters分別獨立地寫入各自要求的地址。讀出時,各Cluster從相同的讀出地址讀出各自的資料,最後將4個數據送到MUX進行最後的仲裁。
綜上,單個Section負責單個讀埠操作,單個Cluster負責單個寫埠操作。
分散式暫存器堆的設計關鍵在於仲裁排程演算法。由於一個Section只負責處理一個讀埠的操作,我們首先從單個Section維度考慮。雖然單個週期內需要同時處理4個寫埠,但讀埠是唯一的。事先記錄每個寫埠的地址所對應的Cluster編號,在讀出時,通過讀出地址反向獲取對應的Cluster,進而從該Cluster取出最終結果。
其次再考慮多個讀埠並行操作。考慮複製兩個相同的Section邏輯,並將所有寫埠並聯起來,則可以保證兩個Section所持有的運算元完全相同。對兩個Section同時進行讀操作,這樣便實現了並行地讀出兩個不同地址的資料。
接下來設計兩個關鍵部件:Cluster暫存器堆和資料仲裁器。
一、Cluster暫存器的設計
上文已經提到過,Cluster暫存器可等價為雙埠RAM。關於DPRAM的具體結構可參考相關資料,本文不再贅述。DPRAM容量根據最為通用的配置,採用32x32bit設計,可通過例化引數設定地址匯流排和資料匯流排的寬度。利用Verilog描述一個同步時鐘DPRAM的原始碼如下:


1 module dpram_sclk 2 #( 3 parameter ADDR_WIDTH = 32, 4 parameter DATA_WIDTH = 32, 5 parameter CLEAR_ON_INIT = 1, // Whether to rest the RAM while initialization (for simulation only) 6 parameter ENABLE_BYPASS = 1 // Whether enable data bypass 7 ) 8 (/*AUTOARG*/ 9 // Outputs 10 dout, 11 // Inputs 12 clk, rst, raddr, re, waddr, we, din 13 ); 14 15 // Port List 16 input clk; 17 input rst; 18 input [ADDR_WIDTH-1:0] raddr; 19 input re; 20 input [ADDR_WIDTH-1:0] waddr; 21 input we; 22 input [DATA_WIDTH-1:0] din; 23 output [DATA_WIDTH-1:0] dout; 24 25 reg [DATA_WIDTH-1:0] mem[(1<<ADDR_WIDTH)-1:0]; 26 reg [DATA_WIDTH-1:0] rdata; 27 reg re_r; 28 wire [DATA_WIDTH-1:0] dout_w; 29 30 generate 31 if(CLEAR_ON_INIT) begin :clear_on_init 32 integer entry; 33 initial begin 34 for(entry=0; entry < (1<<ADDR_WIDTH); entry=entry+1) // reset 35 mem[entry] = {DATA_WIDTH{1'b0}}; 36 end 37 end 38 endgenerate 39 40 // bypass control 41 generate 42 if (ENABLE_BYPASS) begin : bypass_gen 43 reg [DATA_WIDTH-1:0] din_r; 44 reg bypass; 45 46 assign dout_w = bypass ? din_r : rdata; 47 48 always @(posedge clk) 49 if (re) din_r <= din; 50 51 always @(posedge clk) 52 if (waddr == raddr && we && re) 53 bypass <= 1; 54 else 55 bypass <= 0; 56 end else begin 57 assign dout_w = rdata; 58 end 59 endgenerate 60 61 // R/W logic 62 always @(posedge clk) 63 re_r <= rst ? 1'b0 : re; 64 65 assign dout = re_r ? dout_w : {DATA_WIDTH{1'b0}}; 66 67 always @(posedge clk) begin 68 if (we) 69 mem[waddr] <= din; 70 if (re) 71 rdata <= mem[raddr]; 72 end 73 74 endmodulemodule dpram_sclk
值得注意的是,實現中加入了資料旁通機制,保證當發生同時讀寫且地址相同時,寫入資料能在單個操作週期內送達讀埠。
二、資料仲裁器的設計
資料仲裁器的核心是維護一個寫入地址→Cluster編號的對映表。假設分散式暫存器堆總共有32個暫存器(以5bit地址匯流排定址),則我們需要一個表項數為32的列表,儲存每個地址對應的Cluster編號。Verilog描述如下:
reg [1:0] sel_map[(1<<ADDR_WIDTH)-1:0];
對於每個寫埠,在寫操作週期維護對映表,記錄下寫入地址對應的Cluster,實現如下:
1 // Maintain the selection map 2 always @(posedge clk) begin 3 if (we1) 4 sel_map[waddr1] <= 2'd0; 5 if (we2) 6 sel_map[waddr2] <= 2'd1; 7 if (we3) 8 sel_map[waddr3] <= 2'd2; 9 if (we4) 10 sel_map[waddr4] <= 2'd3; 11 end
對於讀埠,先從對映表獲取實際儲存目標運算元的Cluster,然後利用多路複用器選取其輸出,作為該Section的最終讀取結果。
1 // mux 2 assign dout = sel_map[raddr]==2'd0 ? dout0 : 3 sel_map[raddr]==2'd1 ? dout1 : 4 sel_map[raddr]==2'd2 ? dout2 : 5 sel_map[raddr]==2'd3 ? dout3 : 6 {DATA_WIDTH{1'b0}}; /* never got this */
由此,我們可以得出單個Section的完整設計:
1 module cpram_sclk_4w1r #( 2 parameter ADDR_WIDTH = 5, 3 parameter DATA_WIDTH = 32, 4 parameter CLEAR_ON_INIT = 1, // Whether to rest the RAM while initialization (for simulation only) 5 parameter ENABLE_BYPASS = 1 // Whether enable data bypass 6 ) 7 (/*AUTOARG*/ 8 // Outputs 9 rdata, 10 // Inputs 11 clk, rst, we1, waddr1, wdata1, we2, waddr2, wdata2, we3, waddr3, 12 wdata3, we4, waddr4, wdata4, re, raddr 13 ); 14 15 // Ports 16 input clk; 17 input rst; 18 input we1; 19 input [ADDR_WIDTH-1:0] waddr1; 20 input [DATA_WIDTH-1:0] wdata1; 21 input we2; 22 input [ADDR_WIDTH-1:0] waddr2; 23 input [DATA_WIDTH-1:0] wdata2; 24 input we3; 25 input [ADDR_WIDTH-1:0] waddr3; 26 input [DATA_WIDTH-1:0] wdata3; 27 input we4; 28 input [ADDR_WIDTH-1:0] waddr4; 29 input [DATA_WIDTH-1:0] wdata4; 30 input re; 31 input [ADDR_WIDTH-1:0] raddr; 32 output [DATA_WIDTH-1:0] rdata; 33 34 // Internals 35 wire [DATA_WIDTH-1:0] dout; 36 wire [DATA_WIDTH-1:0] dout0; 37 wire [DATA_WIDTH-1:0] dout1; 38 wire [DATA_WIDTH-1:0] dout2; 39 wire [DATA_WIDTH-1:0] dout3; 40 reg [1:0] sel_map[(1<<ADDR_WIDTH)-1:0]; 41 42 // instance of sync dpram #1 for Cluster A 43 dpram_sclk 44 #( 45 .ADDR_WIDTH (ADDR_WIDTH), 46 .DATA_WIDTH (DATA_WIDTH), 47 .CLEAR_ON_INIT (CLEAR_ON_INIT), 48 .ENABLE_BYPASS (ENABLE_BYPASS) 49 ) 50 mem0 51 ( 52 .clk (clk), 53 .rst (rst), 54 .dout (dout0), 55 .raddr (raddr), 56 .re (re), 57 .waddr (waddr1), 58 .we (we1), 59 .din (wdata1) 60 ); 61 // instance of sync dpram #2 for Cluster B 62 dpram_sclk 63 #( 64 .ADDR_WIDTH (ADDR_WIDTH), 65 .DATA_WIDTH (DATA_WIDTH), 66 .CLEAR_ON_INIT (CLEAR_ON_INIT), 67 .ENABLE_BYPASS (ENABLE_BYPASS) 68 ) 69 mem1 70 ( 71 .clk (clk), 72 .rst (rst), 73 .dout (dout2), 74 .raddr (raddr), 75 .re (re), 76 .waddr (waddr2), 77 .we (we2), 78 .din (wdata2) 79 ); 80 // instance of sync dpram #3 for Cluster C 81 dpram_sclk 82 #( 83 .ADDR_WIDTH (ADDR_WIDTH), 84 .DATA_WIDTH (DATA_WIDTH), 85 .CLEAR_ON_INIT (CLEAR_ON_INIT), 86 .ENABLE_BYPASS (ENABLE_BYPASS) 87 ) 88 mem2 89 ( 90 .clk (clk), 91 .rst (rst), 92 .dout (dout3), 93 .raddr (raddr), 94 .re (re), 95 .waddr (waddr3), 96 .we (we3), 97 .din (wdata3) 98 ); 99 // instance of sync dpram #4 for Cluster D 100 dpram_sclk 101 #( 102 .ADDR_WIDTH (ADDR_WIDTH), 103 .DATA_WIDTH (DATA_WIDTH), 104 .CLEAR_ON_INIT (CLEAR_ON_INIT), 105 .ENABLE_BYPASS (ENABLE_BYPASS) 106 ) 107 mem3 108 ( 109 .clk (clk), 110 .rst (rst), 111 .dout (dout3), 112 .raddr (raddr), 113 .re (re), 114 .waddr (waddr4), 115 .we (we4), 116 .din (wdata4) 117 ); 118 119 // mux 120 assign dout = sel_map[raddr]==2'd0 ? dout0 : 121 sel_map[raddr]==2'd1 ? dout1 : 122 sel_map[raddr]==2'd2 ? dout2 : 123 sel_map[raddr]==2'd3 ? dout3 : 124 {DATA_WIDTH{1'b0}}; /* never got this */ 125 126 // Read output with/without bypass controlling 127 generate 128 if (ENABLE_BYPASS) begin : bypass_gen 129 assign rdata = 130 (we1 && (raddr==waddr1)) ? wdata1 : 131 (we2 && (raddr==waddr2)) ? wdata2 : 132 (we3 && (raddr==waddr3)) ? wdata3 : 133 (we4 && (raddr==waddr4)) ? wdata4 : 134 dout; 135 end else begin 136 assign rdata = dout; 137 end 138 endgenerate 139 140 // Maintain the selection map 141 always @(posedge clk) begin 142 if (we1) 143 sel_map[waddr1] <= 2'd0; 144 if (we2) 145 sel_map[waddr2] <= 2'd1; 146 if (we3) 147 sel_map[waddr3] <= 2'd2; 148 if (we4) 149 sel_map[waddr4] <= 2'd3; 150 end 151 endmodule
值得說明的是:上述實現仍然需要考慮四個寫埠與一個讀埠的資料旁通路徑。通過例化引數ENABLE_BYPASS可以指定是否使用資料旁通邏輯。
將兩個Section寫埠並聯,並分別引出其讀埠,即構成了一個4w 2r暫存器堆。
總結
本文討論的資料的分佈儲存方法和基於面積換時序的邏輯複製方法,在集中儲存式暫存器堆的優化中取得了較好的效果。但該結構缺點也十分明顯:首先,對集中暫存器堆的複製無疑增加了面積和功耗,其次,隨著寫埠數的增加,仲裁邏輯的規模也隨之增長,這將導致資料路徑延遲增加,進而降低暫存器堆時鐘工作頻率。
相比於ASIC設計,本結構更適合於FPGA驗證。理由如下:在FPGA中,暫存器是非常有限的資源。若直接實現一定規模的RAM結構,則需要大量佔用暫存器資源。為此,FPGA在硬體上集成了RAM Block資源。這些RAM Blocks多可配置為雙埠模式,但對於更復雜的埠配置(如本例的4w2r),則只能間接實現。
本設計完全採用RAM Blocks實現多埠暫存器堆。因為FPGA綜合工具在分析verilog原始碼時,將自動識別出我們所採用的DPRAM,轉而使用RAM Block資源,避免佔用暫存器資源,為設計的其它部分留出更多可用的暫存器資源。同時,這將避免使用LUT實現複雜的RAM單元定址和控制邏輯,從而優化時序。
2018 10.20
===================================================
本博文僅供參考,難免有疏漏之處,歡迎提出寶貴意見。